This high-level definition of a data platform is meant to help frame conversations about the category and compare vendors and their place in it. The definition itself is a moving target since the technology is evolving so fast. And different vendors want to define the platform differently. If you take away only one paragraph, I recommend the strategic positioning.
Strategic positioning
Data platforms are the new development tool for building enterprise applications (Figure 1). Data represents how the business works and captures its history and current state. With artificial intelligence, data predicts a business’s future state. Increasingly, changes in operational data, not humans interacting with a user interface, drive applications. In addition, as more and more application logic is embodied in AI models, an enterprise’s data actually sets the design-time application logic itself by “programming” the AI at training time.
So data platform vendors will control how mission-critical enterprise applications get built. As a result, data platforms’ capabilities will determine the very capabilities of those enterprise applications themselves.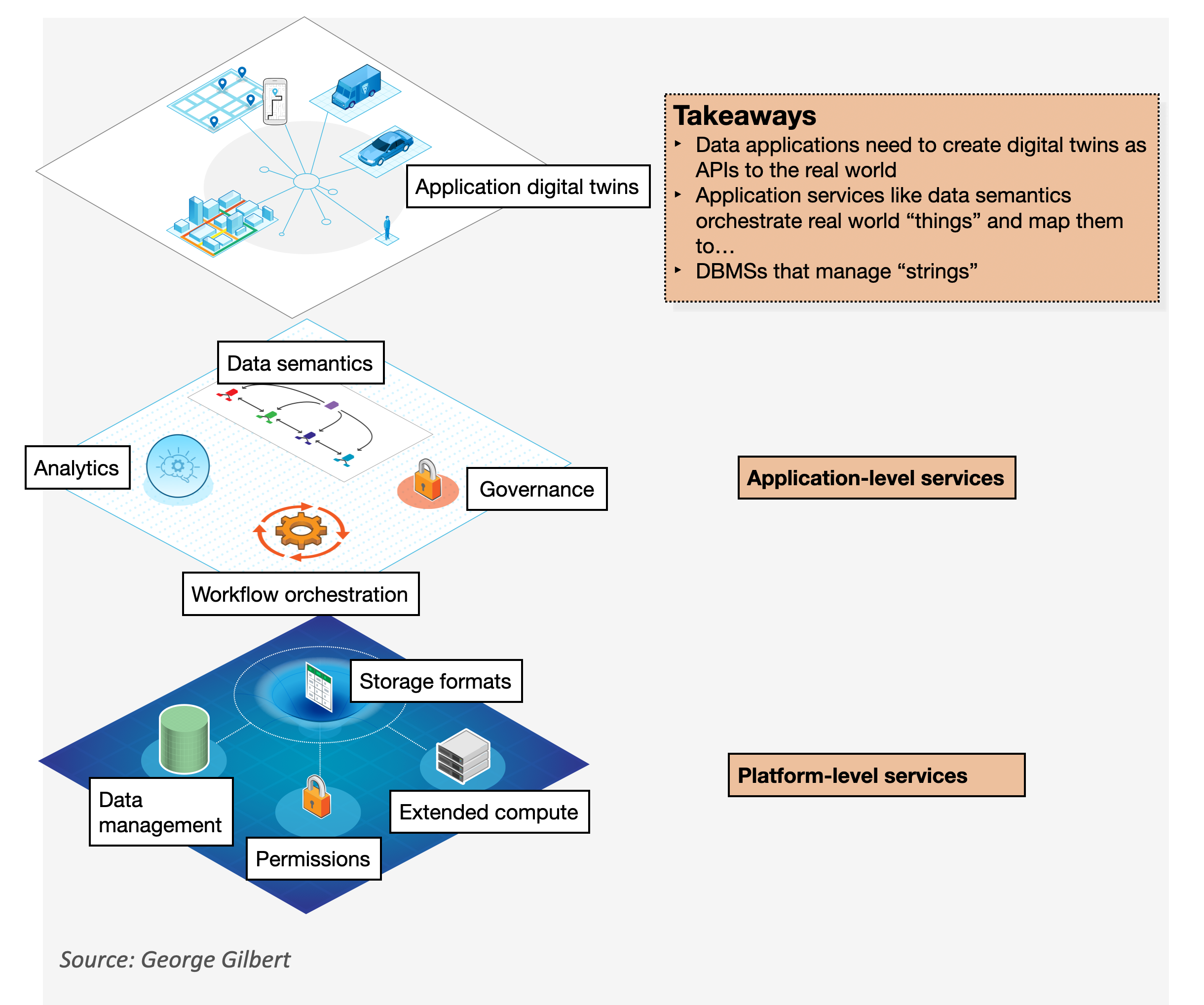
Figure 1: The emerging stack for applications built on data platforms.
Platform-level services: the new infrastructure layer
The platform services replace what was the operating system’s role in abstracting the underlying hardware. In that traditional platform, hardware abstraction hid the particulars of compute, networking and storage underneath application programming interfaces for scheduling, memory management, persistent storage and the like.
Data platforms, by contrast, abstract things in the real world through data that describes their behavior and operation. So the relevant services include storing the data in accessible formats, databases for accessing and updating it, an API for general-purpose programmatic access, and governance services to control access. In this section, we use Snowflake and Databricks as examples of the most popular data platforms from leading vendors. The other leading data platforms belong to the hyperscale vendors.
We envision four components of what we refer to as platform services as follows:
- Storage format: Everyone agrees on the value of an open storage format — at least for analytical data. Whether it is Iceberg (Snowflake and its ecosystem) or Delta Tables (Databricks, Apache Spark and Microsoft) or Hudi, or all three (Databricks Uniform Format), an open format means an ecosystem of tools can read and write the data. Ecosystem access is important because some tools, like the data science toolchain, typically don’t know how to talk to a SQL DBMS. The data itself has low-level technical definitions so one could consider it as “strings,” as opposed to higher-level “things” that are meaningful to applications and end-users.
- DBMS: The initial use cases for data platforms were pipelines that took raw operational data and refined it for access by business intelligence dashboards or for data scientists training AI and machine learning models. Snowflake was really strong in dashboards because of its interactive responsiveness. Databricks has been trying to catch up with Databricks SQL, which is five years less mature. However, it is trying to close the performance gap by training machine learning models on historical data about query performance in order to make better real-time optimizations. Snowflake is using its lead to redefine data management. Their DBMS can integrate multiple data models starting with transactions and adding vector, graph, streaming and others. The idea is that customers can manage their entire data estate on one shared service, helping to eliminate silos. Customers and independent software vendors can build data-driven applications that operationalize the analytics on Snowflake. In Databricks, they have to embed their analytics in an external application to inform or automate a decision. This distinction didn’t seem to come through following both conferences.
- Lakehouse/SDK access: A non-SQL API allows any tool or service to access data. Spark has a separate engine and DataFrame API for accessing data. This engine is lower-cost and more efficient for batch data preparation pipelines. Fivetran and dbt labs defined the modern data stack by running these pipelines on Snowflake. For cost reasons, many customers and partners are planning to move that work off Snowflake to batch engines such as Spark in Amazon Web Services’ EMR or Databricks Spark that are cheaper. Python-based data engineering and data science workloads started out on these services, though Snowflake’s Snowpark can now accommodate them natively in the DBMS.
- Governance: At the storage layer, governance is mostly about permissions. Permissions define who can access what data. Each data store typically owns permissions for its data. One of Snowflake’s differentiations is that data operates under a single set of governance policies as long as it stays in Snowflake. Databricks is using its Unity catalog to set permissions across a heterogeneous data estate, including Snowflake, Redshift and BigQuery. Accounts that move their pipelines off Snowflake will likely be attracted to Unity’s heterogeneous governance.
Application-level services
Applications driven by data from the real world respond to or anticipate events. To do this, applications need analytics to inform or automate decisions, with humans only sometimes in the loop. Applications need additional services such as a semantic layer to map between “things” in the real world and “strings” that a database manages, governance services to track how all the things are related, and workflow to organize the processes that connect everything. Databricks and Snowflake currently have the most advanced application-level services among the major data platforms.
- Analytics: Automating business processes led to silos of enterprise applications, each with their own data. When informing or automating a decision with analytics is the priority, having data integrated end-to-end becomes necessary. But analytics also requires a full spectrum of capabilities (Figure 2). Ideally, developers should be able to call on any type of analytic tools within their applications.
- Pipelines: Engineering the data from raw format into a shared, reusable, normalized form is the foundation for analytics. Customers have built these preparation pipelines with products such as 5Tran and dbt.
- BI dashboard: What followed is analytic engineers built business intelligence dashboards with metrics and dimensions.
- Predictive and prescriptive AI/ML: Data scientists then built AI/ML models based on labeled training data.
- GenAI: Today’s generative AI takes the form of large language models or LLMs. These models are pretrained on a large corpus of information so they can be fine-tuned for most tasks with modest data. Often, end-users can prompt the LLMs without any fine-tuning. Early workloads are focused on synthesizing information. Soon, they will act as agents accomplishing a task on behalf of end-users or applications. Databricks is extending its existing data science and MLOps tools and acquired MosaicML so that developers can train, fine-tune, and prompt their own models fed with data refined in Delta Lake. Its conference gave the impression it harnessed the energy of the data science community even more effectively than Microsoft did with its OpenAI partnership. Snowflake is betting that NVIDIA’s Nemo LLM tools give it a chance to catch up in the AI tools competition with Databricks.
- Operationalizing a decision: Any kind of analysis can inform or automate an action, typically in the form of an update to an operational application. With Databricks, a developer has to connect to an external application. Snowflake is enabling developers to build fully data-driven operational applications on its multi-model DBMS.
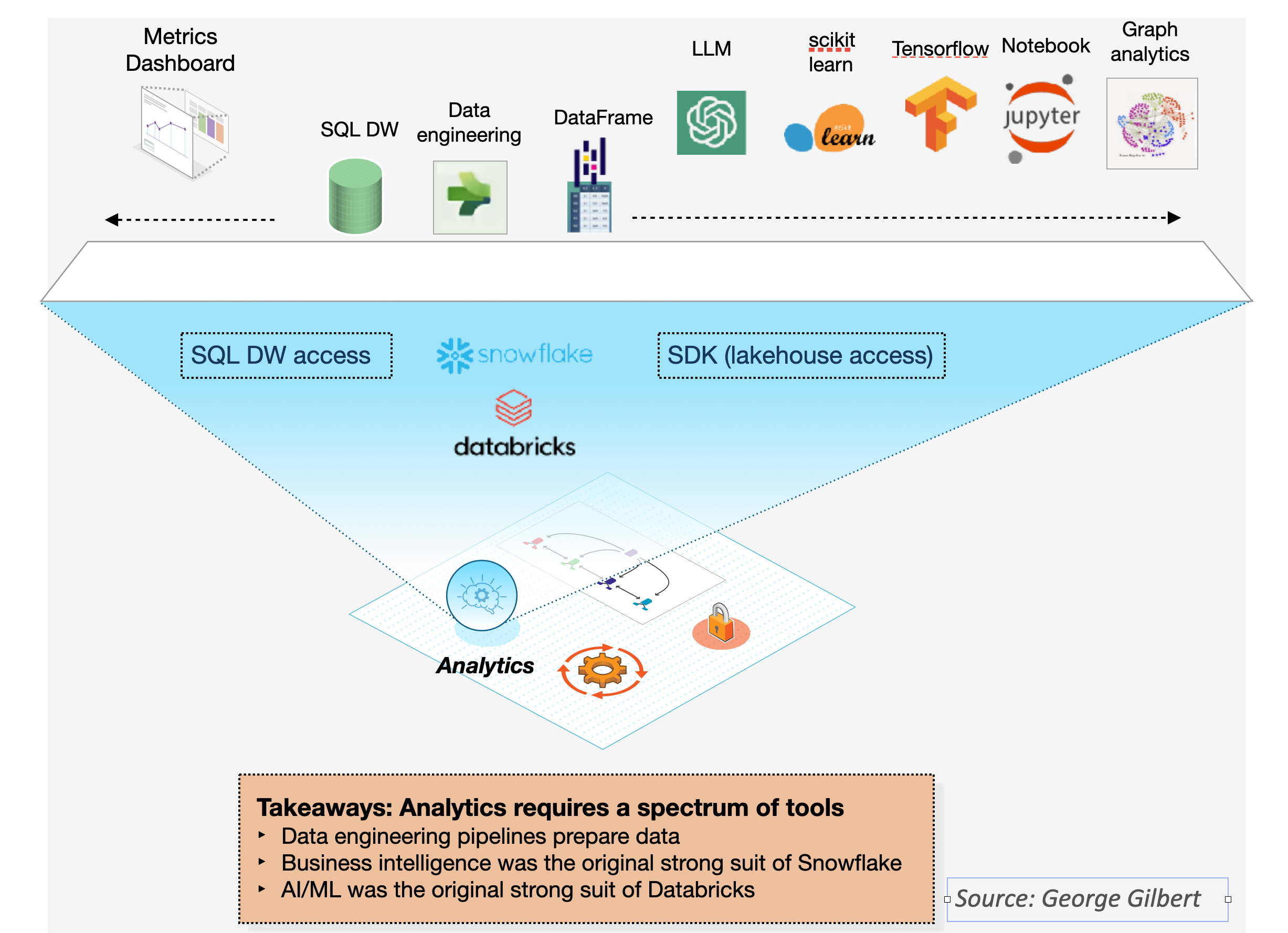
Figure 2: Data platforms require both BI and AI/ML. Databricks and Snowflake started with opposite strengths but are trying to offer the full range of capabilities.
- Governance: Databricks’ Unity harmonizes access not just to the tables in Lakehouse storage, but all the analytic data and permissions policies in a heterogeneous data estate including Snowflake, AWS Redshift, GCP BigQuery, and others. Unity keeps track of dashboards and AI models. But it also tracks the lineage of the data behind them, making it possible to audit decisions over time. This strategy is where Databricks converts its relative weakness in DBMS maturity to an advantage in governing a heterogeneous data estate. Snowflake, by contrast, appears to be leaving governance of data beyond permissions to partners.
- Semantics: At this layer, governance is meant to transform data “strings” such as tables of rows and columns into “things” that are meaningful to applications. Today “things” are dashboards or AI models. Tomorrow they will be the equivalent of Uber’s riders, drivers, fare estimates and estimated times of arrival. With LakehouseIQ, Databricks further hid all the technical details of data so that business users and, eventually, developers can use LLMs as copilots or agents when building applications across their data estate. LakehouseIQ uses an LLM that starts to infer the semantics of the data estate by reading dashboards, queries, AI/ML models and other artifacts to understand what “things” mean to each organization. Over time, LakehouseIQ should become a robust semantic layer. They appear to be heading towards the approach Palantir and EnterpriseWeb take, which make it possible to put a semantic layer for new application development above existing legacy applications. Here Databricks appears to be well ahead of Snowflake. Snowflake is using technology from the Neeva acquisition to make natural language queries possible. But it hasn’t talked publicly yet about its plans for a semantic layer for application developers.
- Workflow: The workflow functionality eventually has to make it simple to dynamically generate business processes. Applications that manage real-world people, processes and things have to respond to a wide variety of events. Developers won’t be able to hand code every eventuality. Policies will have to generate specific workflows on the fly. Today, both Databricks and Snowflake mostly use workflow to manage batch data pipelines.
Data platform as future application platform
Most traditional applications are built on compute, networking and storage infrastructure. In the future, applications will program the real world. In that world, data-driven digital twins representing real-world people, places, things and activities will be the platform. That explains the stakes for vendors and customers in building on these rapidly advancing technologies.
On balance, we believe that the distributed nature of data originating from real-world things, combined with the desire for real-time actions, will further stress existing data platforms. We expect be a variety of approaches will emerge to address future data challenges. These will come at the problem starting from a traditional data management perspective (such as Snowflake), a data science view of the world (such as Databricks) and core infrastructure prowess (cloud/infrastructure-as-a-service, compute and storage vendors).
The only constant is that the capabilities of data platforms are evolving very rapidly. Each of these approaches will vie for success, bringing advantages and tradeoffs. Ultimately, data applications enable mainstream companies to “program” the real world and manage their businesses in new ways, just the way Uber did with its pioneering application.
Images: Bing Image Creator, George Gilbert
A message from John Furrier, co-founder of SiliconANGLE:
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
- 15M+ viewers of theCUBE videos, powering conversations across AI, cloud, cybersecurity and more
- 11.4k+ theCUBE alumni — Connect with more than 11,400 tech and business leaders shaping the future through a unique trusted-based network.
Are you AWS customer? Support SiliconANGLE Financially by buying your AWS services from our Marketplace portal page and links.
About SiliconANGLE Media
SiliconANGLE Media is a recognized leader in digital media innovation, uniting breakthrough technology, strategic insights and real-time audience engagement. As the parent company of
SiliconANGLE,
theCUBE Network,
theCUBE Research,
CUBE365,
theCUBE AI and theCUBE SuperStudios — with flagship locations in Silicon Valley and the New York Stock Exchange — SiliconANGLE Media operates at the intersection of media, technology and AI.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.








 BIG DATA
BIG DATA