 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
A machine learning “pipeline” – similar to the pipeline for traditional business intelligence – is emerging. It should, in theory, enable developers to pick components off of a “Chinese menu” of building blocks, writes George Gilbert, big data & analytics analyst at the research firm Wikibon, a sister company of SiliconANGLE.
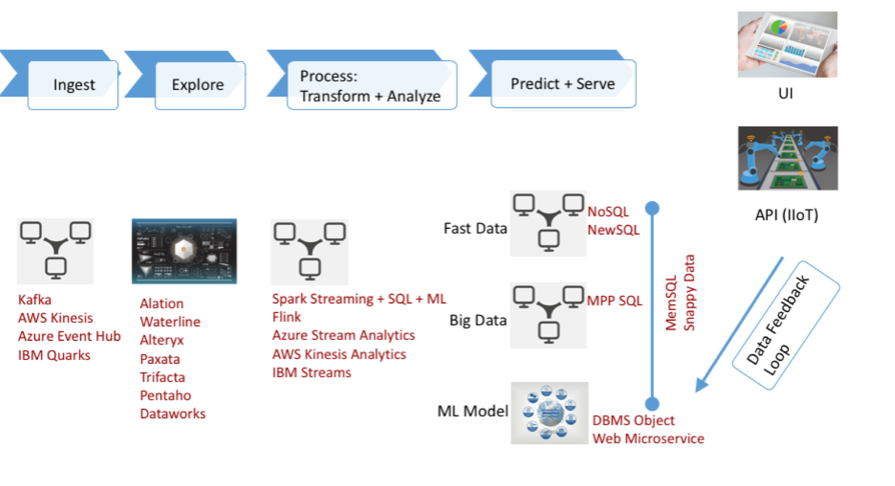
This pipeline (left) has four basic links: ingest, explore, process, transform and analyze-and-predict. In the abstract, they are similar to the steps in traditional business intelligence. However, they don’t map completely.
In BI, for example, the ingest stage involves a complex, extract, transform and load, or ETL, process to support answering pre-determined questions. In the machine learning process, however, data is loaded directly into a data lake in its native format.
This moves much of the complexity to the exploration phase, where the data must be rationalized, enriched and its sources and destinations identified. Processing refines the data. Finally, predictive analytics is the least mature part of the pipeline and the part that provides most of the business value.
In the full Research Alert, Gilbert discusses each step in detail. Wikibon Premium subscribers can read it here. To find out about becoming a Wikibon subscriber, look here.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.