BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
A new era of data is upon us.
The technology industry generally and the data business specifically are in a state of transition. Even our language reflects that. For example, we rarely use the phrase “big data” anymore. Rather we talk about digital transformation or data-driven companies.
Many have finally come to the realization that data is not the new oil — because unlike oil, the same data can be used over and over for different purposes. But our language is still confusing. We say things like “data is our most valuable asset,” but in the same sentence we talk about democratizing access and sharing data. When was the last time you wanted to share your financial assets with your co-workers, partners and customers?
In this Breaking Analysis we want to share our assessment of the state of the data business. We’ll do so by looking at the data mesh concept and how a division of a leading financial institution, JPMorgan Chase, is practically applying these relatively new ideas to transform its data architecture for the next decade.
As we’ve previously reported, data mesh is a concept and set of principles introduced in 2018 by Zhamak Dehghani, director of technology at ThoughtWorks Inc. She created this movement because her clients, some of the leading firms in the world, had invested heavily in predominantly monolithic data architectures that failed to deliver desired results.

Her work went deep into understanding why her clients’ investments were not delivering desired results. Her main conclusion was the prevailing method of trying to force our data into a single monolithic architecture is an approach that is fundamentally limiting.
One of the profound ideas of data mesh is the notion that data architectures should be organized around business lines with domain context. That the highly technical and hyperspecialized roles of a centralized cross-functional team are a key blocker to achieving our data aspirations.
This is the first of four high-level principles of data mesh, specifically:
No. 3 is one of the most significant and difficult to understand. Most discussion around data value in the past decade have centered around using data to create actionable insights: Data informs humans so they can make better decisions. We see this as a necessary but insufficient condition for successful data transformations in the 2020s. In other words, if the end game is better insights we see that as an important but evolutionary extension of reporting. Rather, we believe that building data products that can be monetized – either to cut costs directly or, more importantly, generate new revenue, as the more interesting (and now attainable) target goal.
There’s lots more to the data mesh concept and there are tons of resources on the Web to learn more, including an entire community that has formed around data mesh. But this should give you a basic idea.
One other notable point is that in observing Zhamak’s work, she has deliberately avoided discussions around specific tooling, which has frustrated some folks. Understandably, because we all like to have references that tie to products and companies. This has been a two-edged sword in that on the one hand, it’s good, because data mesh is designed to be successful independent of the tools that are chosen. On the other hand, it has led some folks to take liberties with the term data mesh and claim “mission accomplished” when their solution may be more marketing than reality.
We were really interested to see just this past week, a team from JPMC held a meetup to discuss what it called “Data Lake Strategy via Data Mesh Architecture.” We saw the name of the session and thought, “That’s a weird title.” And we wondered if they are just taking their legacy data lakes and claiming they’re now transformed into a data mesh?

But in listening to the presentation the answer is a definitive “No – not at all.” A gentleman named Scott Hirleman organized the session that comprised the three JPMC speakers shown above: James Reid, a divisional chief information officer, technologist and architect Arup Nanda and information architect Sarita Bakst.
This was the most detailed and practical discussion we’ve seen to data about implementing a data mesh. And this is JPMC. We know it was an early Hadoop adopter, an extremely tech-savvy company, and it has invested probably billions in the past decade on data across this massive company. And rather than dwell on the downsides of its big data past, we were pleased to see how it’s evolving its approach and embracing new thinking around data mesh.
In this post, we’re going to share some of the slides they used and comment on how it dovetails into the concept of data mesh as we understand it, and dig a bit into some of the tooling that is being used by JPMorgan, specifically around the Amazon Web Services cloud.
JPMC is in the money business and in that world, it’s all about the bottom line.
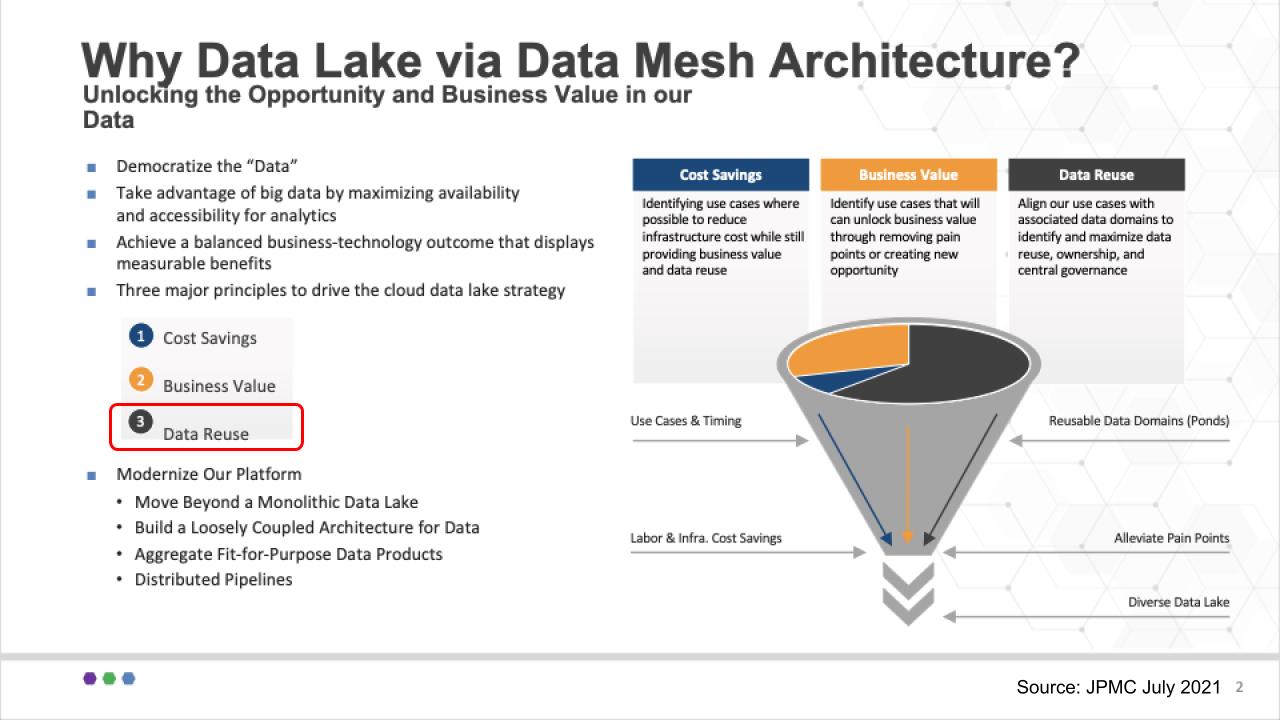
James Reid, the CIO, showed the slide above and talked about the team’s overall goals, which centered on a cloud-first strategy to modernize the JPMC platform. He focused on three factors of value: No. 1: Cutting costs – always, of course. No. 2: Unlocking new opportunities or accelerating time to value. And we really like No. 3, which we’ve highlighted in red: Data re-use as a fundamental value ingredient. And his commentary here was all about aligning with the domains, maximizing data reuse and making sure there’s appropriate governance.
Don’t get caught up in the term data lake – we think that’s just how JP Morgan communicates internally. It’s invested in the data lake concept – and it likes water analogies at JPMC. They use the term data puddles for example, which are single-project data marts and data ponds which comprise multiple puddles that can can feed into data lakes.
As we’ll see, JPMC doesn’t try to force a single version of the truth by putting everything into a monolithic data lake. Rather, it enables the business lines to create and own their own data lakes that comprise fit-for-purpose data products. And it uses a catalog of metadata to track lineage and provenance so that when it reports to regulators, it can trust that the data it’s communicating are current, accurate and consistent with previous disclosures.
JPMC is leaning into public cloud and adopting agile methods and microservices architectures, and it sees cloud as a fundamental enabler. But it recognizes that on-premises data must be part of the data mesh equation.
Below is a slide that starts to get into some of the generic tech in play:
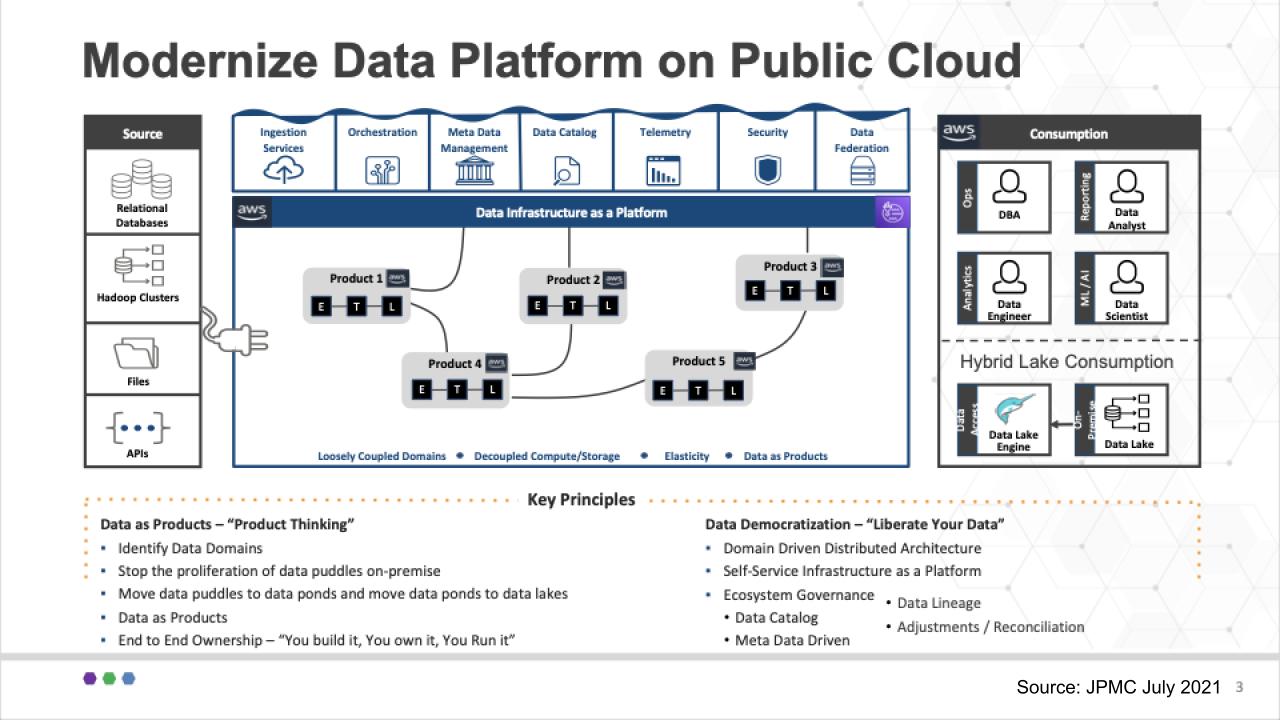
We’d like to make a couple of points here that tie back to Zhamak Deghani’s original concept.
The first is that unlike many data architectures, this diagram puts data as products right in the fat middle of the chart. The data products live in business domains and are at the heart of the architecture. The databases, Hadoop clusters, files and APIs on the left hand side serve the data product builders.
The specialized roles on the right-hand side – the DBAs, data engineers, data scientists and data analysts serve the data product builders. Because the data products are owned by the business they inherently have context. This is nuanced but an important difference from most technical data teams that are part of a pipeline process but lack business and domain knowledge.
And you can see at the bottom of the slide, the key principles include domain thinking and end-to-end ownership of the data products – build, own, run/manage.
At the same time, the goal is to democratize data with self-service as a platform.
One of the biggest points of contention on data mesh is governance and as Sarita Bakst said on the meetup “metadata is your friend.” She said, “This sounds kinda geeky” – but we agree, it’s vital to have a metadata catalog to understand where data resides, the data lineage and overall change management.
So to us, this passed the data mesh stink test pretty well.
The presenters from JPMC said one of the most difficult things for them was getting their heads around data products. They spent a lot of time getting this concept working. Below is one of the slides they used to describe their data products as it related to their specific segment of the financial industry:
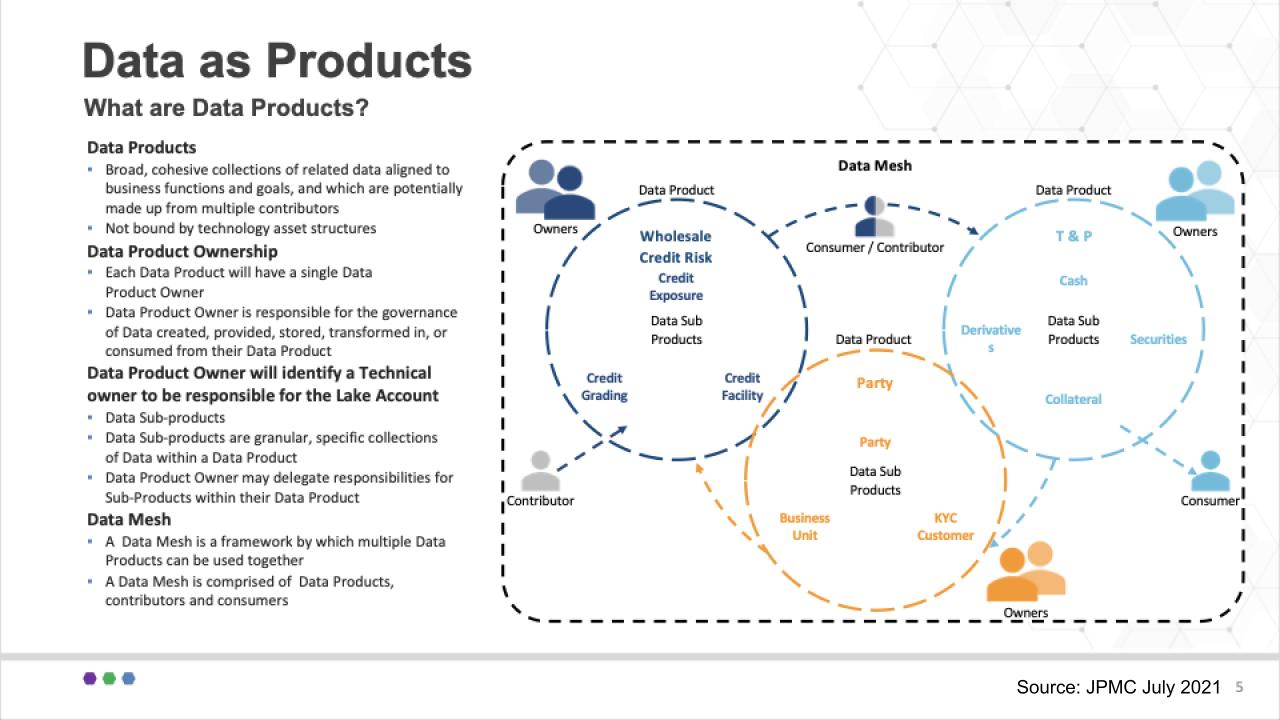
The team stressed that a common language and taxonomy is very important in this regard. It said, for example, it took a lot of discussion and debate to define what is a transaction. But you can see at a high level, three product groups around Wholesale Credit Risk, Party, and Trade and Position Data as Products. And each of these can have subproducts (e.g. KYC under Party). So a key for JPMC was to start at a high level and iterate to get more granular over time.
Lots of decisions had to be made around who owns the products and subproducts. The product owners had to defend why that product should exist, what boundaries should be put in place and what data sets do and don’t belong in the product — and which subproducts should be part of these circles. No doubt those conversations were engaging and perhaps sometimes heated as business line owners carved out their respective turf.
The team didn’t say this specifically, but tying back to data mesh, each of these products, whether in a data lake, data hub, data pond, data warehouse or data puddle, is a node in the global data mesh.
Supporting this notion, Sarita Bakst said this should not be infrastructure-bound; logically, any of these data products, whether on-prem or in the cloud, can connect via the data mesh.
So again we felt like this really stayed true to the data mesh concept.
This chart below shows a diagram of how JPMorgan thinks about the problem from a technology point of view:
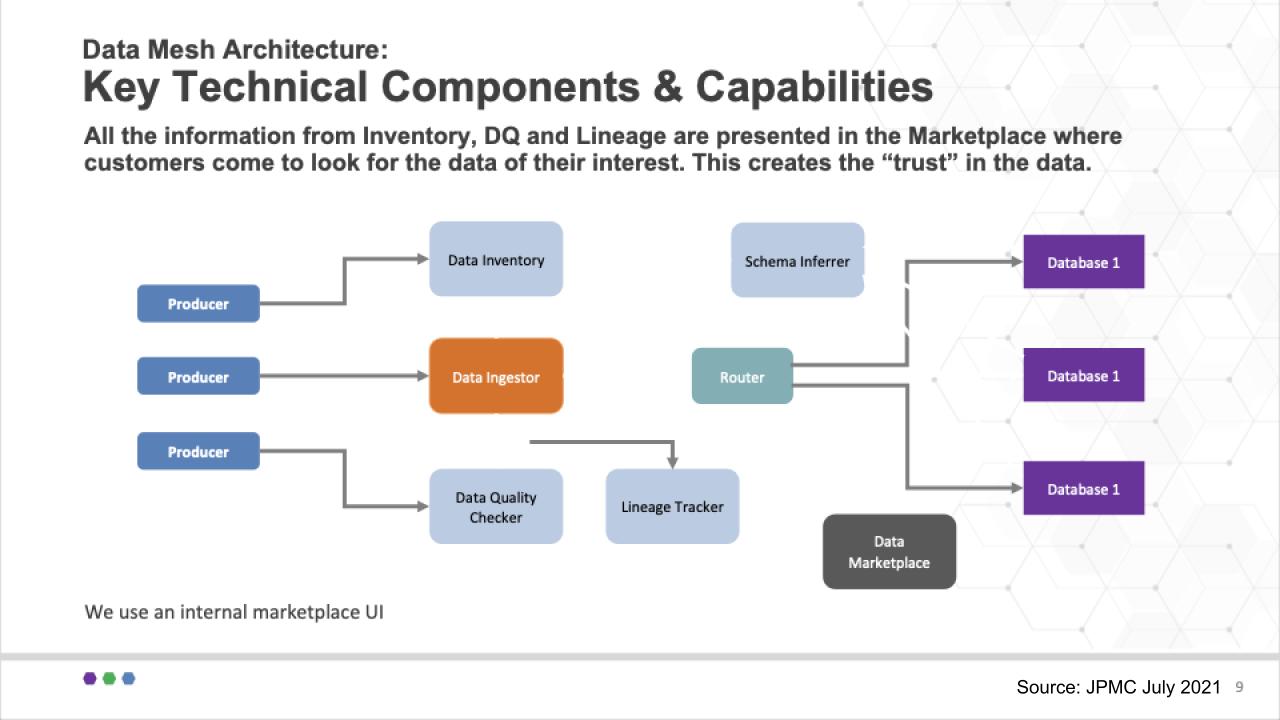
Some of the challenges JPMC had to consider was how to write to various data stores, can you/how can you move data from one data store to another? How can data be transformed? Where is data located? Can the data be trusted, how can it be easily accessed, who has the right to access the data? These are problems that technology can solve.
To address these issues, Arup Nanda explained that the heart of the slide above is the Data Ingestor (versus ETL or extract/transform/load). All data producers/contributors send data to the Ingestor. The Ingestor then registers the data so it’s in the data catalog, it does a data quality check and it tracks the lineage. Then data is sent to the router, which persists the data based on the best destination as informed by the registration.
This is designed to be flexible. In other words, the data store for a data product is not pre-determined and fixed. Rather it’s decided at the point of inventory and that allows changes to be easily made in one place. The router simply reads that optimal location and sends it to the appropriate data store.
The Schema Inferrer is used when there is no clear schema on write. In this case the data product is not allowed to be consumed until the schema is inferred and settled. The data in this case goes to a raw area and the Inferrer determines the proper schema and then updates the inventory system so that the data can be routed to the proper location and accurately tracked.
That’s a high-level snapshot of some of the technical workflow and how the sausage factory works in this use case. Very interesting and worth technical practitioners watching at least the technical section of this 83-minute video, which starts around 19 minutes in.
Now let’s look at the specific implementation on AWS and dig into some of the tooling.
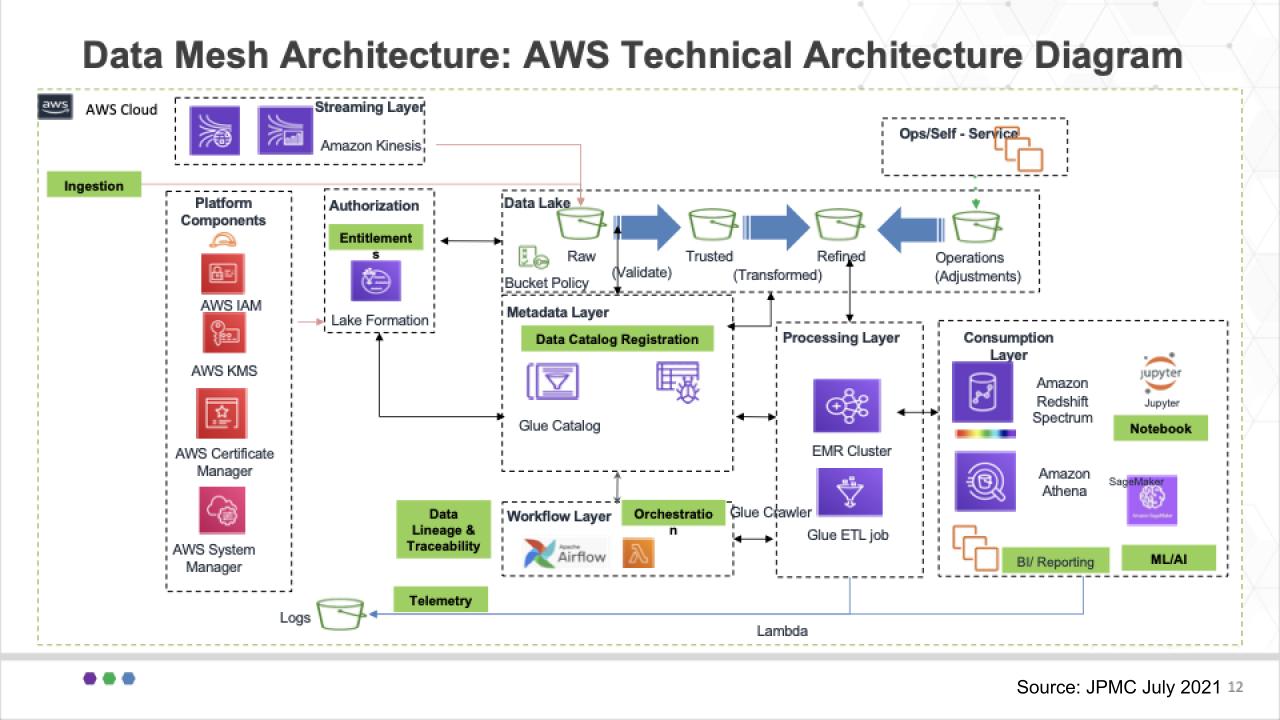
As described in some detail by Arup Nanda, the diagram above shows the reference architecture used by this group at JPMorgan. It shows all the various AWS services and components that support their data mesh approach.
Start with the Authorization block right underneath Kinesis. The Lake Formation is the single point of entitlement for data product owners and has a number of buckets associated with it – including the raw area we just talked about, a trusted bucket, a refined bucket and a bucket for any operational adjustments that are required.
Beneath those buckets you can see the Data Catalog Registration block. This is where the Glue Catalog resides and it reviews the data characteristics to determine in which bucket the router puts the data. If, for example, there is no schema, the data goes into the Raw bucket and so forth, based on policy.
And you can see the many AWS services in use here, identity, the EMR cluster from the legacy Hadoop work done over the years, Redshift Spectrum and Athena. JPMC uses Athena for single threaded workloads and Redshift Spectrum for nested types that can be queried independently of each other.
Now remember, very importantly, in this use case, there is not a single lake formation, rather multiple lines of business will be authorized to create their own lakes and that creates a challenge. In other words, how can that be done in a flexible manner to accommodate the business owners?
Note: Here’s an AWS-centric blog on how they recommend implementing data mesh
JPMC applied the notion of federated lake formation accounts to support its multiple lines of business. Each line of business can create as many data producer and consumer accounts as they desire and roll them up to their master line of business lake formation account shown in the center of each block. And they cross connect these data products in a federated model as shown below.
These all roll up into a master Glue Catalog as shown in the middle of the diagram so that any authorized user can find out where a specific data element is located. This superset catalog comprises multiple sources and syncs up across the data mesh.
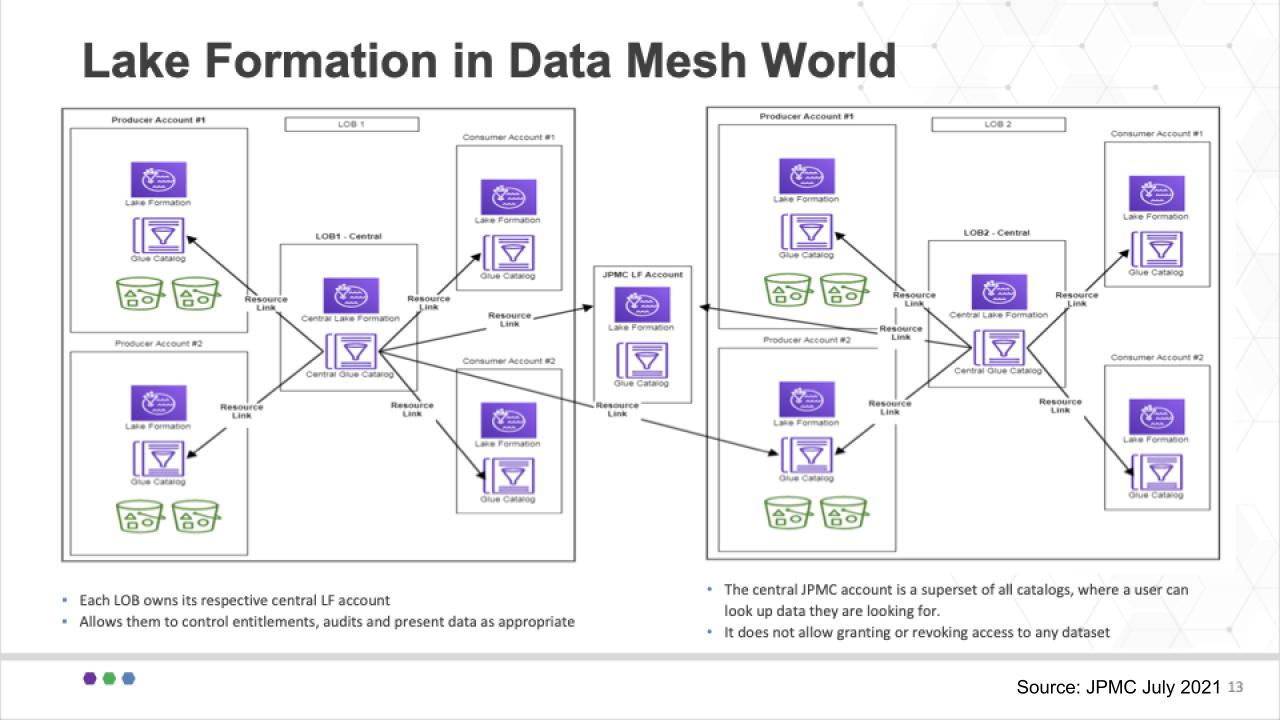
So again this to us was a well thought out and practical application of data mesh. Yes it includes some notion of centralized management but much of that responsibility has been passed down to the lines of business. It does roll up to a single master catalog and that is a metadata management effort and seems compulsory to ensure federated and automated governance.
Importantly, at JPMC, the office of the chief data officer is responsible for ensuring governance and compliance throughout the federation.
Let’s take a look at some of the suspects in this world of data mesh and bring in the ETR data.
Now, of course, ETR doesn’t have a data mesh category – and there’s no such thing as a data mesh vendor; you build a data mesh, you don’t buy it. So what we did is used the ETR data set to filter certain sectors to identify some of the companies that might contribute to the data mesh to see how they’re performing.
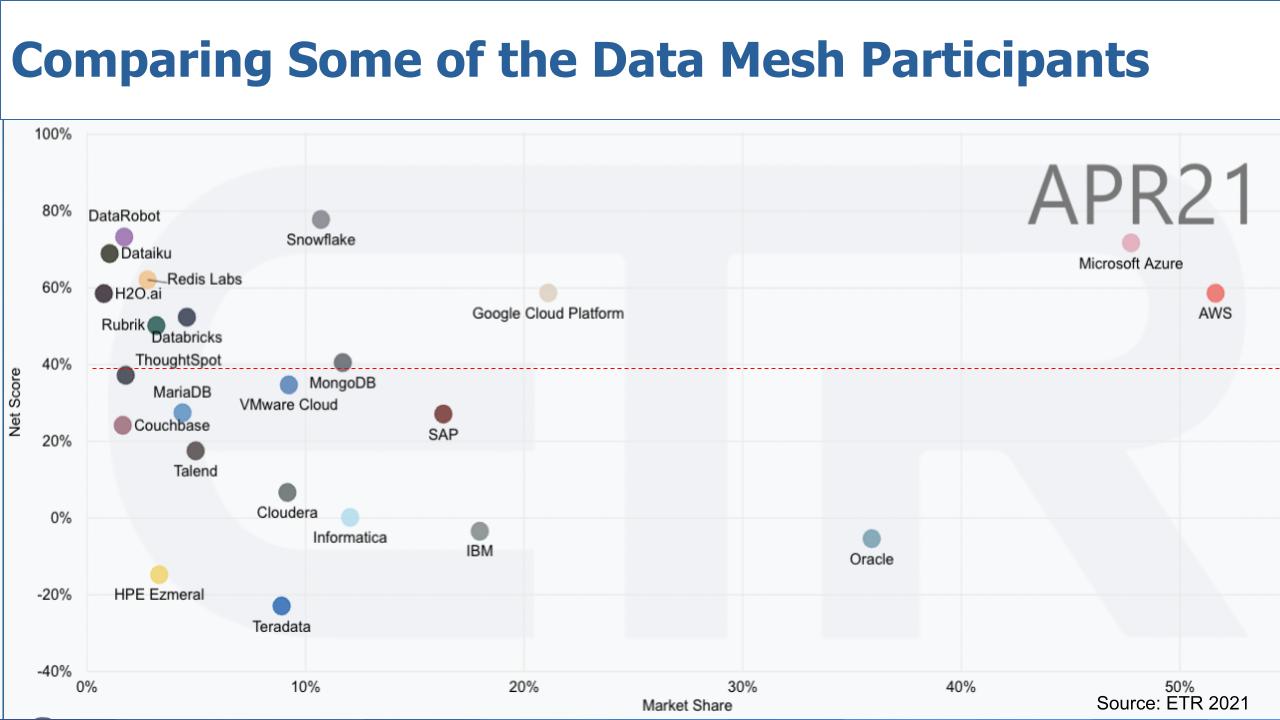
The chart above depicts a popular view we often like to share. It’s a two-dimensional graphic with Net Score or spending momentum on the vertical axis and Market Share or pervasiveness within the data set on the horizontal axis. And we’ve filtered the data on sectors such as analytics, data warehouse, etc, that reflected participation in data mesh.
Let’s make a few observations.
As is often the case, Microsoft Azure and AWS are almost literally off the charts with high spending velocity and a large presence in the market. Oracle Corp. also stands out because much of the world’s data lives inside Oracle databases – it doesn’t have the spending momentum, but the company remains prominent. You can see Google Cloud doesn’t have nearly the presence, but its momentum is elevated.
Remember, that red dotted line at 40% indicates our subjective view of what we consider a highly elevated spending momentum level.
Snowflake Inc. has consistently shown to be the gold standard in Net Score and continues to maintain highly elevated spending velocity in the Enterprise Technology Research data set. In many ways Snowflake with its data marketplace, data cloud vision and data-sharing approach fits nicely into the data mesh concept. Snowflake has used the term data mesh in its marketing, but in our view it lacks clarity and we feel like it’s still trying to figure out how to communicate what that really is.
We don’t see Snowflake as a monolithic architecture, but it’s marketing sometimes uses terms that allow one to infer legacy thinking. Our sense is this is actually customer-driven. What we mean is Snowflake customers are so used to monolithic architectural approaches and because Snowflake is so simple to use, it “paves the cowpath” and applies Snowflake to its legacy organizational structures and ways of thinking.
In reality, the value of Snowflake, in the context of data mesh, is the ability quickly and easily to spin up (and down) virtual data stores and share data across the Snowflake data cloud with federated governance. Snowflake’s vision is to abstract the underlying complexity of the physical cloud location (that is, AWS, GCP or Azure) and enable sharing across the globe, within its governed data cloud. Ideally it minimizes the need to make copies to share data (notwithstanding sometimes copies are necessary for latency considerations).
The bottom line is we actually think Snowflake fits nicely into the data mesh concept and is well-positioned for the future.
Databricks Inc. is also interesting because the firm has momentum and we expect further elevated levels on the vertical axis as it readies for IPO. The firm has a strong product and very good managed service. Initially, everyone thought Databricks would try to be the Red Hat of big data and build a service around Spark.
Rather, what it has done is build a managed service, with strong artificial intelligence and data science chops, and is taking the data lake to new levels. It is one to watch for sure and on a collision course with Snowflake in our view. We need to do more research but have always believed Databricks fits well into a federated data mesh approach.
We included a number of other database companies for obvious reasons – such as Redis Labs Inc., MongoDB Inc., MariaDB Inc., Couchbase and Teradata Corp. There’s also SAP SE; it’s not all HANA for SAP, but it’s a prominent player in the market, as is IBM.
Cloudera Inc., which includes Hortonworks Inc. and Hewlett Packard Enterprise Co.’s Ezmeral, which comprises the MapR business that HPE acquired. These include some of the early Hadoop deployments that are evolving. And of course Talend SA and Informatica Corp. are two data integration companies worth noting.
And we also included some of the AI/machine learning specialists and data science players in the mix like DataRobot, which just did a monster $250M round, Dataiku, H2O.ai and ThoughtSpot, which is a specialist using AI to democratize data and fits very well into the data mesh concept, in our view.
And we put VMware Inc. cloud in there for reference because it really is the predominant on-prem infrastructure platform.
First, thanks to the team at JPMorgan for sharing this data. We really want to encourage practitioners and technologists to go watch the YouTube video of that meetup. And thanks to Zhamak Deghani and the entire data mesh community for the outstanding work they do challenging established conventions. The JPM presentation gives you real credibility and takes data mesh well beyond concept and demonstrates how it can be done.

This is not a perfect world. You have to start somewhere and there will be some failures. The key is to recognize that shoving everything into a monolithic data architecture won’t support massive scale and cloudlike agility. It’s a fine approach for smaller firms, but if you’re building a global platform and a data business it’s time to rethink your data architecture and, importantly, your organization.
Much of this is enabled by cloud – but cloud-first doesn’t mean you’ll leave your on-prem data behind. On the contrary, you must include nonpublic cloud data in your data mesh vision as JPMC has done.
Getting some quick wins is crucial so you can gain credibility within the organization and continue to grow.
One of the takeaways from the JPMorgan team is there is a place for dogma – like organizing around data products and domains. On the other hand, you have to remain flexible because technologies will come and they will go.
If you’re going to embrace the metaphor of puddles, ponds and lakes, we suggest you expand the scope to include data oceans – something we have talked about extensively on theCUBE. Data oceans – it’s huge! Watch this fun clip with analyst Ray Wang and John Furrier on the topic.
And think about this: Just as we are evolving our language, we should be evolving our metrics. Much of the last decade of big data was around making the technology work. Getting it up and running and managing massive amounts of data. And there were many KPIs built around standing up infrastructure and ingesting data at high velocity.
This decade is not just about enabling better insights. It’s more than that. Data mesh points us to a new era of data value, and that requires new metrics around monetizing data products. For instance, how long does it take to go from data product idea to monetization? And what is the time to quality? Automation, AI and very importantly, organizational restructuring of our data teams will heavily contribute to success in the coming years.
So go learn, lean in and create your data future.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com, DM @dvellante on Twitter and comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail. Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
Here’s the full video analysis:
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.