









 CLOUD
CLOUD
CLOUD
CLOUD
CLOUD
Nobody likes the misleading name of the latest hot trend in cloud technologies, but “serverless” computing nonetheless has captured the hearts and minds of an increasing number of companies looking for an easier onramp into cloud computing.
Serverless refers to an emerging way of creating cloud applications that doesn’t require software developers to fuss with provisioning servers and storage in the cloud. It doesn’t actually get rid of servers, but cloud providers such as Amazon Web Services Inc. take care of the heavy infrastructure lifting, potentially saving time and money spent on excess cloud computing and storage.
In an exclusive, wide-ranging interview with SiliconANGLE recently near Amazon’s Seattle headquarters, AWS Chief Executive Andy Jassy (pictured) spoke about the move to serverless and AWS’s plans to move more forcefully to provide serverless technologies through its Lambda and other services. “The torrid pace of adoption and innovation in the serverless space has totally blown us away,” he said, with hundreds of thousands of users, more than four times as many as a year ago.
“Amazon really kickstarted the serverless space a couple years ago with the introduction of Lambda,” said Dan Scholnick, a general partner at Trinity Ventures who has invested in serverless startups. “We really believe this is the future of applications infrastructure.”
Jassy still has a lot of work to do to make sure AWS can lead in serverless. Although Lambda has gotten a lot of attention and use, some think rivals such as Microsoft Corp.’s Azure and Google LLC’s cloud platform have a good chance to steal a march. Nick Rockwell, chief technology officer at The New York Times, said he has been pushing Jassy for a couple of years to do more in serverless.
“For all the providers, it’s more of a marketing concept than an engineering project,” he said. It’s likely Jassy will shed more light on those efforts at the AWS re:Invent conference this week in Las Vegas, which he will keynote on Wednesday morning.
In this second of a three-part series, Jassy also talked about the rise of databases as a nexus for cloud competition — and how he thinks AWS is beating Oracle to new database users. And he spoke about how AWS is fitting out its cloud for new technologies ranging from artificial intelligence to the “internet of things.”
The first part of the interview addressed how AWS is aiming to attract more large enterprises to its cloud against newly awakened rivals such as Oracle Corp. In the third part, Jassy will talk about how he manages breakneck growth and fast-changing technologies — and whether Amazon will spin off AWS. The interview was edited for clarity.
Q: Serverless is hot. I think that Lambda [AWS’s serverless offering, which allows applications to be run without having to specifically provision servers in the cloud] showed us kind of this new model, function as a service. How did serverless develop at AWS?
A: The torrid pace of adoption and innovation in the serverless space has totally blown us away. Hundreds of thousands of customers are using Lambda already. That’s about 300-percent-plus year-over-year growth.
For the first five or six years of AWS, we used to always say: If we were starting Amazon today, we would have built it entirely on AWS. The teams are now feeling like if we were starting Amazon today, we would have built it on top of Lambda and our other serverless capabilities because the ability not to have to think about or manage servers, not to have to figure out how to build your applications in a fault-tolerant way across multiple availability zones, not to have to kind of increase capacity yourself versus being able to just kind of say, “I need more of these compute units,” not having to install any software to maintain. It really is such an evolved and easier-to-innovate-quickly style of computing.
Q: You think this is a watershed moment in cloud computing?
A: I think there are going to be large generations of customers that will skip instances and containers and go right to serverless. FINRA [Financial Industry Regulatory Authority, Inc.] uses our serverless applications to run their market-watch app that does half a trillion validations on 37 billion market events a day. Thomson Reuters has built a big business-analytics service that does 4,000 events per second. So I think compute is changing a lot.
Q: How about the price point? Are you seeing comparable price points coming into serverless?
A: It’s really cost-effective because one of the other characteristics of these serverless services, for the most part, is that you don’t pay for idle. You only pay when things are actually triggered. It’s very, very cost-effective.
Q: I want to ask you about the database. We’ve heard a good debate around the idea that Amazon doesn’t have a Tier 1 database like Oracle’s.
A: Which is not true! I think that the database space is another place that you see huge changes. People are just so fed up with the database options they’ve had in the enterprise over the last few decades. We don’t meet customers that aren’t looking to flee the old-guard providers.
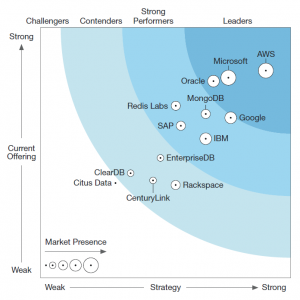
Database-as-a-Service, Q2 2017 (Source: Forrester Research Inc.)
Q: Like Oracle?
A: Like Oracle. It’s why you’ve seen so many people move as quickly as they can to the open engines like MySQL and Postgres. But while you can build really performant applications on top of the open engines, it’s hard. DynamoDB today is kind of the linchpin with a lot of these serverless applications.
Q: Do you see massive growth in net-new databases?
A: Massive! Actually, both in net-new databases as well as migrations. Aurora in the relational space and DynamoDB in the nonrelational space. These are absolutely Tier 1 database options with really strong performance.
You look at Aurora, it’s got the same availability and — at least as good availability and [durability] capabilities as commercial-grade, old-guard databases but a 10th of the price. And it’s why it’s the fastest-growing service in the history of AWS. It’s growing unbelievably quickly.
Same thing on DynamoDB. One of the interesting things I think about the database space, which is totally changing how databases are used, is that in the old days people often would use one database, one relational database, for all their database needs regardless of whether those applications needed the complexity and the expansive costs and some of the constraints, frankly, in relational databases.
Today that’s not the case. There are a number of companies who have significant relational database needs. There’s a lot of companies who want to keep value key, and that’s why they use DynamoDB. And there’s a lot of companies who want in memory databases, and that’s why they’ll use [AWS] ElastiCache.
Q: Well, if you guys have got any stats on database growth, I’d love to see them because I’m trying to make the argument that now we are seeing big database growth and Oracle will keep their existing databases, but ultimately if the database market is growing, can Oracle participate in the net new growth of database?
A: And they’re not.
Q: So you think that Oracle is not participating in the new growth in databases.
A: I don’t. No new companies use Oracle. You’ve got to be out of your mind to get into a bed with a company that customer hostile with that kind of price structuring and one will fine you at any moment.
But also I would say that they really have a relational database is very expensive, it’s very proprietary. You compare that to Aurora, which has the same performance capabilities at a 10th of the cost, fully compatible with either MySQL or Postgres. So if you decide you want to move away from it, it’s relatively trivial. That’s a much more attractive value proposition. Most companies use multiple types of databases in their applications and many of them now will use multiple types of databases in the same application.
Q: How is AWS addressing the “internet of things” and the rise of edge computing to deal with all the data IoT devices are producing? There was an article on end of the cloud, that was written by a guy [Andreessen Horowitz partner Peter Levine] who’s pushing the whole decentralized database, decentralized web kind of concept. How does AWS view cloud versus edge?
A: There have been these terms that have been all this buzz: cloud, big data, serverless, ML, AI, IoT. In many ways, IoT has delivered the fastest of all of them. IoT isn’t just happening in industrial IoT, it is happening everywhere in a really fast way. In part it’s because the device manufacturers like it and it allows them to sell more devices, and in part it’s because companies are so hungry to get data from their assets out in the field that they’ve never really been able to get data or it takes a lot of time.
But if you think about it, these devices inherently have relatively little CPU and disk, which means the cloud becomes disproportionately important to supplement those devices.
Q: What does the design of those networks look like?
A: The vast majority of IoT implementations today are using AWS. Illumina, with all their genome sequencing hardware, is sending all that data to AWS to do large-scale analytics on different patient data and different symptoms and pairing those in AWS. John Deere has turned a thousand telematically enabled tractors that are sending planting conditions information in real time. AWS through analytics is sending information to planters on the ground to where to go.
Or look at Major League Baseball, with Statcast, they have small data centers in all 30 ballparks around the league and then they’re taking that data and sending to AWS and doing analytics. And then sending it back down to the small data centers in the trucks. And that’s a big old IoT application. So we see a huge amount of those.
Q: So it’s about using the cloud in a new way?
A: When you think about hybrid 10 years from now, I don’t think the on-premises part is largely going to be servers. All those servers are moving to cloud. It’s going to be these connected devices. There are going to be billions of them out there, in your office, in the factories, in oil fields, in agricultural fields, in ships, in planes, in cars. These devices are going to be small. And so they’re going to do some computing on the device, and I’ll talk about that in a second. But for anything substantial, in terms of the analytics or processing, you’re going to do in the cloud. You just can’t afford to do it on the device.
There are going to be times when I don’t want to make the round trip through the cloud. Now I want to have the same programming model to be able to do what I do in the cloud on the device. So that’s why we released Greengrass last year, which is really like a software module you embed in devices that has Lambda inside of it so that developers can then program once, say I want these functions can be triggered and run in the Cloud, and these functions can be triggered and run on the device.
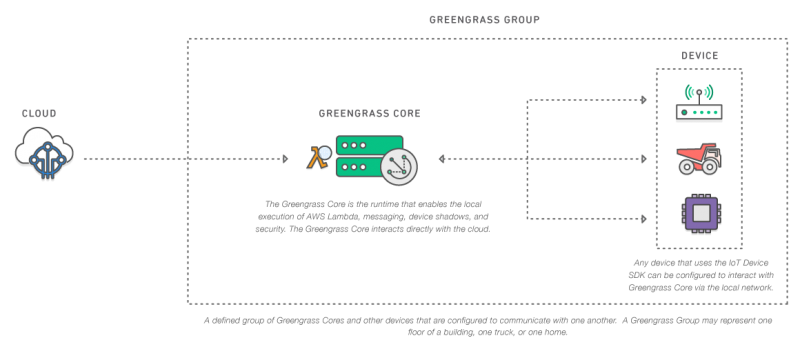
Source: AWS
A good example of that is Rio Tinto, the diamond and mining company. They have these big tractors that are going down into the diamond mines and the roads are really rough — and the tires cost like $20,000 apiece when you blow a tire. And so they they have Greengrass with Lambda installed on these vehicles so that if one of them detects a nail, or something really potentially injurious for the upcoming vehicles there, they actually have a way to actually signal back to the other vehicles and they have maps actually where where it’s going.
Q: Security is a big concern for IoT. How are you addressing that?
A: In everything you do, if you have data that matters, you have to care about security. It’s true on-premises, it’s true in the cloud, and it’s true in IoT. You only have to look at what happened with the Dyn attack last year, which came from an IoT device, to know that there are risks.
We have a pretty significant security capabilities in AWS IoT and I think you can expect that we’re going to continue to add additional capabilities for people on the security side. We don’t see it stopping people. People are moving very fast right now in building IoT connections to the Cloud. It’s moving really quickly. And it’s a huge area of investment for us.
Q: What’s the general uptake of IoT? Because a lot of others are scratching their heads, not because it’s not important but because they have other rooms on fire in their house.
A: There are some companies that haven’t gotten to IoT yet. But I would say that enterprises are getting to it pretty quickly and in many cases it’s becoming their first applications that they actually run the cloud. A very typical example is [utilities] want to run smart meters in people’s homes so that they can be capturing information on what people are normally doing and what the temperatures are. And then looking at that analysis and taking actions in people’s homes on those meters. In the past, they couldn’t do it because the meters didn’t have any intelligence and couldn’t communicate with the cloud through analytics.
Over time what you’ll see is the people are going to want to do a lot of machine learning on the edge as well. But enterprises are typically are figuring out how to actually collect the data from those assets and send it to the cloud, and that’s what we’ve enabled with AWS IoT. We’re seeing a pretty significant set of adoption on device using AWS IoT and [AWS streaming data processing service] Kinesis stream that data and store it, setting up Lambda functions to do analytics and then taking action back to the device itself.
Q: What is Amazon doing with artificial intelligence and machine learning? Jeff Bezos talks about it all the time.
A: ML and AI are finally at a stage where people can really use it in a more expansive way than what’s been in the past where it’s just largely been a vision. We see ML as kind of having three layers of the stack. The bottom layer is for the expert practitioners — those who know how to build a model, know how to actually train it, know how to do the tuning. You know, it takes a lot of work to get one of these models to actually be effective, and then know how to deploy it and run it in production.
We have a little bit different approach to that bottom layer than some of the other companies. Other companies say, “Hey, look, everybody should use just this framework.” And that’s what machine learning and deep learning is. If you study the history of machine learning and deep learning, the one consistent part is change. Whatever is fashionable today, there ends up being a new methodology, a new architecture, a framework that people want to run.
Today I would say TensorFlow has a lot of resonance. And the majority of TensorFlow being run on the cloud today is being run on top of AWS. If you want to do computer vision, it turns out that Caffe 2 is a really good solution. Or if you want to do recommendation systems, or image, video, analytics and natural language processing, it turns out that MXNet scales the best. So we’re going to support all those frameworks.
Q: What about the higher layers of AI and ML?
A: The problem is there isn’t that many companies who have expert machine learning practitioners. If you really want machine learning to exponentially expand and reach its potential, you’ve got to solve that middle layer of the stack, which to me is figuring out how to make it much more accessible for everyday developers. If you don’t make it accessible for developers, it’s never going to expand the way we think it should. We have some services there today and we have more that are coming. And we’re really focused on trying to make that much easier.
And then there’s that top layer of the stack, which I’ll call application services that most closely resembles AI or human function: text-to-speech, object recognition, conversational apps and bots. We have lots of services there and lots more that are coming. We’re investing in all three layers of this stack more significantly. Today, most of the usage is at the bottom layer of the stack or the top layer of the stack. But I think the real jewels for most companies come in being able to figure out the insights of their own data.
Q: Security no longer seems like the biggest concern of companies moving to the cloud, but how are you trying to make sure you can continue to improve on it as cyberattacks grow?
A: Security has always been the No. 1 priority. There’s nothing that rivals it. We have very deep capabilities. We pursue a lot of the same tactics that people have pursued for a long time in terms of very strict physical access control to our data centers and making sure that nobody can impinge on our networks in any way.
Q: We are seeing a trend where a lot of the type of stuff involved in government is moving into commercial very rapidly. Is that the case with security as well?
A: We have certain customers where the requirements are such that we have to build something a little bit different for them. And AWS GovCloud is a good example where it needs ITAR [International Traffic in Arms Regulations] compliance. And so we built a [cloud] region that’s completely ITAR-compliant.
Q: Is that the secret region you just announced?
A: There are different classifications of kind of classified information of the government, so Top Secret has a certain set of requirements. And there are certain organizations that require Top Secret requirements in order to put their workloads in there. There is another really secure classification, called Secret, which is one layer below Top Secret, but a layer above something like an ITAR or just a general public cloud, that are required for a whole bunch of other workloads. So we built a Secret region in addition to some of the other capabilities we have.
Q: What other services are you offering to improve security?
A: We have a lot of services that we run internally to keep our environment safe that our customers are asking us to externalize. They want to be able to run themselves, instead of having us run it for them. That’s part of what Inspector was, which we launched a year or so ago. That basically was a way for people to give us their applications and inspect for any kind of vulnerabilities and give them a report back, almost like doing a vulnerability inspection for their applications.
We also launched Macie in August. People have all of this data they’re storing internally, and they don’t actually know with all this data which data is the most sensitive and which data’s not, and then if anything anomalous has happened to that data. What Macie does is use machine learning to classify which are your most sensitive data components and classifies them into different categories. And then it uses CloudTrail to watch if there’s been any unusual movement of that data: Has it been accessed by someone who doesn’t normally access it? Is there malware? Is there a large amount of data that’s moved out of a particular area of storage that doesn’t usually happen?
Most companies, even though they know security’s important, they don’t have the amount or the expertise and resources to build these types of machine learning-infused security capabilities, which now they can just use on their data.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





