 INFRA
INFRA
INFRA
INFRA
INFRA
Much attention has been focused in the news on the useful life of graphics processing units, the dominant chips for artificial intelligence. Though the pervasive narrative suggests GPUs have a short lifespan, and operators are “cooking the books,” our research suggests that GPUs, like central processing units before, have a significantly longer useful life than many claim.
In this Breaking Analysis, we use the infographics below to explain our thinking in more detail.
In January 2020, Amazon changed the depreciation schedule for its server assets, from three years to four years. This accounting move was implemented because Amazon found that it was able to extend the useful life of its servers beyond three years. Moore’s Law was waning and at Amazon.com Inc.’s scale, it was able to serve a diverse set of use cases, thereby generating revenue out of its EC2 assets for a longer period of time. Other hyperscalers followed suit and today, the big three all assume six-year depreciation schedules for server assets.
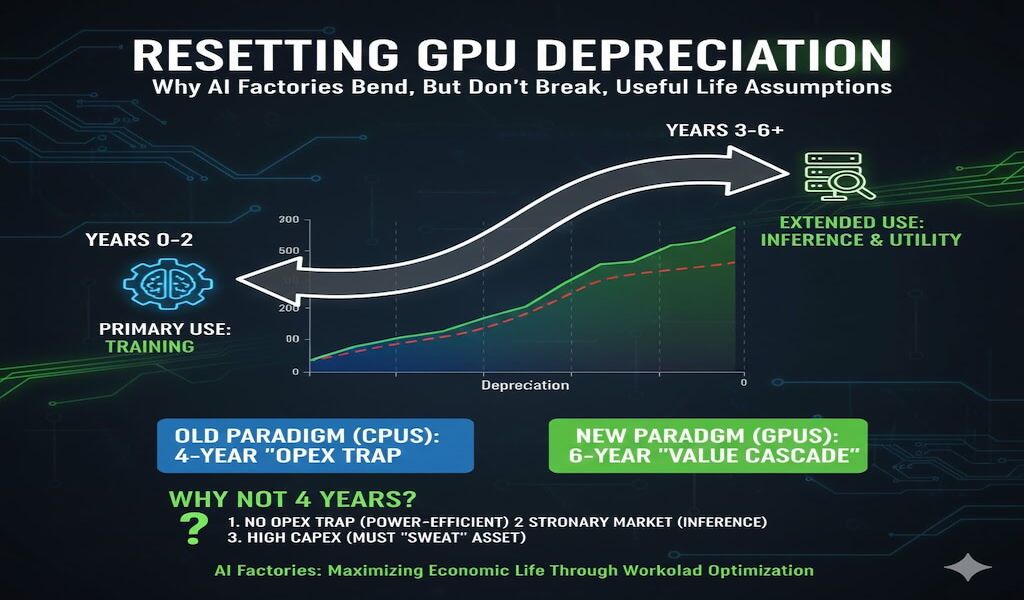
The question is, in the AI factory era, will this same dynamic hold or will the useful life of servers compress? It is our view that the dynamic will hold in that today’s most demanding training infrastructure will serve a variety of future use cases, thereby extending the useful life (revenue per token) of GPUs beyond their initial purpose. At the same time, we believe the more rapid innovation cycles being pushed by Nvidia Corp. will somewhat compress depreciation cycles from their current six years to a more conservative five-year timeframe.


 Data sourced from public SEC filings and industry reports
Data sourced from public SEC filings and industry reportsWhat the infographic shows:
Figure 1 shows the depreciation schedules for Amazon Web Services, Google Cloud and Microsoft Azure from 2017 to 2025. The chart highlights the coordinated progression from three- and four-year schedules to a uniform six-year useful life assumption beginning in 2023-2024.
Key takeaways:
Our research suggests that this shift reflects the hyperscalers’ confidence in workload diversification. Even as hardware aged, demand for general compute, analytics, web services and long-tail workloads sustained revenue generation across an asset’s lifecycle. The open question is whether AI GPU estates, which are more expensive, power constrained and evolving faster, behave the same way.
What the infographic shows:
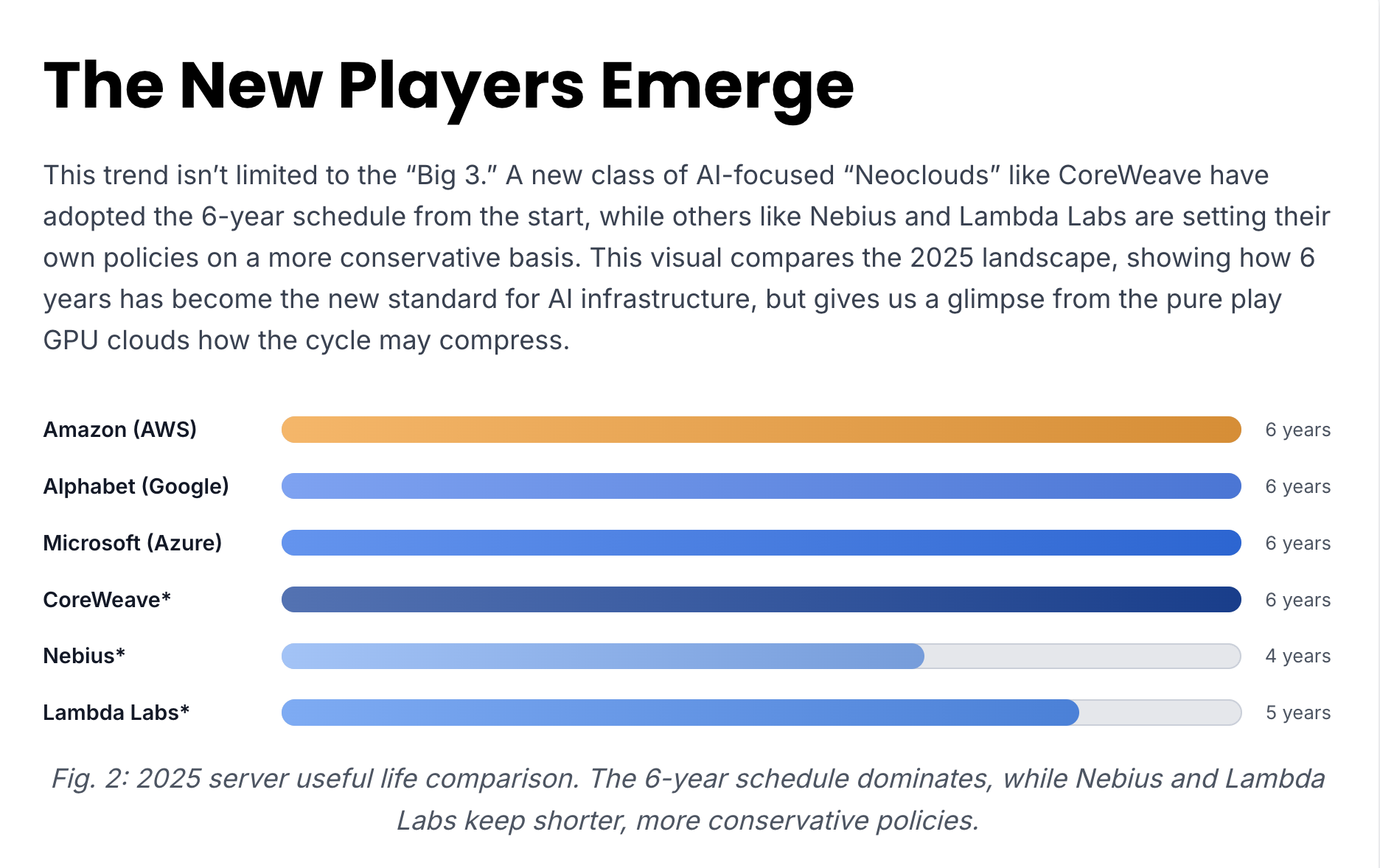
Figure 2 shows a horizontal bar comparison of depreciation schedules across hyperscalers and AI-native neoclouds (CoreWeave, Nebius, Lambda Labs). The big clouds have settled firmly on six-year depreciation, while neoclouds take more conservative positions (five years for Lambda Labs, four years for Nebius).
Key takeaways:
In our view, Figure 2 is a harbinger for slight compression. AI-first clouds cannot afford stagnant infrastructure; performance/watt gains in successive GPU generations directly determine competitiveness. As neoclouds scale, their four- to five-year cycles will likely influence hyperscaler modeling —especially as accelerated computing consumes a larger share of CapEx.
What the infographic shows:
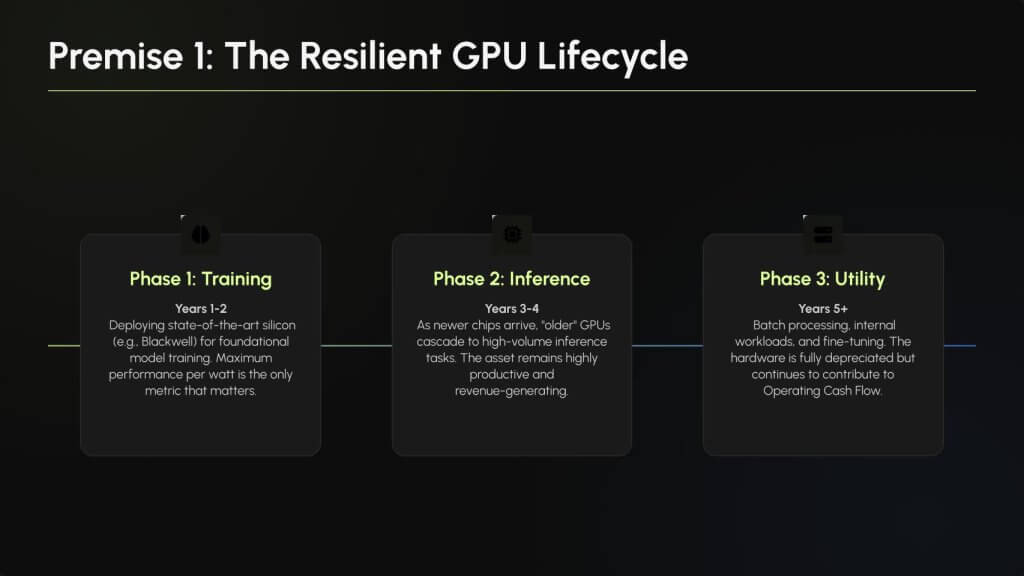
Figure 3 depicts a three-stage lifecycle framework:
Key takeaways:
We believe this framework supports longer useful life assumptions than the two to three years many have stated. Silicon doesn’t die at end-of-training usefulness, rather it transitions to less demanding but still revenue-generating tasks. This is the essence of token revenue maximization in the AI factory era.
What the infographic shows:
Figure 4 shows three tiles summarizing impact:
Key takeaways:
Our analysis suggests that AI factories magnify the issue but not to the extent many in the media have projected. A one-year change in useful life assumptions for trillion-dollar GPU estates can swing operating income by tens of billions; but in the grand scheme of operating profits for hyperscalers, it’s not game-changing. This dynamic will become a recurring narrative in earnings calls and investor guidance. As such, investors should look at operating and free cash flows to get a better sense of business performance.
The following section summarizes our thinking on this issue:
Key takeaways:
We believe the proliferation of agentic applications, retrieval workflows, automation assistants and fine-tuning pipelines will expand the useful life of GPUs beyond the training phase. This reinforces the durability of extended economic cycles.

Key takeaways:
Our research indicates that this five-year midpoint is where hyperscalers will ultimately converge as accelerated infrastructure dominates CapEx. Thoough general compute has historically survived at six years, AI factories operate under different competitive pressures. Moreover, the utility of legacy CPU technologies may compress as they become less useful. But on balance, we don’t see a dramatic alteration of the income statement as a result of AI.
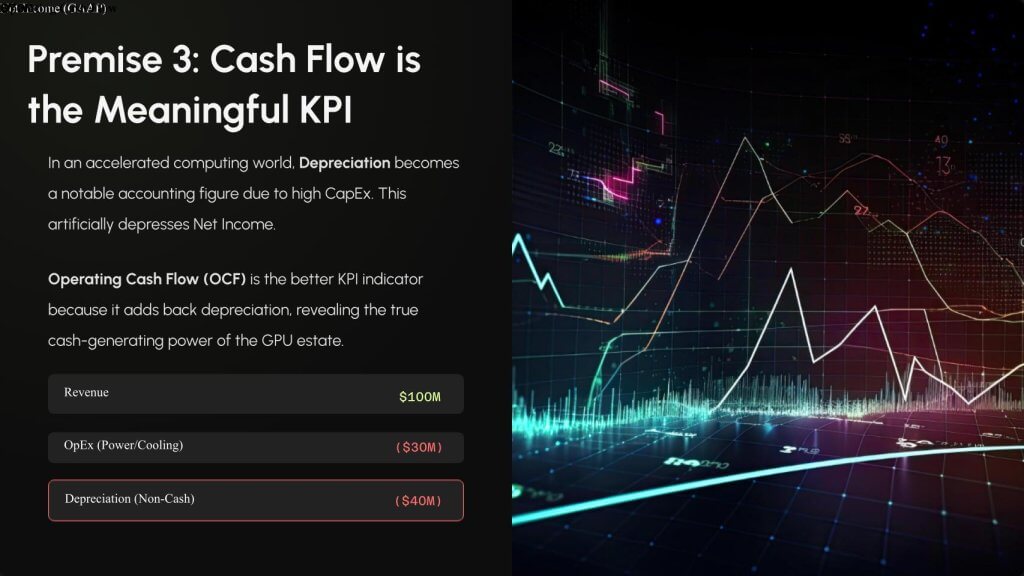
Key takeaways:
In our opinion, investors must shift their valuation frameworks. Operating cash flow will become an increasingly important key performance indicator relative to non-GAAP and GAAP income. OCF will be a primary indicator of AI factory health, sustainability and ROI timelines. This becomes crucial as depreciation cycles compress.

Key takeaways:
The above graphic frames the strategic direction of the industry, which will likely extended economic utility with slightly shorter accounting life – reflecting both technological realities and revenue/token expectations.
Our research indicates that the useful life of GPUs will continue to benefit from the “value cascade,” allowing assets to generate revenue well beyond their initial training window. At the same time, the arrival of new architectures every 12 to 18 months will put pressure on formal depreciation schedules. We believe hyperscalers will ultimately converge on a five-year cycle – shorter than today’s six-year model but still supported by extended economic usefulness.
In the AI factory era, depreciation becomes a lever. The winners will be operators that maximize the utility curve of GPUs across training, inference and internal workloads while maintaining access to compute, land, water, power and the skills to build AI factories. As CapEx scales into the trillions, cash flow will increasingly be the metric investors will watch.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.