















 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
For all the business benefits of big data, the big problem is that mainstream enterprises have had to fit together many pieces of software and services themselves, causing many to choke on the complexity. That’s the problem Databricks Inc. aims to solve with its new Delta data warehouse announced on Oct. 25.
Delta highlights the big data industry’s shift to offering a new set of solutions that integrate and simplify what used to require mix-and-match assembly. Databricks originally positioned Delta, the new data warehouse for its Spark-based online service, against Snowflake’s online data warehouse.
But that positioning is just to provide a rough approximation of where Delta’s functionality fits. The bigger issue is that Databricks and others are increasingly offering an end-to-end integrated platform for big data and machine learning in an attempt to reduce the complexity of trying to manage big-data infrastructure from the open-source community on-premises.

Figure 1: There is typically a tradeoff between integrated simplicity and sophisticated but more complex best-of-breed functionality.
Ever since the emergence of big data software, vendors and customers feasted on a cornucopia of rapidly advancing, open-source mix-and-match tools. That approach worked really well for sophisticated, tech-centric enterprises. Mix-and-match typically offers either best-of-breed functionality or highly specialized capabilities not available elsewhere (Figure 1, above). The dozens of Apache projects that the Hadoop vendors each curated differently in their distributions best typifies this approach.
But do-it-yourself approaches come with tradeoffs. For one, having customers fitting the pieces together places a greater burden on developers and administrators. Highly sophisticated customers such as big consumer internet companies, telcos and banks had the skills to work with these tools. But others are struggling.
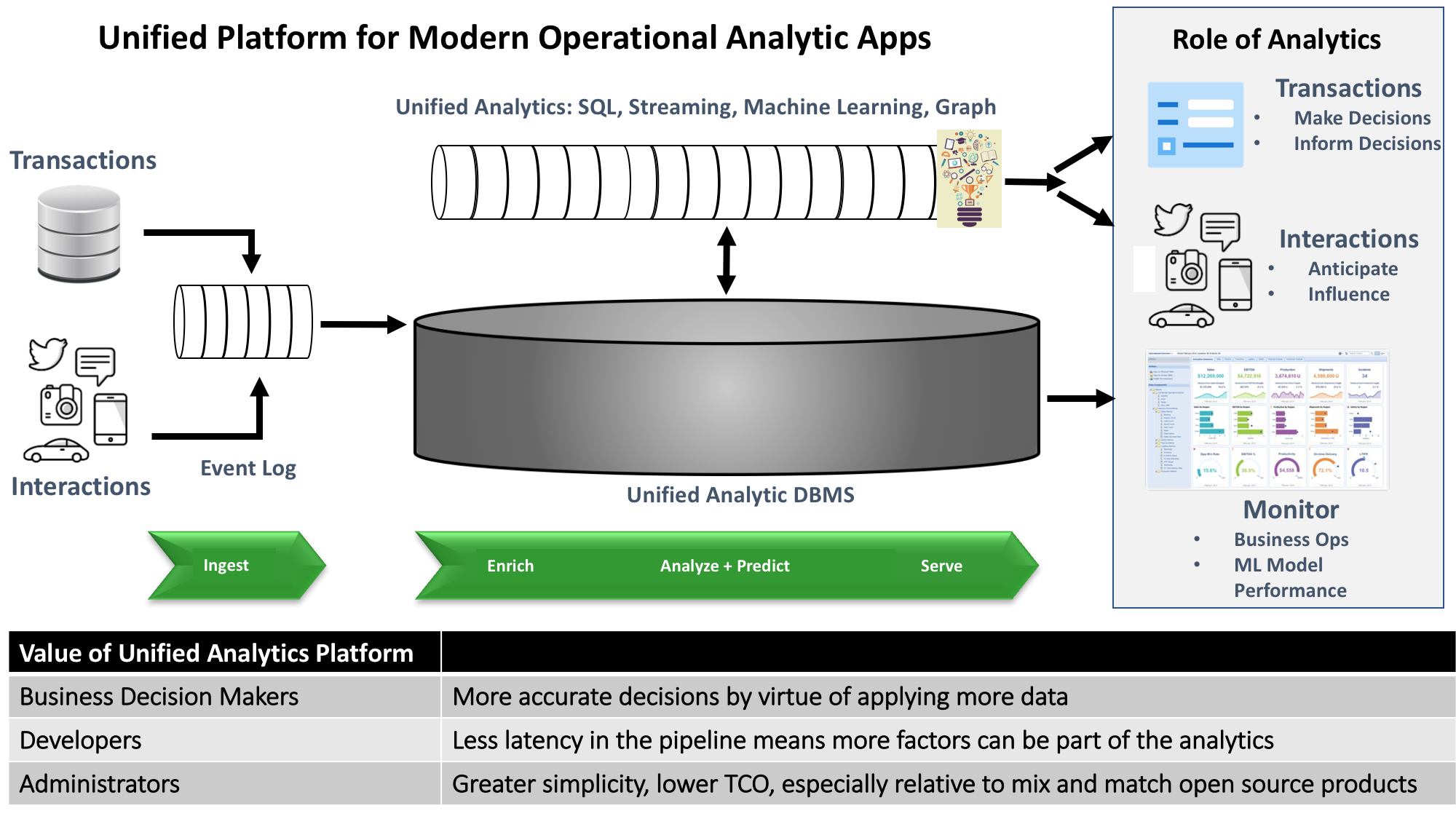
Figure 2: Unified platforms for modern operational analytics applications remove the mix-and-match burden on developers and administrators.
Applications or platforms featuring end-to-end integration typically appeal to mainstream customers that don’t have the skills or risk appetite to take on DIY projects. With Delta as part of the Databricks platform, customers continue to have Spark for one unified analytic engine that features streaming analytics, SQL access, machine learning and graph queries (Figure 2, above). But what Delta delivers is a single analytics database to go with the unified analytics engine.
Crucially, with an integrated engine, different analytic computations work collaboratively on a single dataset without having to move it among extract/transform/load data transformations, streaming analytics, SQL queries and machine learning prescriptions. Similarly, with an integrated analytics database, that same data set stays in one database rather than moving from a data lake to a data warehouse to yet another database to inform decisions that need to happen with low latency.
This level of integration in a unified analytic engine and database has compelling benefits for several different customer constituencies:
| Customer role | Benefits of end-to-end analytic platform integration |
| Line of business owner | Line-of-business owners can get more accurate decisions to inform business transactions or influence end-user interactions. |
| Developer | More accurate prescriptions comes from having lower-latency analytics that can feed more contextual information into a machine learning model in a fixed amount of time. Integrated analytics can deliver lower latency by performing all the compute and storage functions in one place. There’s no need to move the data between different analytic processes or storage engines. |
| Administrator | End-to-end integration greatly simplifies management relative to a platform with many moving parts. Delivering that integrated platform as a SaaS service further simplifies admin requirements. |
In order to understand the tradeoffs between the integrated and best-of-breed approaches, let’s walk through how best-of-breed components fit together (Figure 3, below). A product that supports streaming ingest such as Kinesis or Kafka would deliver claims data to two analytic pipelines to check for fraud, one for speed and one for higher accuracy. Developers could choose Flink for speed and S3 for higher volume of information that supports higher accuracy. Developers could enrich the Amazon S3 data with historical and other contextual information in batch mode with Hive or Presto. The resulting, refined data could be transferred to a data warehouse or other highly curated database management system for analytic performance.
At the same time, Flink might look up some reference data and make a prediction whether an item of data is a fraudulent claim. Flink’s prediction might come with a lower confidence because it’s based on less data so that it can return an answer in near-real-time. Another machine learning model would periodically review all the claims in the data warehouse. The predictions based on the claims in the data warehouse would have a higher confidence level because they could take more factors into account with the extra time. With this approach, developers can optimize each pipeline for just the functionality and results they need.
However, the pipelines would have multiple programming and admin models. And the data would also have to move between different stages in the analysis as well as between data stores, typically adding latency. It’s important to remember that the Hadoop and Big Data 2.0 approaches don’t necessarily solve the integration problem. I described some of those challenges in a previous article.
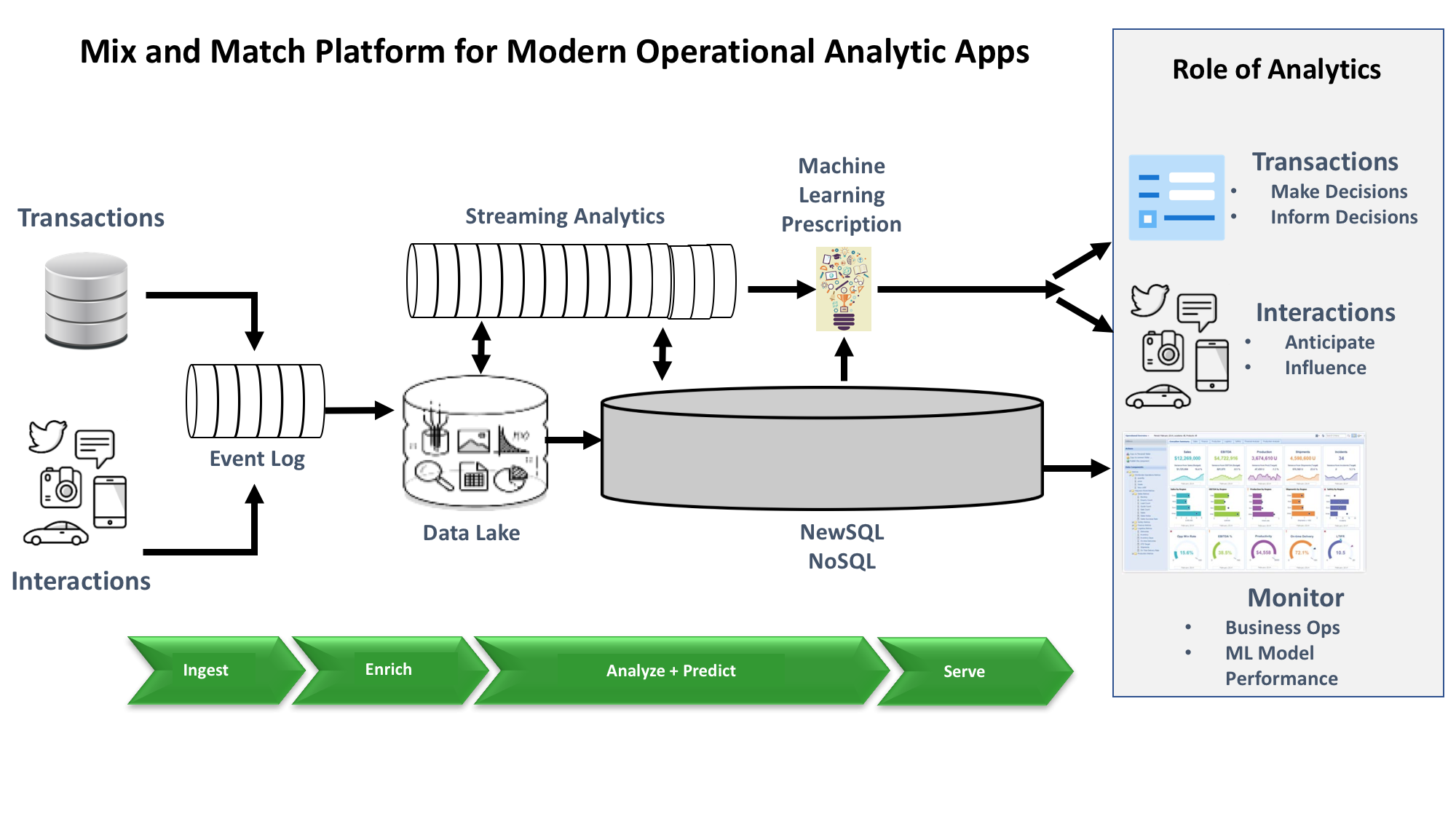
Figure 3: A best-of-breed approach to building modern operational analytics applications requires integrating mix-and-match components. This approach also makes it easier to choose specialized functionality that closely matches a project’s needs.
But few vendors have cracked the code on getting to a sustainable scale on the go-to-market side of the business. Freemium offerings based on hybrid open-source or online services enable developers to discover and try new products via self-service channels. Developers typically also provide the initial design win in a first project. Vendors’ inside sales groups are an ideal low-cost channel to expand the initial design win into new projects.
But getting to enterprise-wide adoption requires engaging with senior IT or line-of-business decision makers. That type of engagement has traditionally required an enterprise sales force augmented by sophisticated value-added resellers and systems integrators. And enterprise sales forces are the most expensive migratory workforce in the world. Even vendors with a billion dollars in revenue find it challenging to achieve comprehensive global account coverage. The industry still needs innovation in go-to-market models to solve this coverage problem.
An upcoming report for Wikibon research will compare vendor-specific approaches to the simplicity-versus-sophistication tradeoff and their customer application sweet spots.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





