















 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Database startup InfluxData Inc. is adding new functions to its platform today that enable users to collect, process and store time-series data in the InfluxDB Cloud more rapidly.
InfluxDB Native Collectors is a new feature that enables developers building with InfluxDB Cloud to subscribe to, process, transform and store real-time data from messaging and other public and private brokers and queues with a single click, the company said. It’s compatible with the MQ Telemetry Transport publish-subscribe network protocol, and provides what the company says is now the fastest way to get data from third-party brokers without adding any new software or code.
InfluxDB is the company’s flagship platform. It’s a specialized time-series database specifically designed to handle information that’s processed chronologically. For instance, it’s used to record the heat readings from industrial temperature sensors, which have to be arranged in the exact order they’re created together with a precise timestamp, so users can track how the heat in a machine fluctuates over time. This kind of context is also relevant for other applications, such as performance monitoring.
InfluxDB serves as the foundation for storing and analyzing this kind of chronological data. Notably, the database is said to be simple to deploy, yet capable of high performance, storing millions of data operations per second.
The company explains that time-series data can come from many different and widely distributed sources. To make sense of this data, it needs to be consolidated in a central location. The difficulty for developers is that creating the pipelines from these data sources to the database can be an incredibly complex job, involving lots of customizations to get them right. In addition, some systems might require an intermediary layer to transfer and transform data coming from external sources.
With InfluxDB Native Collectors, the creation of these data pipelines is automated. It removes the need for an intermediary layer, making it possible for cloud-based data sources to connect directly to InfluxDB Cloud. This means time-series data can be collected, transformed and stored on the fly, without writing any new code.
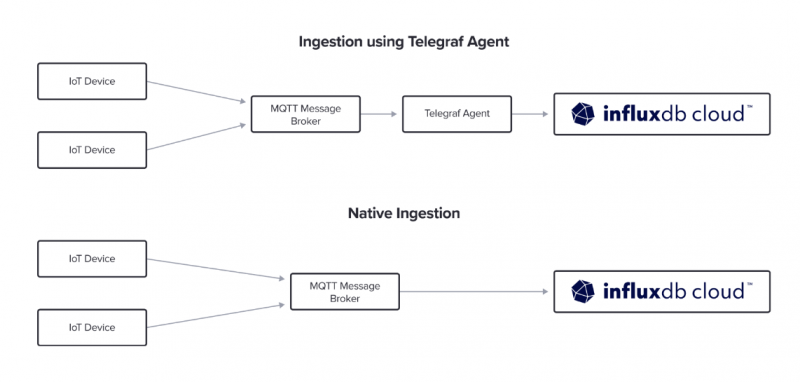
Once the data is collected, it can then be contextualized across different architectures to enhance application performance and security, the company said. Further, InfluxDB Native Collectors come with tools to enrich, format, filter and process data before it lands in InfluxDB Cloud, helping reduce storage costs.
The company said its first Native Collector for MQTT-based data is available now, with additional collectors for Apache Kafka and the Advanced Message Queuing Protocol to be released later this year.
“With Native Collectors, we’re expediting device to cloud data transfers so developers can focus on building and scaling applications with their time-series data,” said InfluxDB Vice President of Products Rick Spencer. “These updates enable InfluxDB Cloud to become a serverless consumer of data through easily configured topic subscriptions, greatly simplifying time-series data pipelines and applications alike.”
InfluxData Chief Revenue Officer Arwa Kaddoura and Chief Marketing Officer Brian Mullen stopped by theCUBE, SiliconANGLE’s mobile livestreaming studio, at last year’s AWS re:Invent, where they discussed the multitude of ways in which companies are using InfluxDB to unlock value from their time-series data:
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





