

















 AI
AI
AI
AI
AI
Twelve Labs Inc., the developer of generative artificial intelligence foundation models that can understand videos like humans, said today that the company has raised $50 million in early-stage funding co-led by New Enterprise Associates and Nvidia Corp.’s venture arm NVentures.
Previous investors Index Ventures, Radical Ventures, WndrCo and Korea Investment Partners also participated in the Series A funding round. The round follows $12 million raised as an extension to its seed round in late 2022 and brings the total raised to more than $77 million. The company said it will use the funds to nearly double its headcount by adding more than 50 employees by the end of the year and focusing on research and development.
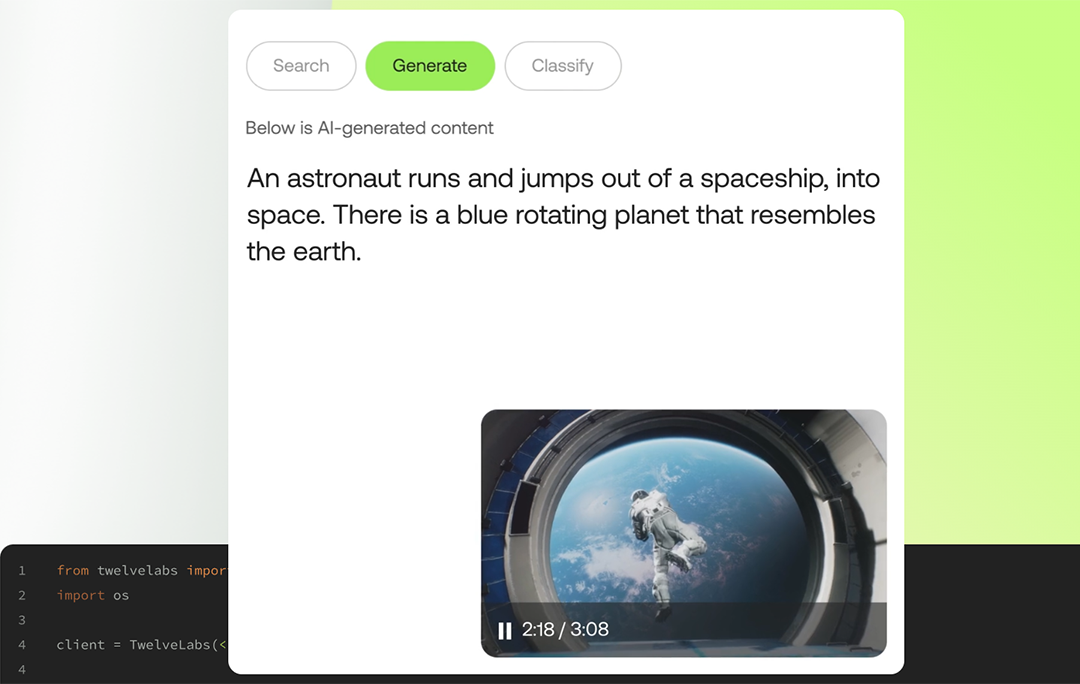
Twelve Labs develops and delivers generative AI foundation models that allow users to input natural language prompts that can “pinpoint and extract” exact moments in vast libraries of videos. Using its models, users can quickly locate scenes that would otherwise be lost amid hours of footage.
Its models can also generate text about videos through prompting, be it a summary, long detailed reports, title suggestions or highlights. Using the company’s models, businesses can classify footage by categories important to their purposes without the need to build or maintain custom classifiers. This capability can greatly speed up video searches and video understanding based on specific enterprise needs.
“Through our work, particularly our perceptual-reasoning research, we are solving the problems associated with multimodal AI,” said Jae Lee, co-founder and chief executive of Twelve Labs. “We seek to become the semantic encoder for all future AI agents that need to understand the world as humans do.”
Twelve Labs has two flagship models the Marengo-2.6 model, currently generally available, and the Pegasus-1, currently in beta mode. Marengo is a state-of-the-art foundation model capable of video, audio and image search tasks, such as text-to-video, text-to-image, text-to-audio, audio-to-video, image-to-video and more. The company says that it uses comprehensive understanding video understanding technology that makes it leaps and bounds superior to competitors.
Pegasus-1, announced in beta mode today, the company says sets a new standard in video-language modeling. It’s designed to understand complex video content and articulate about what it views with high accuracy with a reduced model size. According to the company, it began with an 80 billion parameter size, which has been shrunk down to 17 billion parameters and this makes it lightweight and nimble. It is made up of three components working in tandem: a video encoder, a video-language alignment model and a language decoder.
To empower developers to work with the multimodal capabilities of these models, Twelve Labs also introduced a new Embeddings API, which provides direct access to the raw multimodal embeddings within the Video Search API and Classify API. These application programming interfaces support all data modalities (image, text, audio and video), which in turn will allow developers to build apps that can use data as vectors for each of these different types of media together instead of separately.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





