NEWS
NEWS
NEWS
NEWS
NEWS
Hortonworks Inc. Chief Executive Rob Bearden grabs a napkin off the hotel conference room table at the San Jose Marriott and scrawls a bell curve to illustrate the typical adoption pattern for new technologies.
The technologies in question here are Hadoop, a way of storing huge amounts of data across clusters of computers, and related Big Data analysis software sold by Hortonworks and other companies. Just past the curve’s initial ascent, where tech-savvy companies have started buying and the curve arcs upward, Bearden draws an X. That’s his way of showing that mainstream customers are just starting to adopt the software in large numbers — similar to a curve for the enterprise resource planning (ERP) software in the early 1990s that made giants out of Oracle Corp., SAP SE and others. Big Data software, he declares, is “tracking on the exact same route.”

Hortonworks CEO Rob Bearden (Photo: Robert Hof)
Or is it? Big Data technologies led by Hadoop, developed originally by Yahoo to handle its massive Web index, have taken 10 years to get to this point. Yet the largest companies that bought billions of dollars worth of ERP software have yet to crack open big budgets for the new wave of software.
The upshot: It’s not clear when or how the new software, which in alliance with cloud computing has the potential to reinvent every operation inside corporations, will cross the chasm into mainstream use. “This is Big Data’s come-to-Jesus year,” said George Gilbert, an analyst at Wikibon Research, owned by the same company as SiliconANGLE.
Ditto for software companies such as Hortonworks, Cloudera Inc. and MapR Technologies Inc. They’re currently growing fast by selling services, subscriptions to product support, and related software for Big Data systems. Hortonworks, the only public company among them, saw revenues jump 85 percent in the first quarter, to $41.3 million. And Wikibon expects Big Data software and services revenues to grow from $19.1 billion this year to $29 billion in 2018.
But Hortonworks’ first-quarter loss of $65.8 million highlights the challenges these companies face in their implicit quest to become the next Oracle or SAP. The new software industry is dominated by free open source software such as Hadoop, which means their customers hold most of the cards and profits are thin to nil. At the same time, the companies are now getting squeezed by cloud computing companies such as Amazon.com and existing software companies.
There should be plenty of demand. Wrangling huge amounts of data has long been key to businesses such as Yahoo, Google, Facebook, LinkedIn and other Internet companies, which is why they developed many Big Data technologies on their own before making them available via open source software. Now, retailers, manufacturers, advertisers and financial services companies need to corral and analyze data so they can better target customers with offers, track credit card fraud and find the best places to drill for petroleum. “Data is the new oil,” Bearden said in an interview at the company’s recent Hadoop Summit conference (* disclosure below) in San Jose, Calif.
But many customers are finding it tough to put these systems into full production. One problem is, in a sense, too much innovation. That’s partly the nature of open source software, which is developed by decentralized legions of programmers under the Apache Software Foundation. And in many ways, that’s a good thing.
Hadoop and dozens of related open source Big Data software projects such as Spark and Kafka have enabled companies to find value in a wealth of unstructured data such as text, web pages and video. That data used to be thrown away because it couldn’t be stored in traditional databases or analyzed with limited computing power. Not anymore. The new technologies introduced concepts such as creating “data lakes” that can incorporate unstructured data, distributing work across clusters of computers and moving analytics computing close to the data, which still costs a lot of money and time to move around.
But here’s the elephant in the room: All that innovation has also created a welter of overlapping technologies that are complex to set up and costly to administer. Essentially, said Jay Kreps, CEO of Confluent Inc., a startup that sells Big Data software known as Apache Kafka, it’s as if car buyers would have to buy engines, transmissions and steering wheels and build the vehicle themselves. And sometimes the parts aren’t well-made. “Not to be cruel,” Kreps said at a conference in March, “but half the startups on that floor, their technology does not work too well.”
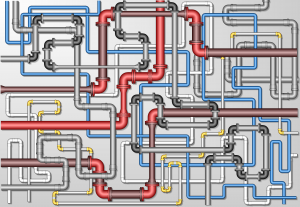
Others are even less tolerant. “It’s a huge frigging mess,” said Andrew Brust, senior director of market strategy and intelligence at analytics and visualization firm Datameer Inc. At a presentation at the Hadoop conference, he showed an impossibly crowded diagram of Big Data companies (shown above) created by FirstMark Capital. There are also multiple software engines and open-source projects, all topped by a numbing array of acronyms and buzzwords. “It’s very hostile to the enterprise buyer because we have so much complexity in the market,” Brust said. “We’re limiting the size of the market.”
Customers say they’d like to see packaged applications akin to Oracle databases or Salesforce.com’s customer relationship management (CRM) service. Yet while companies such as Hortonworks position their software as platforms on which data-driven applications can be built, they each require applications to be written separately for them — unlike Linux, variations of which require little rewriting of applications.
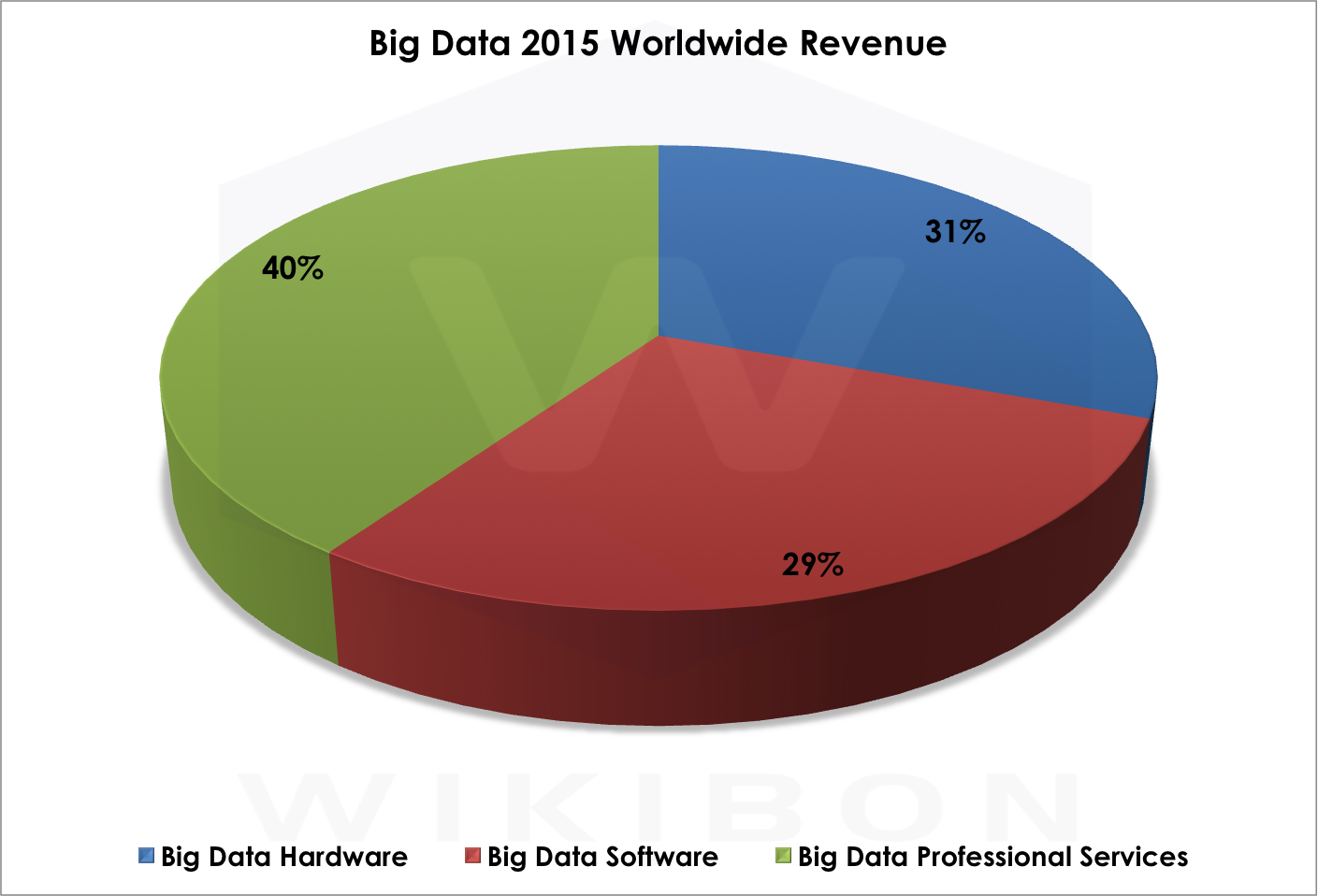
Data: Wikibon
So customers end up having to write their own applications, with disappointing results. Market researcher Gartner Inc. has predicted that even through 2018, 70 percent of Hadoop installations will fail to meet goals for cost savings or revenue generation thanks to lack of in-house skills or proper integration with existing systems. “You don’t get a big market if you rely on customers having Java developers in the basement,” Cloudera cofounder Mike Olson told SiliconANGLE in April.
All that is not entirely new, but it’s now starting to come to a head as mainstream customers remain stuck at the starting gate. According to an analysis by the Big Data CRM company Spiderbook, only 492 U.S. companies have Hadoop systems of significant size, and more than two-thirds of the top 713 customers are tech or advertising tech companies.
“All I get is tools and names, not a solution,” Rakesh Kant, head of enterprise data management and analytics technology at U.S. Bank, griped last week as he waved at a sea of software firms on the Hadoop Summit show floor. “We don’t want to spend time choosing things, we want to deploy them.”
When pressed, software companies acknowledge the problem but attribute it mostly to the need for enterprise buyers, always wary of “ripping and replacing” working systems, to understand the potential of data-driven applications. “It takes time for the entire ecosystem to evolve because we are fundamentally rewriting business models,” said Abhishek Mehta, cofounder and CEO of the analytics startup Tresata Inc. For instance, Big Data technologies enabled LinkedIn to create a new kind of asset, a single location for professional data and talent pools, for which Microsoft recently bid more than $26 billion.
There is some evidence of breaks in the logjam. Progressive Insurance, for instance, has created data centers using Hadoop computer clusters to analyze data from its Snapshot device, which tracks clients’ vehicle speed and other behavior to come up with pricing appropriate to each driver. Hortonworks customer CapitalOne Financial Corp. detects transaction fraud using another Apache technology to analyze some 200 million events an hour on its corporate network.
Still, many companies, especially mid-sized ones without enough expertise, may well dispense with the hassle of creating their own systems and hire cloud computing companies to take care of it. Once a company has lots of data residing in the cloud, it makes more sense to let the same cloud provider do the computing on it to avoid the cost and delay inherent in moving data. “Big Data applications will eventually all move to the cloud,” said Slim Baltagi, CapitalOne’s director of enterprise architecture.
That move could still benefit the Big Data software makers, which in some cases are supplying their software to public clouds such as Microsoft Azure. Cloudera Chief Executive Tom Reilly said the company’s public cloud business is growing twice as fast as its overall business, which itself is “roughly doubling,” and public clouds now account for at least 15 percent of its customers’ workloads.
Nonetheless, the cloud providers such as Amazon Web Services also are offering their own alternatives. “The cloud vendors have all really upped their game,” said Mike Gualtieri, an analyst with Forrester Research. As a result, added Wikibon’s Gilbert, “the very services that define the core of Hadoop are being swapped out.”
Traditional enterprise computing companies have started to swoop in, too. IBM, for instance, says it has invested some $1 billion in Spark, a fast-emerging technology that allows companies to process live streams of data.
All this suggests that it won’t be long before customers start demanding more complete solutions from fewer companies. That’s likely to mean some companies won’t survive the inevitable industry consolidation.
“This is the point in markets when the flight to quality begins,” said Merv Adrian, Gartner’s vice president of research. The Big Data pioneers and startups need to up their own game if they want to keep leading the software industry’s next big wave and avoid getting crushed by it.
* Disclosure: TheCUBE, owned by the same company as SiliconANGLE, was the exclusive media partner at Hadoop Summit. Sponsors have no editorial control over content on theCUBE or SiliconANGLE.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.