 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Talend Inc. is joining the parade of data integration suppliers that are courting their own users as data stewards.
The winter release of the company’s Talend Data Fabric integration platform, which is being announced today, includes features that Talend calls “self-service for the data citizen.” The company says they enable business people to do many basic data cleansing, merging and certification tasks on a self-service basis. Talend is also introducing a collaboration platform for teams of people working together on projects as well as an intuitive, self-service data stewardship application that helps companies avoid fines and penalties caused by data integrity problems.
Integration vendors have been courting business users aggressively as big data projects move into the mainstream. Pentaho Corp. recently added in-line data visualization features to its platform with the idea of making the data integration process more iterative. At around the same time, Tibco Software Inc. added a personal automation toolset that enables non-technical users to orchestrate multiple cloud platforms.
Talend is responding to the same demands. “Traditionally the developer did the validation through tools that were very technically oriented,” said Ashley Stirrup, Talend’s chief marketing officer. “Now we’re providing the tools to do the same things in a way that’s familiar to a business person.”
Talend isn’t suggesting that automation is about to make data scientists obsolete, but Stirrup said many basic data preparation tasks don’t require Ph.D.-level skills. The company says it’s applying machine learning to match raw data to a customer’s business vocabulary so that the machine can “learn” from user actions and automate more parts of the data quality process as it goes along.
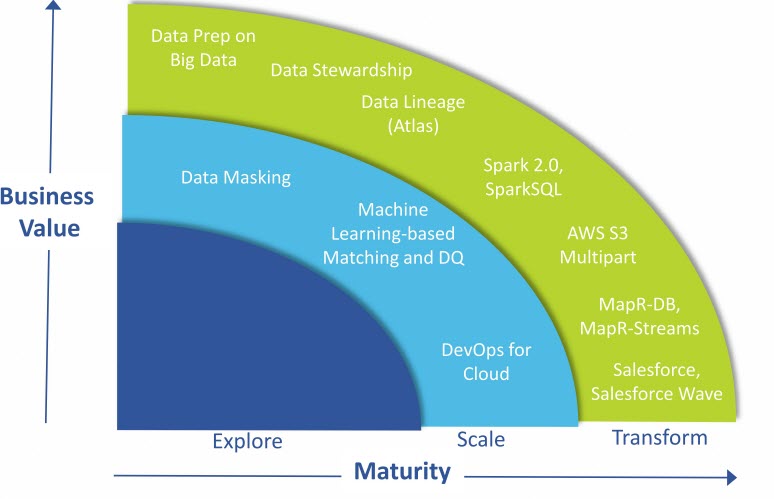
Specifically, the platform enables users to access source data from Hadoop, cloud and traditional databases and share it with other users and groups. They can run preparations at scale using Spark 2.0 and Hadoop. A pre-configured data dictionary can automatically recognize the meaning of the raw data from the data lake, as well as extend to accommodate specific vocabularies. Finally, the platform enables new data definitions to be crowd-sourced from open data sources and the Talend community
In addition to merging and matching data, users can resolve basic errors, arbitrate discrepancies data and define new rules, Talend said. Examples of the basic data cleansing functions available with drag-and-drop tools include filtering on state codes, changing case, merging and deleting rows and removing surplus spaces. These functions may sound mundane, but they are the kinds of data quality problems that can frustrate ambitious projects.
With this release, Talend is also adding support for Apache Spark 2.0 to existing back-end integration with engines from MapR Technologies Inc., Hortonworks Inc., Cloudera Inc., Salesforce.com Inc. and Amazon Web Services Inc. Users can run data preparation in Spark and access any data source in the Hadoop ecosystem, as well as relational sources through a Java Database Connectivity connector (above).
The data preparation process works at a high level, enabling users to “take advantage of technology in any of these platforms without worrying about whether it’s the latest and greatest,” Stirrup said. “Switching form Spark 1.6 to 2.0 is transparent. They can move form Cloudera to Amazon without recoding.”
The new collaboration platform enables people involved in data preparation to orchestrate process by creating workflows, defining roles, assigning tasks and attaching tags and comments, Talend said. They can perform such tasks as managing rejected elements, embedding human certification and error resolution into the master data management processes and delegating decisions that can’t be processed automatically.
The new features are included in the basic Talend user license. Existing customers will get two free self-service licenses with their Talend subscription.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.