







 CLOUD
CLOUD
CLOUD
CLOUD
CLOUD
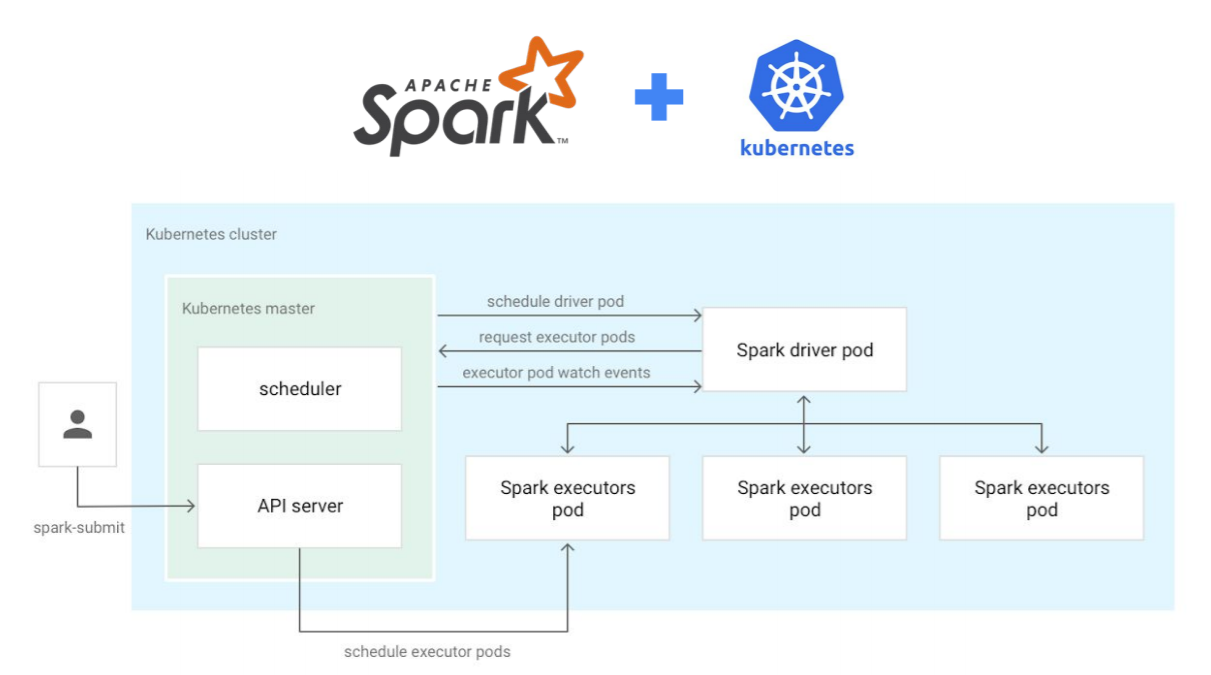
Google LLC is aiming to make it easier for its cloud customers to deploy and run open-source software projects such as Apache Spark via a new version, released today, of its Cloud Dataproc service running on Kubernetes.
Cloud Dataproc is a four-year-old service that allows users take advantage of open-source data tools such as Apache Hadoop and Spark for batch processing, querying, streaming and machine learning tasks.
It provides open-source data and analytics processing capabilities for data engineers and data scientists who need to process information and train models faster at scale. It comes with automation tools that allow clusters to be created quickly, along with the ability to save money by turning clusters off when they’re not needed.
Kubernetes is a popular open-source software framework that’s used to manage large clusters of containers. Containers in turn are used to host the components of modern applications that can run on any infrastructure platform.
By combining Cloud Dataproc with Kubernetes, Google is enabling data scientists to unify resource management, isolate jobs and build resilient infrastructures across any environment, the company said in an announcement. Their open-source workloads also become much more portable.
“The overall idea Google has with its cloud services is to combine the best of Google Cloud and open source,” James Malone, Google’s product manager for managed services on open source software, told SiliconANGLE in an interview.
Malone explained that many customers face challenges in running open source software as it requires significant expertise, not just with the bewildering array of components it’s made of, but with the entire ecosystem.
“The open-source stack is very complicated,” Malone said. “Dataproc is the first managed service to take these open-source components and make them work on Kubernetes.”
Open-source jobs therefore become much simpler on Cloud Dataproc on Kubernetes. The service does away with the need to work with two separate cluster management interfaces to manage open source components, for example.
“Using Dataproc’s new capabilities, Google will give you one central view that can span both cluster management systems,” Google explained in its pitch. “Supporting both YARN and Kubernetes will give enterprises the flexibility they need to modernize certain hybrid workloads while continuing to monitor YARN-based workloads.”
The other main benefit is that users can containerize and isolate open-source software jobs on Kubernetes. This means their machine learning models and extract, transact and load pipelines can be moved from development to production without any compatibility problems. It also means customers can stop worrying about being locked in to a single environment.
“Moving to Kubernetes prevents lock-in,” Malone said. “So [customers] take jobs and run them on Amazon Elastic MapReduce for example. It’s easier to do with Kubernetes because containers are highly portable.”
Moreover, Cloud Dataproc on Kubernetes provides what Google calls a “self-healing environment” where infrastructure management tasks such as sizing and building clusters, manipulating Docker files and network configuration are all automated.
Cloud Dataproc on Kubernetes is currently available as an early “alpha” preview. At present it only works with Apache Spark but Google is planning to add more open source software projects, including Apache Flink, in the future.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





