The NOSQL world is crowded with data stores that offer variations on key-value storage. These so-called aggregate-oriented# stores often have beneficial operational characteristics when compared to relational databases but little modeling expressiveness.
The NOSQL world is crowded with data stores that offer variations on key-value storage. These so-called aggregate-oriented# stores often have beneficial operational characteristics when compared to relational databases but little modeling expressiveness.
Yet there’s another corner of the NOSQL universe where different choices have been made, where models have become far more expressive compared to relational databases: these are the graph databases and they are set to take the data storage and processing world by storm. Companies like Cisco, Adobe, and Deutsche Telekom—not to mention lots of hot startups—are now using graph databases. They are used in online systems with the most demanding performance and availability requirements, oftentimes achieving 1000-fold improvement over relational databases, with a model that is more nimble and easily adapted to change. Some key uses include social, recommendations, fraud detection, network and cloud management, geo, and MDM.
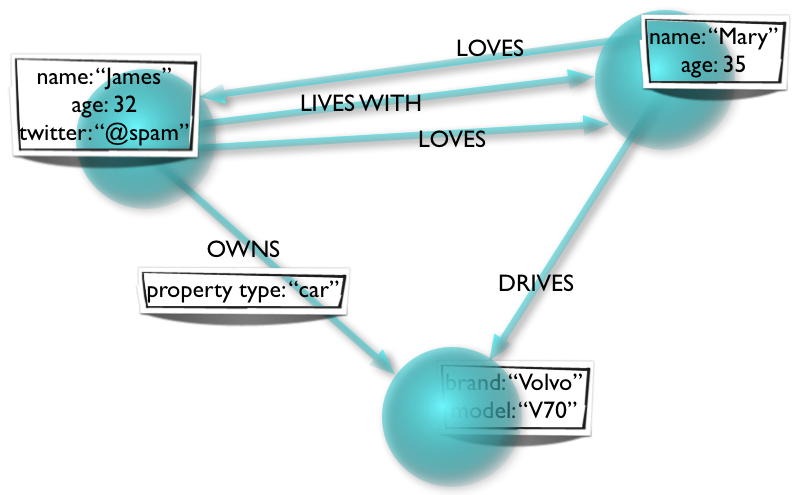
A graph database – as its name suggests – stores data in a network structure where entities are represented by nodes containing properties. Those nodes are connected via relationships. And relationships can have a direction, a label, and can themselves contain properties too.
The relationships in the graph are as important as nodes, and are a part of what makes graph databases intriguingly unique and mind-bendingly fast. Relationships are not only logical, but physically relate distinct pieces of information in the database through in-memory pointers, making the “jump” between any two pieces of related information nearly instantaneous, and the jump between millions of pieces of related information sub-second, on a commodity computer.
A household and their car, for example, can be easily expressed as a graph in the following way. Note that the sentiment “James Loves Mary” is directly expressed in the data model in the same way that we think about it:
Intrigued? Then here are our five top reasons why you’ll be getting your graph on in 2013.
Relational databases have served us well enough for decades, but the model underpinning them creaks at high data volumes, especially when we join (or recursively join) several tables. Queries take longer as the total data set size increases (something we take for granted, which is largely not true when it comes to graph databases), so queries over large data sets (or involving several joins) are often infeasible for OLTP scenarios.
Other kinds of NOSQL stores work well only for simple retrievals, making them great for certain uses. However they usually break down with sophisticated queries, because they are not designed to relate data in real time. Some NOSQL data stores, such as Hadoop, are able to relate large amounts of data in batch by processing (sub)sets of bulk data, typically with a map/reduce framework. This adds latency that is incompatible with OLTP workloads, and real-time demands.
Graph databases don’t suffer the same join penalty as relational databases (which require computing relationships versus following them), or the same compute penalty as aggregate stores (which require joins to occur either in the application, or though bulk map-reduce operations). Graph databases are query-oriented rather than compute-oriented. Under the hood, the database finds a starting point in the graph, and walks the graph by following relationships through pointers. Not only does this lead to incredibly fast results, but it leads to unparalleled scaling characteristics. No matter how much data is in my database, the same query will take roughly the same amount of time, because the query time is proportional to result size rather than data size.
In a typical social graph scenario — finding friends of friends at any reasonable depth — graph databases will be orders of magnitude faster than competing approaches, enabling real-time queries within the clickstream for timely, high fidelity, high-value interactions. The same applies to risk analysis, network failure analysis, route optimization over a network, and so on.
 The data in our databases tends to support many systems and business processes over its lifetime, each of which have a tendency to evolve. Graphs – which allow for rich data structure without the constraints of schema- are naturally extensible and amenable to continuous data evolution. In fact since the kinds of updates that extend the capability of the business are usually additive, new structures can be merged into the graph without disturbing existing applications. Older queries typically just ignore the new structures whose relationships they aren’t programmed to understand. Correspondingly this provides data model agility that far exceeds the capabilities of relational model where sophisticated schema migrations are the order of the day whenever any significant changes to applications are involved.
The data in our databases tends to support many systems and business processes over its lifetime, each of which have a tendency to evolve. Graphs – which allow for rich data structure without the constraints of schema- are naturally extensible and amenable to continuous data evolution. In fact since the kinds of updates that extend the capability of the business are usually additive, new structures can be merged into the graph without disturbing existing applications. Older queries typically just ignore the new structures whose relationships they aren’t programmed to understand. Correspondingly this provides data model agility that far exceeds the capabilities of relational model where sophisticated schema migrations are the order of the day whenever any significant changes to applications are involved.
In turn, data model agility provides a further boost to agility at the business process tier. While the data that powers organizations can evolve without undue friction, the decision support processes that consume that data, can themselves be represented as dependency graphs, and can be smoothly evolved and versioned.
Business processes modeled using graphs (an obviously natural paradigm in itself) can be re-engineered and even formally verified quickly. Business agility is boosted as organizations can respond to process change and management in a structured and diligent manner, yet do so rapidly and repeatably.
Data modeling in a graph is simplicity itself. Simplicity in modeling with graphs comes from the fact that graph databases are whiteboard-friendly. Once we have a model that reads well on a whiteboard, it’s typically the same model that we persist into the database. This means that the semantic gap between domain experts and data stored is very much reduced#.
For example, imagine if you could take the entire diagram of your data center and cloud deployments and begin to ask questions of that model – where are the single points of failure? Which customers would suffer loss of service if a particular switch failed? What must have been misconfigured for these two different sets of customers reporting loss of service?
This kind of network analysis is readily implemented in graph databases, providing rapid and scalable (carrier-grade) network infrastructure modeling and management. Modeling a network is as simple as joining nodes and relationships and discovering single points of failure. Finding a common ancestor for incident reports is as simple as following the lines back to their source.
The graph model is accessible to regular business users too. Technicians that fix actual faults, or architects who plan future capacity and rollout, or route planners who optimize logistics networks, can easily understand and evolve the model while maintaining structural integrity of the graph and the corresponding infrastructure.
Modern graph databases offer mature features for building dependable systems. For example Neo4j – the leading graph database – is ACID transactional, and offers clustering for high availability and throughput for mission-critical applications. Such configurations close the gap between OLAP and OLTP since semantically rich graph data is accessible not only to online systems, but also for running long-running analysis work, simply by attaching read-only OLAP slaves to the cluster.
 This is a disruptive moment in business intelligence, that the same highly available, highly dependable, low latency systems are becoming the bedrock for real time business intelligence. No longer do we push business intelligence into a backwater OLAP system, we bring it directly into the clickstream with analytics and online intelligence merging into the same graph. And since both online and analytic intelligence are critical to business success, we extend the same level of systems dependability and data insight to both use cases#.
This is a disruptive moment in business intelligence, that the same highly available, highly dependable, low latency systems are becoming the bedrock for real time business intelligence. No longer do we push business intelligence into a backwater OLAP system, we bring it directly into the clickstream with analytics and online intelligence merging into the same graph. And since both online and analytic intelligence are critical to business success, we extend the same level of systems dependability and data insight to both use cases#.
While many users of graph databases are using them purely for reasons 1-4 above, some users are after deeper levels of connected insight that leverage the very rich mathematical discipline of graph theory. The graph data model is backed by centuries of work in graph theory, discrete mathematics and disciplines dealing in behavioral analysis (sociology, psychology, anthropology, etc).
This semantically rich, connected data can, of course, be used run classical graph algorithms – like path finding, depth and breadth first search – very rapidly. But it’s also amenable to predictive analysis using techniques from graph theory. For example, given an organizational structure, graph theory allows us to find experts, communication chokepoints, and unstable management structures all by applying a few simple principles (e.g. triadic closure, local bridges, balance) to our data.
And this is made more powerful since those principles have well-known predictive qualities that allow us to model “what-if” kinds of scenarios and see how our organization (or data center network, or trade positions) evolve as we make experimental changes.
Gaining predictive insight using graph theory is particularly straightforward to implement once data is stored and processed in graph databases.
Graph databases are set to be a defining theme for information management. Their model offers impressive expressiveness and unparalleled flexibility and insight, with technology choices that include the mature and dependable. The rapid uptake graph databases will accelerate throughout 2013 and beyond, powering all kinds of solutions from social and recommendations to risk and portfolio management and governance, from data center management to supply chain and logistics and beyond. It’s high time to get your graph on!
Emil Eifrem, CEO of Neo Technology
 Emil is the founder of the Neo4j open source graph database project, which is the most widely deployed graph database in the world. As a life-long compulsive programmer who started his first free software project in 1994, Emil has with horror witnessed his recent degradation into a VC-backed powerpoint engineer. As the CEO of Neo4j’s commercial sponsor Neo Technology Emil is now mainly focused on spreading the word about the powers of graphs and preaching the demise of tabular solutions everywhere. Emil presents regularly at conferences such as JAOO, JavaOne, QCon, and OSCON.
Emil is the founder of the Neo4j open source graph database project, which is the most widely deployed graph database in the world. As a life-long compulsive programmer who started his first free software project in 1994, Emil has with horror witnessed his recent degradation into a VC-backed powerpoint engineer. As the CEO of Neo4j’s commercial sponsor Neo Technology Emil is now mainly focused on spreading the word about the powers of graphs and preaching the demise of tabular solutions everywhere. Emil presents regularly at conferences such as JAOO, JavaOne, QCon, and OSCON.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.