NEWS
NEWS
NEWS
NEWS
NEWS
When Hurricane Sandy slammed into New Jersey on Oct. 29, 2012, flooding streets and subways several feet deep, the news also hit engineers at Facebook headquarters in Silicon Valley hard — in a very different way.
“Hurricane Sandy was a wakeup call,” said Jay Parikh (pictured), Facebook’s vice president and head of engineering and infrastructure. Although Facebook’s two data center complexes in North Carolina and Virginia were fine, engineering leaders suddenly realized that could change on the whim of a storm front — and that they needed to prepare ways to keep a billion people online in the event of a natural disaster.
That’s when Project Storm was born. Facebook created the SWAT team of about two dozen leaders of various Facebook technologies to marshal the entire engineering team for storm drills to stress-test its entire network to be prepared in the event that various data center regions go dark.
Though Parikh has previously revealed that Facebook does this unusually bold brand of shutdown to test the network’s resiliency, he used the code-name Project Storm for the first time at the company’s third annual @Scale conference in San Jose Wednesday. The event is a gathering of programmers, engineers and executives at companies, some such as Google that are Facebook rivals in other endeavors, that all create and use open source software to create massive “hyperscale” data centers for Internet services and corporate networks.
In his keynote and later in an interview with SiliconANGLE during the conference, Parikh revealed a wealth of details about Project Storm, providing a window into how one of the Internet’s most popular services strives to keep its users online.
“We’re solving unprecedented problems, problems that are not being solved elsewhere in the industry,” said Parikh. Facebook’s service deals in traffic in the tens of terabits a second, tens of megawatts of power, and thousands of software services. “Every day is chock-full of lots and lots of scale problems for us. So we need to build a resilient set of services.”
Facebook really, really doesn’t want its users to suffer even a split-second lag in retrieving their friends’ cat photos, least of all on account of a drill. So after a lot of planning, Facebook ran many mini-drills to see what impact “draining” or unplugging traffic from various data centers would have on traffic and user experience. (The drills didn’t actually involve turning off electricity to the servers, which could damage them permanently.)
The company uncovered various unexpected issues in traffic management, load balancing and other systems and worked on making sure they didn’t happen again. But finally, in 2014, the team decided it had to take the final step of taking down a data center region for real.
Even then, another senior executive couldn’t believe they were actually going to do it, Parikh recalled. But he was adamant. “You have to send the message to the entire company that you care about scale and resiliency,” he said, even when you might discover, for instance, that a new product may debut during the drill.
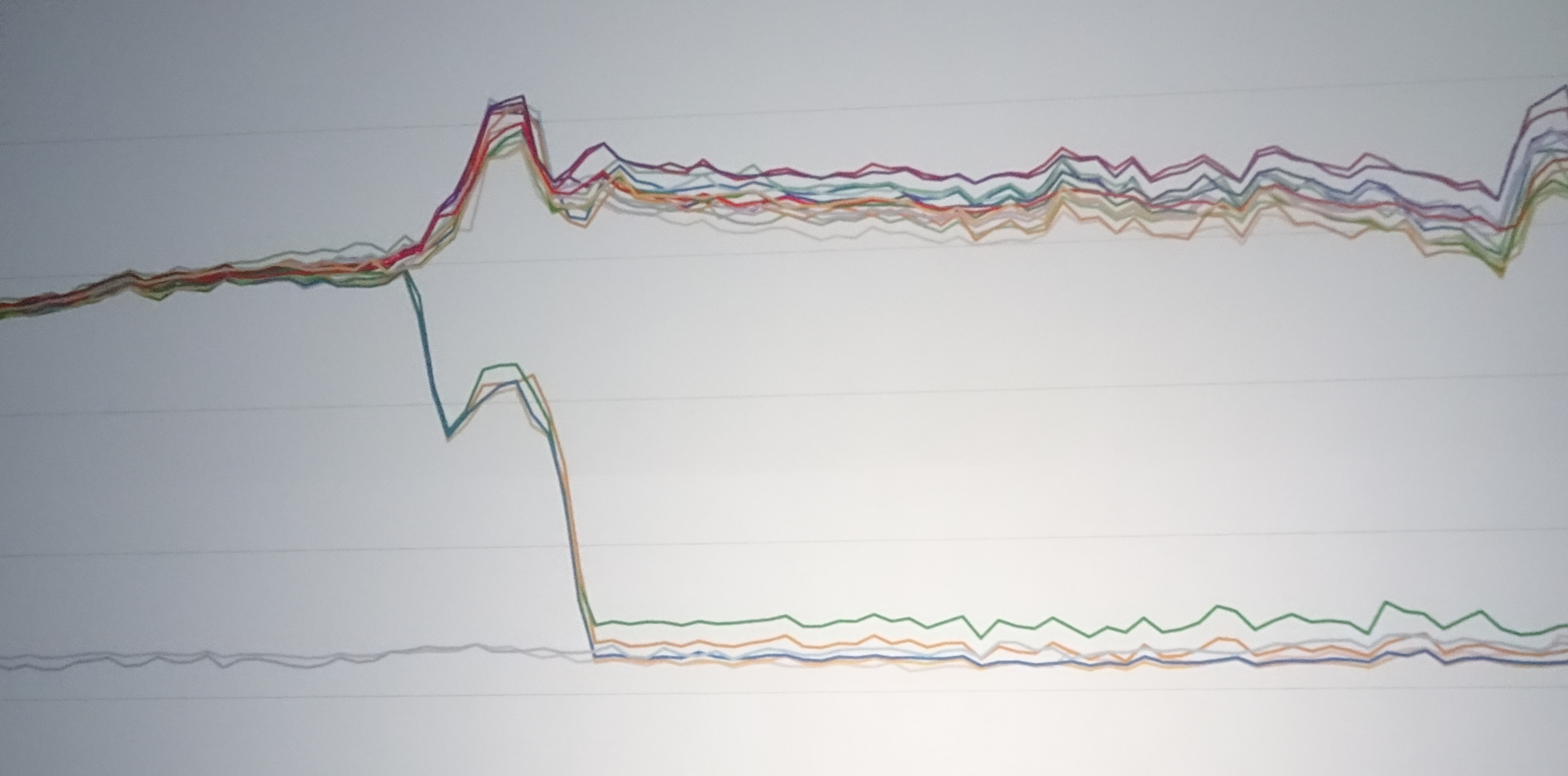
In any case, the first big drill wasn’t pretty, and neither was the following one. To the team’s credit, Parikh said, users almost certainly didn’t notice any issues. But behind the scenes, “there was a bunch of stuff that broke.” Indeed, the following chart shows the resulting haywire traffic loads on various software systems, shown on the Y axis:

If you’re an engineer and you see a graph that looks like that, he said, there are three possibilities: You’ve got bad data, your control system is not working right, or you have no idea what you’re doing.
After making a lot of fixes, they ended up with a steadier control system, in which the traffic moves smoothly, with fewer spikes, from the drained systems to the other systems:
Project Storm continues today, and in fact the team is doing drills more often as well as trying out new kinds of failures, though Parikh didn’t offer specifics for competitive reasons. The team measures what happens during each drill and times itself on each task. “We find surprises all the time,” he said.
The company now has an automated “runbook” for each step needed to turn a data center off or on. Getting data centers back up and running also takes a lot longer than bringing them down, he said, just as it’s easier for a child to disassemble a toy than to put it back together.
Despite its purpose in preparing for disasters, Project Storm has helped Facebook learn more about the everyday workings of its data center setup, which Parikh said is so complex that “there isn’t one person at Facebook who understands how the whole system works.”
Perhaps even more important than technical fixes, he said, is repeated communications to everyone in the company. Even the staff restocking kitchens in Facebook’s Menlo Park, CA headquarters knew about upcoming drills because of signs on walls, he said. But for one drill, the team neglected to notify other offices, so they were taken aback when they saw traffic issues.
The ultimate result of Project Storm, he said, is that “we have a better understanding of where things are going to break.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.