INFRA
INFRA
INFRA
INFRA
INFRA
Google Cloud is updating its AI Hypercomputer stack for artificial intelligence workloads, announcing the availability of a host of new processors and infrastructure software offerings.
Today it announced the availability of its Google’s sixth-generation tensor processing unit, the Trillium TPU, plus the imminent availability of the new A3 Ultra virtual machines powered by Nvidia Corp.’s H200 graphics processing units. They’re joined by its C4A VMs based on its Axion Arm architecture, which are available starting today.
The company also unveiled new software, including a highly scalable clustering system called Hypercompute Cluster, plus the Hyperdisk ML block storage and Parallelstore parallel file systems.
In a blog post, Mark Lohmeyer, Google Cloud’s vice president and general manager of Compute and AI Infrastructure, said the AI Hypercomputer stack gives companies a way to integrate workload-optimized hardware such as the company’s TPUs and GPUs with a range of open-source software to power a wide range of AI workloads.
“This holistic approach optimizes every layer of the stack for unmatched scale, performance, and efficiency across the broadest range of models and applications,” he insisted.
Google wants to boost the performance of the AI Hypercomputer stack while making it easier to use and cheaper to run, Lohmeyer said. To do that requires an advanced set of new features, which is precisely what the company has unveiled today.
The most important new addition is the Trillium TPUs, which provide customers with a powerful alternative to Nvidia’s popular GPUs and are already used by Google to power advanced AI applications such as its Gemini family of large language models. The Trillium TPUs are available now in preview to every customer, and deliver significant improvements over the fifth-generation of Google’s TPUs.
For instance, they provide a four-times performance boost in terms of AI training and a three-times boost in inference throughput, Lohmeyer said. They deliver a 67% boost in terms of energy efficiency, plus a 4.7-times increase in peak compute performance, together with twice as much high-bandwidth memory capacity and double the Interchip Interconnect bandwidth, he added.
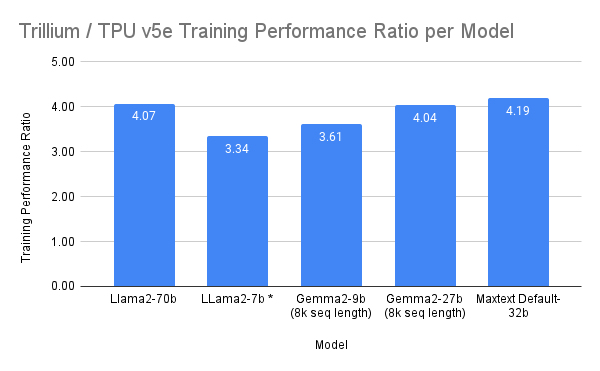
The increased memory and bandwidth means Trillium can run much larger LLMs with more weights and larger key-value caches. Moreover, it allows the chip to support a broader range of model architectures in both training and inference. It’s ideal for training LLMs such as Gemma 2 and Llama, as well as “Mixture-of-Experts” or MoE machine learning techniques.
Lohmeyer said Trillium can scale to a cluster of 256 chips in a single, high-bandwidth, low-latency pod, which can be linked to additional pods using its most advanced Interchip Interconnect technology. That means there are endless possibilities for customers, who have the flexibility to connect hundreds of pods and tens of thousands of the Trillium TPUs to create a “building-scale” supercomputer, supported by a 13-petabit-per-second Jupiter-based data center network.
“We designed our TPUs to optimize performance per dollar and Trillium is no exception, demonstrating a 1.8-times increase compared to the v5e TPUs, and about a two-times increase in performance per dollar compared to the v5p,” Lohmeyer said. “This makes Trillium our most price-performant TPU to date.”
Of course, Google Cloud’s customers aren’t limited to using the Trillium TPUs, for the company continues to buy up Nvidia’s most powerful GPUs by the bucketload. Using Nvidia’s H100 GPUs, Google has created its latest A3 Ultra VMs, which are said to provide a significant performance boost over the existing A3 and A3 Mega VMs.
Coming to Google Cloud next month, the A3 Ultra VMs leverage Google’s new Titanium ML network adapter and datacenter-wide four-way rail-aligned network to deliver up to 3.2 terabits per second of GPU-to-GPU traffic, Lohmeyer said.
As such, customers will benefit from twice as much GPU-to-GPU bandwidth, up to two-times the performance on LLM inference workloads, plus almost double the memory capacity and 1.4 times more bandwidth. Just as with the TPUs, customers will have the option to scale their deployments by connecting tens of thousands of the GPUs in a dense, high-performance cluster that can handle the most demanding AI workloads.

The A3 Ultra VMs are available as a standalone compute option and also through Google Kubernetes Engine, which offers customers an open, portable, extensible and scalable platform for AI training and serving.
Of course, Google has acknowledged that not every AI use case needs such incredible horsepower, for there are many kinds of general-purpose AI workloads that can get by on a lot less power. In such cases, it makes sense to optimize the stack for lower costs, and that’s exactly what the new C4A VMs are all about.
They’re powered by the Google Axion central processing units, which are the company’s first data center CPUs based on an Arm architecture.

Google makes some interesting claims, saying the C4A VMs provide up to 10% superior price performance compared to the newest Arm-based instances available on rival cloud platforms. In addition, they also compare very well with current-generation x86-based instances, with up to 65% better price performance, 60% greater energy efficiency for general purpose workloads such as web and application servers, database workloads and containerized microservices.
Constellation Research Inc. analyst Holger Mueller said the new hardware reinforces underscores Google Cloud’s status as the best cloud infrastructure platform for AI developers. With the Trillium TPUs, the company is maintaining a three-to-four year lead over its rivals in terms of putting customer algorithms like TensorFlow onto customer hardware.
“Next to the performance improvements, Trillium’s 67% energy efficiency boost looks to be extremely significant, as power considerations are increasingly important for every organization,” Mueller said. “It’s also nice to see the increased networking speeds and bandwidth, catering to much larger model sizes.”
In addition, Mueller said Google Cloud’s customers will be happy to know that the company is gearing up to support Nvidia’s most powerful GPUs, including the upcoming Blackwell GPUs that are set to launch next year.
“It’s a good time to be a Google Cloud customer, and there are a lot of them, as more and more enterprises have come to realize that it’s the platform to be on,” the analyst continued. “We can expect to see further confirmation of Google Cloud’s leadership in AI once the impact of these updates is felt.”
Alongside the new hardware, Google has made some big improvements to the underlying storage and networking components that make up the AI Hypercomputer, as well as the software that ties everything together.
With the new Hypercompute Cluster, Google says it’s simplifying infrastructure and workload provisioning, so customers can deploy and manage thousands of accelerators as a single unit. Launching next month, it provides features such as support for dense colocation of resources, together with targeted workload placement, advanced maintenance to minimize workload disruptions and ultra-low-latency networking.
“Hypercompute Cluster is built to deliver exceptional performance and resilience, so you can run your most demanding AI and HPC workloads with confidence,” Lohmeyer said.
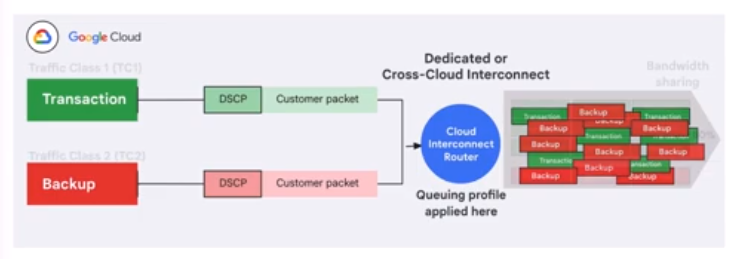
Meanwhile, Google’s Cloud Interconnect networking service is being updated with a new capability around “application awareness,” which is designed to solve headaches around traffic prioritization. In particular, it ensures that lower-priority traffic that’s being egressed from Google Cloud won’t adversely impact higher-priority traffic during times of high network traffic congestion. The other benefit is lower total cost of ownership, Google said, as it enables more efficient utilization of the available bandwidth on Cloud Interconnect.
Elsewhere, Google has made enhancements to its Titanium infrastructure, which is a system of offload technologies that can be used to reduce processing overheads and increase the amount of compute and memory resources available to each workload. With today’s enhancements, Titanium can now support the most demanding AI workloads, taking advantage of the new Titanium ML network adapter that increases accelerator-to-accelerator bandwidth. It also benefits from Google’s Jupiter optical circuit switching network fabric, which provides link speeds of up to 400 gigabits per second.
Finally, Google announced the general availability of its Hyperdisk ML block storage service, which became available in preview in April. It’s an AI-focused storage solution that’s optimized for system-level performance and cost-efficiency, delivering an 11.9-times faster model load time and 4.3-times increase in AI training times.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.