







 AI
AI
AI
AI
AI
Enterprises have spent the last 15 years moving information technology workloads from their data centers to the cloud. Could generative artificial intelligence be the catalyst that brings some of them back?
Some people think so. Interest in natural language processing has exploded since OpenAI LP’s release of the ChatGPT large language model-based chatbot last November. One-third of businesses surveyed by Arthur D. Little Inc.’s Cutter Consortium subsidiary over the summer said they plan to integrate LLMs into their applications and 48% said their plans are uncertain. Just 5% ruled out the possibility.
A survey released last week by marketing strategy and analytics consultancy GBK Collective, the business name of GBH Insights LLC, found that 37% of business leaders use generative AI weekly and 81% have an internal team of at least 10 people focused exclusively on generative AI strategy.
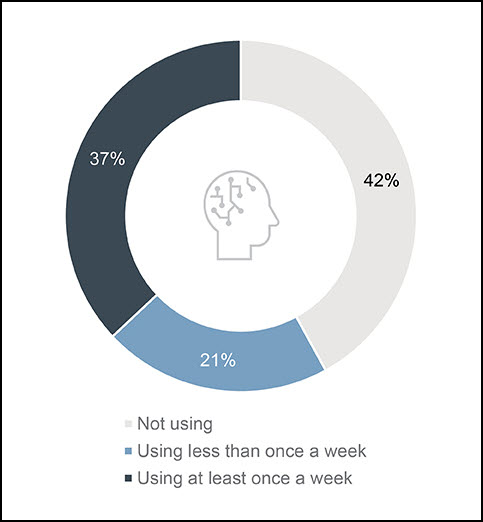
Usage of generative AI by business leaders. Source: GBK Collective
Where the training and fine-tuning needed to adapt LLMs to specific industries and use cases will occur is still an open question. Although cloud providers have scarfed up much of the early business from tire kickers, the tasks of training models for use in a production environment introduce variables that may make local infrastructure more attractive.
Model training and tuning aren’t like conventional IT tasks. Machine learning models must repeatedly churn through large amounts of data – the more, the better. Petabyte-sized data volumes aren’t easily shifted between local data centers and cloud platforms. This “data gravity” issue makes training in-house an attractive option if that’s where the data already lives.
This and other trends in generative AI will be explored Tuesday and Wednesday, Oct. 24-25, at SiliconANGLE and theCUBE’s free live virtual editorial event, Supercloud 4, featuring a big lineup of prominent executives, analysts and other experts.
Training and inferencing are two distinct phases in the life cycle of AI models that serve different purposes. Training teaches the model to recognize patterns and make predictions based on data. Models learn from a labeled dataset and adjust internal parameters to maximize confidence in predictions.
Inferencing applies a model’s learned knowledge to predict or classify new and unseen data. It’s the real-world application of AI.
The two stages have very different data and computation needs. Model training requires a large and labeled dataset of examples with known outcomes that can be used to learn and generalize patterns. It’s a computationally intensive process that typically requires powerful hardware and can last for days or even weeks.
Inferencing doesn’t require a labeled dataset but rather applies the trained model to process new and unlabeled data. It’s far less computationally intensive than training and can often be done on off-the-shelf hardware or specialized gear such as AI accelerators.

Ocient’s Gladwin: “As the volume and complexity of the data grows, keeping it within company infrastructure becomes more cost-effective.” Photo: LinkedIn
Fine-tuning is a technique used to improve the performance of pretrained models for specific tasks. It takes an existing model trained on a large dataset for general-purpose use and adds in some task-specific data. Fine-tuning typically requires fewer training iterations and less time than training a model from scratch.
Bandwidth limitations between local offices and cloud data centers can throttle large-scale model development, particularly with the petabyte-sized datasets that train foundation models such as GPT-4. Transferring massive datasets and model checkpoints can saturate available bandwidth, limiting access to other workloads.
“As the volume and complexity of the data grows, keeping that data within company infrastructure becomes more cost-effective to run training against,” said Chris Gladwin, chief executive of Ocient Inc., a hyperscale data warehouse and analytics startup.
There are also nuances of LLM training that argue against moving the task entirely to the public cloud. One is that the correlation between the performance of the model and the data used to train it isn’t always straightforward. The possibility of inadvertently training models with proprietary or sensitive information – called “data leakage” — is a concern, particularly in regulated industries. Although all cloud providers promise to protect data, the black-box nature of AI models makes it difficult to guarantee that inadvertent exposure will never occur.
Protecting information by redacting it works in a standard regression model where the relationship between variables is well understood but predictive algorithms like those used in LLMs can actually figure out what information is missing and restore it, noted Joe Regensburger, vice president of research at Immuta Inc., which makes a data security platform.
“Redaction may not work because the whole point of the model is to infer about what is missing,” he said. “That makes redaction somewhat fragile. Understanding the training process becomes really interesting.”

Dataiku’s Dougherty: “There’s been a small but growing movement with our clients toward pushback on the cloud.” Photo: SiliconANGLE
“Privacy and protection are primary motivations to keep models on-premises,” said Arun Chandrasekaran, a distinguished analyst at Gartner Inc.
Businesses that are required to keep data in a defined location for regulatory reasons have always struggled with the fluidity of cloud storage, which can move data between regions with a customer’s knowledge. “Cloud can put people in jeopardy because you don’t know where your data is being stored,” Regensburger said. “The data you use to train, tune and prompt models could in theory leave your jurisdiction.”
On-premises training is a better option in four scenarios, said Brandon Jung, vice president of ecosystem at generative AI company Tabnine Ltd.: “when the data is significantly differentiated, there is a significant amount of data, data is changing quickly and the quality of the model makes a big difference in the outcome.”
Local infrastructure has certain performance advantages in inferencing scenarios areas where latency is critical, such as fraud detection and factory floor automation. “If you’re in an autonomous vehicle, you don’t want pedestrian detection in the cloud,” said Evan Sparks, chief product officer for artificial intelligence at Hewlett Packard Enterprise Co.

Gartner’s Chandrasekaran: “Privacy and protection are primary motivations to keep models on-premises.” Photo: Gartner
But LLM training is expensive. The amount of computing required for the most significant AI training projects grew more than 300,000-fold between 2012 and 2018, according to an OpenAI paper. Training ChatGPT on the 175 billion-parameter GPT-3 dataset required a supercomputer outfitted with more than 285,000 central processing unit cores and 10,000 graphics processing units at a reported cost of $3.2 million. Training on the newer GPT-4 model, which has more than 1 trillion parameters, cost more than $100 million, according to OpenAI Chief Executive Sam Altman.
Despite the uncertain cost factors, some suggest that the control inherent in on-premises infrastructure will, over time, trigger a sizable migration of training workloads away from cloud platforms. Others believe the scalability and tooling advantages of the public cloud make it a natural destination for AI training in the long term. Most say it’s too soon to tell.
“There’s been a small but growing movement with our clients toward pushback on the cloud,” said Jed Dougherty, vice president of platform strategy at data science platform Dataiku Inc. “Hosting GPUs in the cloud is surprisingly expensive. More companies will go back to managing their hardware over time.”
Orr Danon, CEO of Hailo Technologies Ltd., which makes processors optimized for AI use, agrees. “If you just need random access once in a while, then you’re better off in the cloud, but if you want the responsiveness and uptime, then you will want to own the infrastructure from a service and cost perspective,” he said.

Information Services Group’s Kelker: “We are expecting a large amount of AI model training to happen on-premises rather than in the cloud.” Photo: ISG
“We are expecting a large amount of AI model training to happen on-premises rather than in the cloud for multiple reasons,” added Prashant Kelker, partner for digital solutions at technology research and advisory firm Information Services Group Inc.
Those reasons include data privacy and compliance assurances and the cost and time required to transfer large volumes of data to and from the cloud. “Industries that need generative AI computation in areas with troubled network connectivity, such as offshore oil rigs, will create micro-data centers for this purpose,” he said.
Kelker added those that need predictable AI computational demands, such as capital markets, will also favor the on-premises approach. “All the above suggests a huge comeback of purpose-built infrastructure in the form of micro-data centers and heavy-duty private cloud,” he said.
Training large models using on-premises servers, GPUs and infrastructure lets organizations customize and optimize training infrastructure specifically for AI workloads and avoid bandwidth constraints that could slow down model development in the cloud. “Even without egress fees, moving 100 petabytes of data to the cloud is next to impossible,” said Anand Babu Periasamy, co-founder and CEO of MinIO Inc., an open-source provider of object storage software. “They’re going to move AI to where data is.”
“It’s expensive to move large quantities of data around, and those costs are difficult to track,” added Kyle Campos, chief technology officer of CloudBolt Inc., maker of a hybrid cloud management platform.

MinIO’s Periasamy: “Moving 100 petabytes of data to the cloud is next to impossible.” Photo: SiliconANGLE
Proprietary algorithms, data and intellectual property remain locally protected, whereas uploading to the cloud carries privacy risks, whether perceived or actual. “The technology is still relatively new, making it challenging to guarantee robust data security [in the cloud]in many instances,” said Fedor Zhdanov, chief scientist at Toloka AI AG, maker of a data-centric environment that supports AI development across the machine learning lifecycle.
“The folks we’re talking to are fixated on having complete control,” said Nima Negahban, CEO of Kinetica DB Inc., the developer of a real-time analytic database for time series and spatial workloads.
Jesse Stockall, chief architect at software asset management firm Snow Software Inc., summed up the deployment dilemma: “The amount of cash that OpenAI is burning through is off-putting to some of the people we talk to,“ he said. On the other hand, he added, “if you’re a born-in-the-cloud startup, it would be crazy to set up a data center and all of the operational overhead that comes with it.“
Provisioning a data center for model training isn’t a trivial task. Hardware costs alone can run into millions of dollars, which doesn’t include the overhead of space, power, cooling and people to manage it. The rapidly growing demand for computing power to train ever-larger models also means equipment becomes outdated more quickly. “The financial commitments of taking a multiyear data center lease that you know you likely won’t want to use in two to three years is untenable,” said J. J. Kardwell, CEO of Vultr, a cloud service of The Constant Company LLC.

Vultr’s Kardwell: “The cost [of GPUs] is so prohibitive that users are much better off consuming them as a service.” Photo: Vultr
On the other hand, uncertainty about intellectual property control, data leakage and the sheer hassle of moving large data sets around will cancel out concerns about higher costs for some companies.
Sensing opportunity, leading computer hardware makers are busily rejiggering their product lines in anticipation of plentiful new opportunities to sell into corporate data centers. Early this month, Dell Technologies Inc. introduced a line of integrated hardware and software, training frameworks and services for customers who want to train and tune their own models. It teamed up with Nvidia on validated designs optimized for training and inferencing use cases in May.
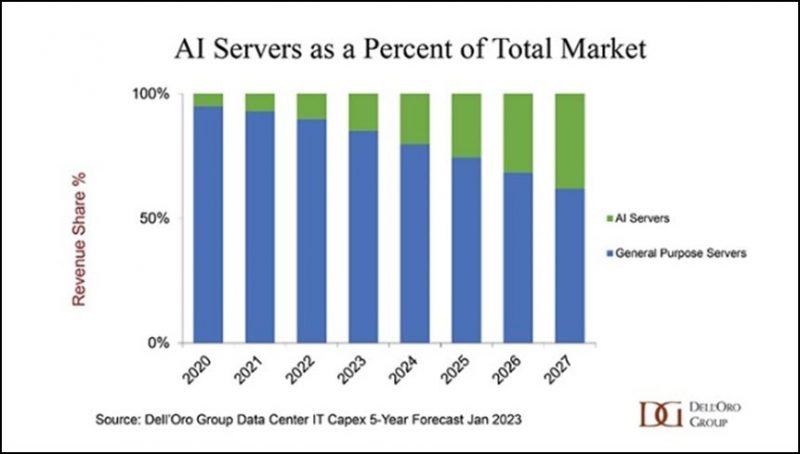
Source: Dell’Oro Group
“Because of the uniqueness of the workload, it’s a growth opportunity, and our customers are signaling to us that they are willing to invest more to ensure they’re getting the full potential of generative AI to transform their businesses,” said Carol Wilder, vice president of infrastructure solutions group at Dell.
HPE is tapping into the supercomputing expertise gained with the purchase of Cray Research Inc. four years ago to launch purpose-built supercomputers for both on-premises and cloud deployment. “Demand has been wild,” said HPE’s Sparks. “Anybody who would have forecast this a year or two ago would have been extremely prescient.” AI is expected to be a significant component of the company’s presence at the Discover Barcelona conference next month.

HPE’s Sparks: “If you’re in an autonomous vehicle, you don’t want pedestrian detection in the cloud.” Photo: HPE
IBM Corp. has been touting a prototype of a new energy-efficient analog processor that can be used for inferencing – or deploying training models – and just launched a suite of offerings for running AI models on mainframes in customers’ data centers.
Dozens of startups and established firms are chasing a burgeoning AI hardware market expected to grow from $8 billion in 2020 to nearly $195 billion by 2030.
AI is remaking the server market. Dell’Oro Group Inc. predicts that by 2027, half of server sales will be accelerated models connected by data center-scale fabrics needed for training and inferencing.
“We’re moving toward more high-density GPU configurations,” said Sparks. “We’ve got multibillion-dollar backlogs for those kinds of servers.“
How much training enterprises want to do is still being determined. Outside of the domain of tech giants, only Bloomberg LP has taken the plunge and built a full-scale LLM. In March, it announced a 50 billion-parameter model trained on more than 700 billion tokens — units of text that a language model reads – over half of which came from its corpus of financial information.
Most experts agreed that Bloomberg’s high-ticket business can justify the cost, but the company is likely to be an exception to the rule.

Domino Data’s Carlsson: “There are few reasons why you’d want to train an LLM from scratch.” Photo: Domino Data Lab
“There are few reasons why you’d want to train an LLM from scratch unless you have a particular use case,” said Kjell Carlsson, head of data science strategy and evangelism at data science firm Domino Data Lab Inc.
“Very few customers will train LLMs anywhere,” agreed Lee Caswell, senior vice president of product and solutions marketing at Nutanix Inc. For those who do, “cloud is getting the bulk of LLM training.”
One scenario is that enterprises will purchase prebuilt LLMs, fine-tune them and deploy them where they make the most sense. Such customization “offers the opportunity to achieve a substantial technological edge over competitors,” said Toloka’s Zhdanov.
That’s what C3 AI Inc. is betting on with its release last month of 28 domain-specific generative offerings aimed at different industries, business processes and enterprise platforms. Each model’s $250,000 price tag includes 12 weeks of training using retrieval-augmented generative AI, a framework for retrieving facts from an external knowledge base that ensures the model has access to the most current information and users know the source of training data.
“This approach helps us separate the LLM from a customer’s proprietary data and avoids many of the downsides of using a consumer-facing generative AI tool in the enterprise context, such as the lack of traceability and hallucination,” said Nikhil Krishnan, C3 AI’s chief technology officer for products.

Dell’s Wilder: Customers are “willing to invest more to ensure they’re getting the full potential of generative AI.” Photo: LinkedIn
ISG’s Kelker believes that “buying foundational models and fine-tuning them with proprietary data will be the go-to approach for most cases. Firms will start with pre-trained models for a solid foundation, with the flexibility to customize to a specific use case.”
Pretrained models don’t fit every use case, however, said Dell’s Wilder. “While a pretrained model is the ‘easy button’ for many processes, it is not suitable for all,” she said. “A third party can’t understand your proprietary information, skills and value better than you can.”
Another option is to train in the cloud and move trained model weights, which are the learned parameters of the LLM that are needed to make predictions or generate text, back to the local infrastructure. “The training is expensive, and the inferencing is cheap,” said Mike Finley, co-founder and chief technology officer of AG Labs LLC’s data analytics platform AnswerRocket. “You stand it up once, and then it’s a matter of how many answers you want to deliver.”
Large models can be trained in the cloud using 32-bit floating-point numbers and redeployed with lower four-bit or eight-bit precision on less powerful data center or edge servers. “The outcome is good enough, and you can run four-bit and eight-bit models on PCs with commodity hardware,” said Domino Data Lab’s Carlsson.

AnswerRocket’s Finley: “The training is expensive, and the inferencing is cheap.” Photo: AnswerRocket
A low-powered on-premises computer could deliver 80% precision at half the cost of running the same model in the cloud with 90% precision. “You have to ask what is the value of the 10% precision increment?” said Eswar Nagireddy, senior product manager of data science at Exasol AG, maker of an analytics database. “Am I getting business value? Are my customers paying me more money?”
LLMs also don’t need to have a GPT-4 scale if their scope is limited, said Cindi Howson, chief data strategy officer at business intelligence software provider ThoughtSpot Inc. “Do I really need 1.7 trillion parameters if I’m looking specifically at healthcare or financial data?” she said. “Why not use smaller LLMs,” such as those from John Snow Labs Inc. or Truveta Inc?

Informatica’s Pathank says moving AI models between cloud and on-premises environments can be frustrated by compatibility issues. Photo: LinkedIn
But moving models back on-premises for inferencing isn’t always simple, particularly if they were trained with a cloud provider’s proprietary machine learning service. Gaurav Pathak, vice president of product management at Informatica Inc., said several issues could complicate moving models trained in the cloud to on-premises infrastructure.
“Cloud and on-prem environments often have different library versions,” he said. “Models are often tightly coupled to the framework with which they were developed, such as TensorFlow and PyTorch.” Moreover, he added, “Hardware compatibility can be a problem if inferencing needs to be done on CPUs or older GPUs on-premises. Additional quantization steps will be required.” Data pipelines, which are the processes that let data flow from one or more sources to a destination, also may need to be revised for the destination.
“If model use is primarily done on-premises, it would make sense to prepare data and train the model on-premises as well,” Pathak said. “Getting large volumes of data to and from the model needs rethinking if cloud storage isn’t available.”
The scarcity of GPUs at the moment is working in favor of cloud providers such as Amazon Web Services Inc., Microsoft Azure and Google Cloud. With their buying power, they can obtain commercially available chips more easily, and all have built or are building their own AI chipsets.

Snow Software’s Stockall: “You can’t go down to your local Best Buy and get industrial-grade GPUs at any scale.” Photo: LinkedIn
“The cost [of GPUs] is so prohibitive that users are much better off consuming them as a service,” said Vultr’s Kardwell. He noted that services such as his offer single- or even partial-GPU options on a pay-as-you-go basis.
Using local infrastructure can limit flexibility and scalability because fixed capacity can’t be quickly scaled up or down. LLMs’ long training times may also limit availability for other projects. And then there’s the convenience factor. “For most companies, racking, stacking, and managing large server farms is too much trouble,” Kardwell said.
In contrast, cloud platforms offer unlimited computing power without requiring months of equipment setup time and capital costs. AI teams can instantly deploy thousands of GPUs or AI-accelerating tensor processing units for a project of practically any size.
“Cloud is instant, up to date, readily available, and you pay for what you use, so it should be the default, said Ed Thompson, co-founder and chief technology officer of cloud data management startup Matillion Ltd. “If you’re working on data that needs to be processed within your environment, or you’re going to be the next GPT, that’s when on-premises comes into play.”
Cloud platforms provide the flexibility to experiment with different model architectures with pricing structures and give organizations the freedom to experiment.
That variability is an essential factor in the equation, said Hailo’s Danon. “Renting in the cloud is more expensive, but only if you continuously use the resource,” he said. “If you only use it for a day once a month, then it makes more sense to stay in the cloud, but if you want responsiveness and uptime, then you will want to own the infrastructure.”
The leading cloud providers also offer advanced services tailored for machine learning workloads. For example, AWS SageMaker accelerates building and training models, while Google Cloud AI Platform enables training on massive datasets.
As models continue to increase rapidly in size, the economies of scale of major cloud platforms will be difficult for on-premises efforts to match. But technological forces can shift the question. New hardware such as Cerebras Systems Inc.’s CS-2 wafer-scale engine could help reduce on-premises costs for training future models. GPU shortages will ease as supply chain issues are resolved and competitors enter the market. “As GPU supply shortages ease, we will see more migration on-prem,” said MinIO’s Periasamy.

Hailo’s Danon: if you want responsiveness and uptime, then you will want to own the infrastructure.”
The model training process is also evolving. RAG training and parameter-efficient fine-tuning are seen as evolutions of traditional model training that produce better quality output with lower overhead. “PEF is emerging to enable organizations to do transfer learning to the larger model and to do fine tuning with less data,” said Gartner’s Chandrasekaran.
“A year ago, if you wanted to change the task, you had to retrain it,” said Brandon Jung, vice president of ecosystem at Tabnine Ltd., which makes an AI assistant for software development. “With the understanding LLMs now carry with them, they don’t need to be retrained for certain tasks.”
That makes deployment options a moving target. Most experts agree that cloud platforms make the most sense during experimentation phases. Once organizations have a better handle on their long-term training needs, local deployment becomes attractive.
One thing nearly everyone can agree on is that most inferencing is likely to be done on local infrastructure for reasons of performance and control. “Once models are trained and deployed at the edge, there will be significantly less data and less inference happening in the cloud,” said Evan Welbourne, head of AI and data at cloud platform provider Samsara Inc.
Ultimately, both models are likely to be widely used. “I’ve already seen big organizations use a combination of on-prem and various API services,” said Dataiku’s Dougherty. “We’re going to see what happened with databases over the last 10 years: There was a push to get everything onto a single platform, which never really worked, so we went toward a data mesh.”
For a technology moving at the speed of AI, the time to resolution should be much shorter.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





