 NEWS
NEWS
NEWS
NEWS
NEWS
The latest project to reach top-level status in the Apache Software Foundation is a no-lose proposition for everyone, or at least that’s how the project leaders are positioning it.
Apache Arrow achieves that elite ranking today under the direction of veterans of other notable Apache projects like Parquet, Drill, Pig and Calcite, and with the support of 13 major open source big data projects, including Cassandra, Drill, Hadoop and HBase.
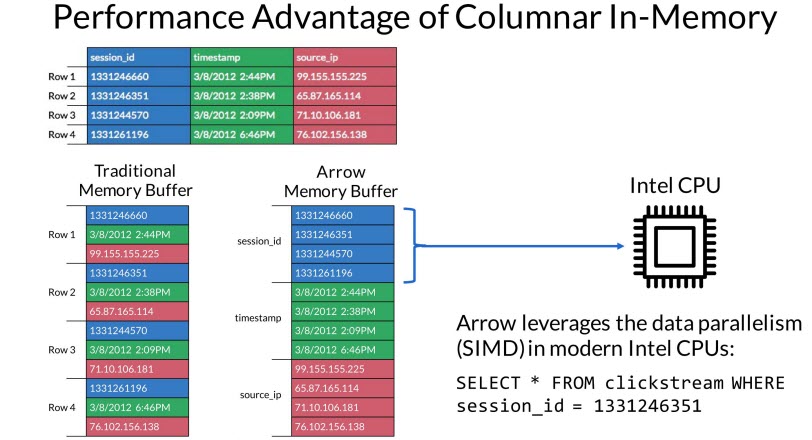
Arrow proposes to give nearly every big data analysis and reporting tool a ten- to one hundred-fold speed boost by enabling them to use columnar in-memory analytics, a memory mapping technique that arranges data in columns rather than rows.
 Arrow is an embeddable technology that’s designed to work with existing systems like Drill, Spark, Kudu and many others. “It’s an accelerator for processing and storage systems,” said Jacques Nadeau (right), founder and chief technology officer at Dremio Corp. and chairman of the Apache Drill project management council (PMC). “It’s a set of data representations that are much more CPU-efficient.”
Arrow is an embeddable technology that’s designed to work with existing systems like Drill, Spark, Kudu and many others. “It’s an accelerator for processing and storage systems,” said Jacques Nadeau (right), founder and chief technology officer at Dremio Corp. and chairman of the Apache Drill project management council (PMC). “It’s a set of data representations that are much more CPU-efficient.”
Nadeau has teamed up on Arrow with co-founder Tomer Shiran, formerly vice president of product at MapR Technologies Inc. and Julien Le Dem, founder of Apache Parquet and member of the Apache Pig PMC.
Columnar in-memory processing has a couple of big advantages over row-based processing, including the ability for applications to handle larger data sets and to work on a few big values instead of a lot of small ones.
The disadvantage? “Doing in-memory columnar is hard,” Nadeau said. “Doing rows is easy.”
But easy has its downside. Using row-based memory processing means applications either need to accept the limitations of that structure or reload data into a memory configuration of their own choosing. Such serialization and deserialization can waste up to 80% of CPU resources, the project leaders claim. Reformatting also creates multiple copies of the same data.
If developers of popular data processing engines can agree that in-memory columnar is superior, which is something the Arrow leadership team indicated is a no-brainer, then there is one more big advantage: Multiple applications can share the same memory.
“When Kudu wants to hand a data structure to Drill, it can use the same representation of memory,” Nadeau said. “You can share data between systems at no cost.” That improves on interoperability, performance and memory efficiency. It also gives users more choice by taking memory-handling out of the equation when choosing a processing engine.
Support for the C, C++, Python and Java languages is expected to be available at launch with additional languages to be added over the next few months. Arrow is expected to be adopted by the Drill, Ibis, Impala, Kudu, Parquet and Spark projects this year. In addition, “My expectation is that at launch we’ll see a number of commercial companies and projects get involved,” Nadeau said, declining to name names.
He likened Arrow to Apache Yarn, the open source cluster manager. “Yarn democratized access to the cluster,” he said. “This democratizes access to data.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.