BIG DATA
BIG DATA
BIG DATA
BIG DATA

BIG DATA
Peter Drucker, an early pioneer and leader in the field of management education, famously wrote that “the purpose of business is to create a customer.” His 20th century business philosophy has carried into the digital age with a new twist. Drucker might be more tempted to say that the purpose of business today is to use data to acquire a customer, a challenge that has become more apparent as the capture, storage and analysis of information becomes everything in the enterprise.
Deriving value from data and then putting it to good use in the business world has become the holy grail of success and a key predictor of whether a company will rise or fall. The formula for success thus becomes based on how effectively the enterprise world can build its own system for harnessing true data value. To draw from another famous Drucker quote, “The best way to predict the future is to create it.”
The business strategy for putting data to work has been the focus of significant research by the team at Wikibon Inc., and an analysis of where the big data community is going and how it will get there was recently presented at the BigData SV event in San Jose, California. Inevitably, the journey will depend on the technology and how it is used.
“We have to build new capabilities for how we’re going to apply data to perform work better,” said Peter Burris (@plburris, pictured), host of theCUBE, SiliconANGLE Media’s mobile livestreaming studio, and chief research officer and general manager of Wikibon research, during a presentation at BigData SV. “How you create value out of data … is going to drive your technology choices.”
Those choices are going to be driven by a few significant numbers, said Burris. The first data point is $103 billion, which represents expected global big data hardware, software and services revenue by 2027, from about $40 billion this year. The key word here is services.
“The services business is going to undergo enormous change over the next five years as services companies better understand how to deliver big, data-rich applications,” Burris said.
The second key number is 2017, the year that the software market surpassed hardware in big data. Hardware isn’t going away, but the shift represents an important move towards finding new ways of software-driven data movement and analysis.
“How do I make data available to other machines, actors, sources of process within the business?” Burris mused. “Architect your infrastructure and your business to make sure the data is near the action in time for the action to be absolute genius for your customer.”
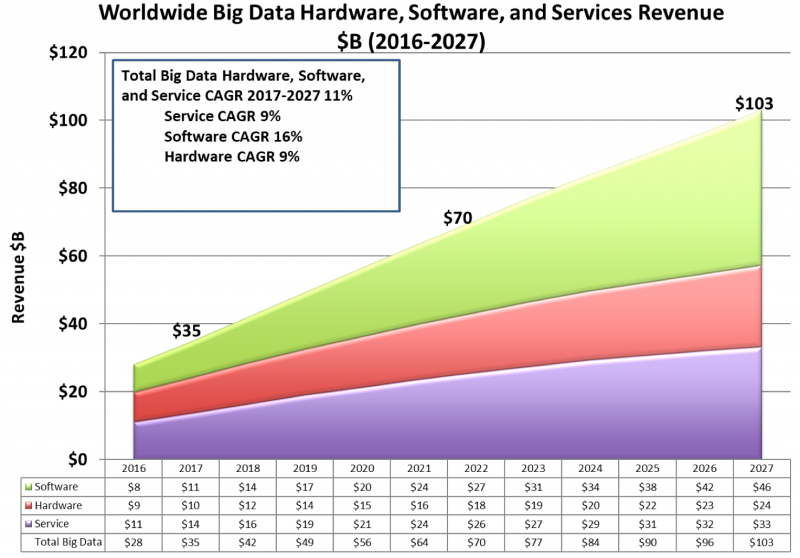
Worldwide big data hardware, software, and services revenue 2016-2027, in billions of dollars (Source: Wikibon)
The third key number is 68 percent, the “other” category in the current distribution of total big data and analytics revenue. The next largest shares in this sector are owned by IBM Corp., Splunk Inc. and Dell Technologies who collectively add up to only 15 percent. “It’s a very fragmented market … a highly immature market,” Burris explained. “In four years, our expectation is that 68 percent is going to start going down pretty fast as we see greater consolidation.”
The final number is 11 percent, representing Splunk’s share of the big data and analytics software revenue share of the market among leading vendors. That’s what the numbers show, but what are the trends behind these key data points?
Splunk’s share at 11 percent offers one clue. The company has built its $1.2 billion business on the search, monitoring and analysis of data through pre-packaged applications. The combination of mounds of data growing at an exponential rate and a lack of data scientists to make sense of it all will result in greater enterprise reliance on public cloud vendors and other suppliers for pre-trained models in packaged applications.
“[Splunk] takes a packaged application, weaves these technologies together, and applies them to an outcome,” Burris said. “We think this presages more of that kind of activity over the course of the next few years.”
The surge by software in 2017 also highlights an area of change in the enterprise computing approach, which will redefine hardware’s role. Wikibon’s research shows that technologies are being developed and woven into UniGrids, universal systems organized to share all compute resources based on any business data. The use of non-volatile memory express over fabrics will be a key element as requests for proposals are increasingly being written for scalable hardware.
“We believe pretty strongly that future systems are going to be built on the concept of how to increase the value of data assets,” Burris said. “All of the piece parts are here today, and there are companies which are actually delivering them.”
How about that monster 68 percent in the “other”company category for total big data and analytics revenue? Part of the explanation lies in the continued development of what Wikibon labels agency zones (cloud, hub or edge zones defined by latency) and networks of data where movement of information to the right area becomes critical.
IBM, Splunk, Dell, Oracle and Amazon Web Services are still leaders, but there is a whole ecosystem of companies seeking to define new technologies for the enterprise in the fragmented big data market. As firms grapple with the demands of channeling value from data, information technology organizations will look more closely at emerging technologies, such as blockchain, to find solutions.
“All of us have a pretty good idea of what the base technology is going to be,” said Burris, describing the continued migration to the cloud. “Technologies like blockchain have the potential to provide an interesting way of imagining how these networks of data actually get structured.”
Wikibon’s latest findings offer yet another chapter in the continuing saga of a complex digital world. The stewards of this transformation should be data scientists, but there is the not-so-small problem of scale. This is driving companies to seek artificial intelligence and various automated solutions.
“Tens of billions of [people and devices] are dependent on thousands of data scientists,” Burris said. “That’s a mismatch that cannot be sustained.”
With data playing such a central role in digital transformation, it is putting even more pressure on business to find creative solutions, leveraging some technologies that are still in nascent stages. Some work, some don’t, and constant change is inevitable. It’s a challenge for the ages, or as Drucker himself once put it many years ago, “The entrepreneur always searches for change, responds to it and exploits it as an opportunity.”
Here’s the complete video interview below, and there’s much more of SiliconANGLE’s and theCUBE’s coverage of the BigData SV event.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.