



 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Hadoop is adrift.
Last year we all knew what Big Data in the enterprise meant. It meant Hadoop and it was riding the crest of a huge adoption wave. Big Data is still riding that wave, but it’s not clear Hadoop is keeping up.
Hadoop’s success has spawned unintended ecosystem consequences. The Hadoop moniker has always applied to a collection of open source Big Data tools that any one of several vendors curated, led by Cloudera, Hortonworks, and MapR. But we’ve seen a tremendous proliferation of similar, innovative open source tools that are creating alternative ecosystems, such as Spark, Kafka, Mesos, S3 and Cassandra, among dozens of others. The rapid surge of this new set of tools threatens to sideline Hadoop as the “Good Housekeeping seal of approval” for the evolving Big Data ecosystem.
Hadoop’s identity crisis is creating challenges for big data professionals, because the ecosystem now encompasses such a broader menu of tools that it waters down the ecosystem’s coherence:
Let’s step back to see what the journey so far can tell us about where we are headed.
Hadoop’s traditional strength has been the flexibility it offered customers. For the first time, customers had a do-it-yourself approach to assembling analytic data pipelines from open source components. At the same time, no single organization developed all the components. That freewheeling governance approach and customer demand catalyzed remarkable growth in the number and quality of Big Data tools from which the Hadoop vendors could curate the collection of tools they distributed.
When we were at Hadoop Summit in San Jose in 2015, the “Big Three Hadoop” distro vendors — Cloudera, Hortonworks and MapR — had mostly established a pretty broad consensus around what should be included in a Big Data management platform. Even as attention began shifting away from MapReduce, Hadoop’s core for all use cases was still comprised of HDFS and YARN. Each Hadoop distro vendor also included another 20 to 30 Apache projects that made each of the distro’s pretty similar. Finally, the distro vendors added management tools to help integrate all these components that had been developed with no central coordination. Big Data pros generally understood what each piece did and how it worked with the other pieces, even if the distros were still rather unwieldy.
Jump forward to Hadoop Summit 2016 several weeks ago.
The proliferation in open source Big Data software products has only accelerated. And that’s a problem. The tenuous consensus that the Big Three defined about just what belongs in Hadoop that is dissolving.
As a result, customers are getting confused. The proliferation of technologies is generating new marketing terms faster than new technology, applications, or customers. We heard it over and over from customers at Hadoop Summit: We’re losing the ability to assemble a coherent analytic data pipeline by choosing from the plethora ecosystem components. And that’s destroying the “mix-and-match” value proposition that got the Hadoop ball rolling to begin with.
Hortonworks, which reports its second-quarter earnings today, sure seems to see this tidal wave approaching. The company told us they were going to be more prescriptive in defining how to choose the right components for each use case. And in recognizing that big data is now no longer limited to Hadoop, they announced that future conferences would be called Dataworks rather than Hadoop Summit. But most important, the industry also needs a vendor to lead a consensus around a new platform to rationalize the ecosystem’s growing chaos.
So what exactly is “sparking” the proliferation of Big Data products?
“A Mighty Flame Followeth A Tiny Spark”
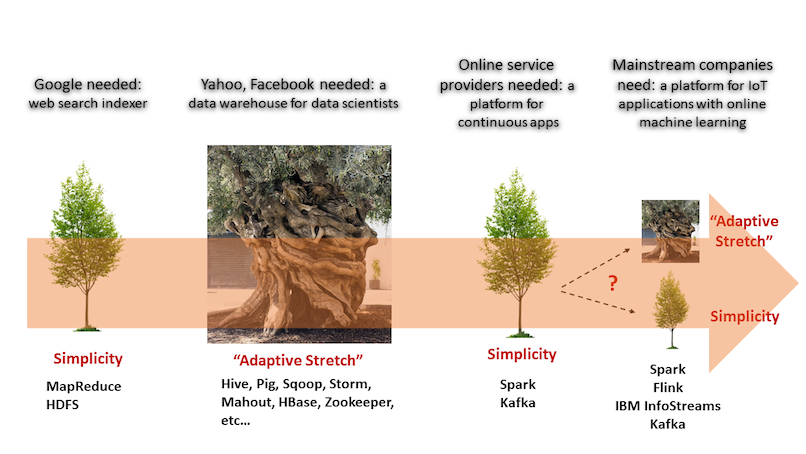
Dante clearly didn’t have Hadoop in mind when he penned those words, but that’s where we are today. Hadoop had modest beginnings: Yahoo! and Google used it as a simple, focused product designed to index web pages for search. But the Big Three realized that Hadoop could be more than that and set themselves up as custodians of the open source Hadoop platform for data-rich applications.
Let’s take a closer look at how and why that consensus around Hadoop’s definition is breaking down now. Spark, which enables continuous processing of data, is rapidly replacing the batch processing MapReduce as the default execution engine in Hadoop. Spark opened up entirely new use cases for Hadoop. It became possible to build continuous processing functionality with advanced analytics rather than just having streaming functionality as an adjunct to batch processing.
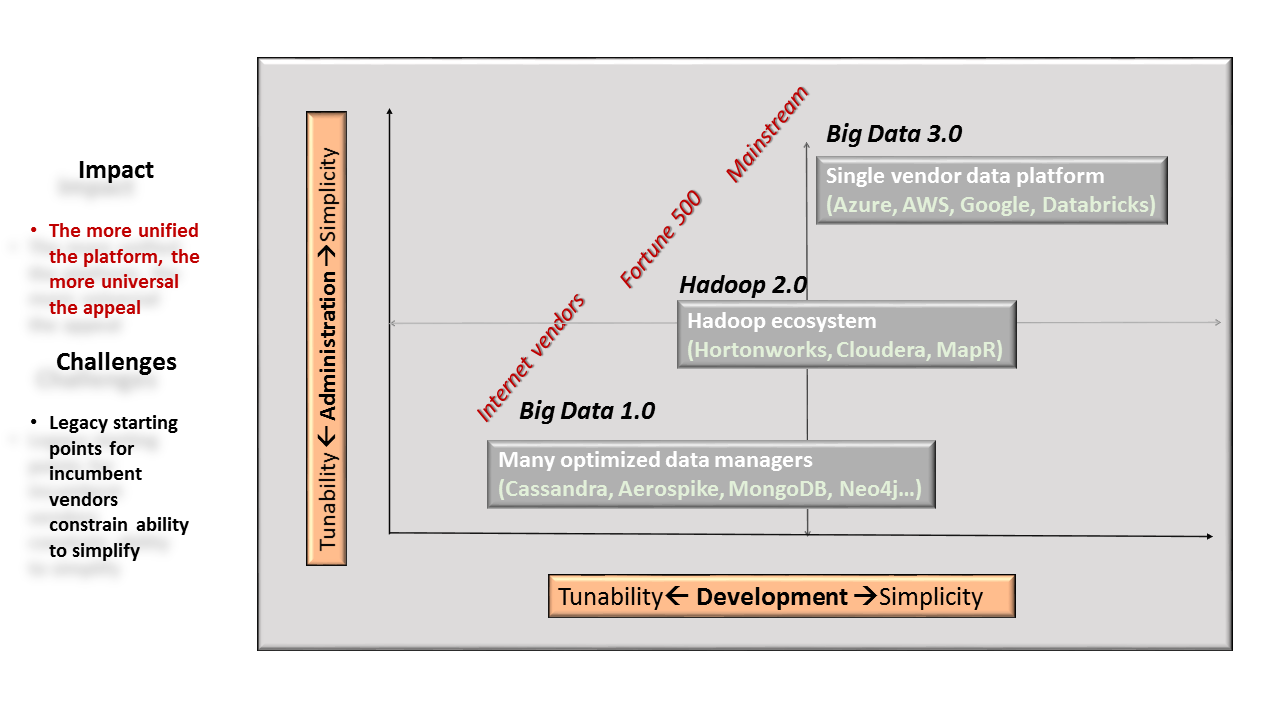
Big data tools span a spectrum of “tunability” or specialization versus simplicity and integration. Hadoop vendors’ competition isn’t each other but Big Data 3.0 cloud services.
Ironically, Spark’s breadth made it possible to form the core platform around which orbited an entirely new ecosystem of tools for building big data-rich applications. Rather than HBase, use Cassandra. Rather than YARN, use Docker containers and Mesos or Kubernetes. Rather than Flume, use Kafka. And, rather than HDFS, the ultimate “cockroach-as-survivor” technology, use S3 or just about any commodity object store.
All this innovation has left administrative and developmental complexity in its wake. Mainstream enterprises, unable or unwilling to hire the scarce, necessary and expensive skills, are increasingly looking to Amazon, Microsoft and Google, as well as other vendors building on their services or infrastructure, to deliver “as-a-service” simplicity.
These cloud vendors also have their own take on analytics-as-a-service in addition to Hadoop. Today, customers can choose to run Hadoop hosted in these vendors’ clouds and swap in some specialized, proprietary functionality, such as elastic data ingest with Amazon’s Kinesis Firehose or a library of machine learning APIs on Azure. Over time, we expect the cloud vendors to provide much deeper integration among their proprietary services. If customers are willing to give up open source software, the cloud vendors will likely offer the development and administrative simplicity of a big data analytics suite designed, built, tested, operated and delivered as a unit.
If traditional Hadoop vendors want to compete within this rapidly growing ecosystem, they need to do more than curate a collection of tools. They need to create a coherent platform that hides the administrative and development complexity of the profusion of tools.
George Gilbert is Big Data & analytics analyst for Wikibon Research.
THANK YOU




