













 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
At the beginning of last year, who knew that generative artificial intelligence and ChatGPT would seize the moment?
A year ago, we forecast that data, analytics and AI providers would finally get around to simplifying and rethinking the modern data stack, a topic that has been near and dear to us for a while. There was also much discussion and angst over data mesh as the answer to data governance in a distributed enterprise. We also forecast the rise of data lakehouses.
So how will all this play out in 2024? It shouldn’t be surprising that we see gen AI playing a major role with databases in the coming year with vector indexing, data discovery, governance and database design. But let’s start by reviewing how gen AI affected our predictions over the past year.
For the record, last year’s predictions are here and here. Turns out, many of them came true.
We saw real progress with simplifying and flattening the modern data stack through extension of cloud data warehousing services to integrate transactions, data transformation pipelines and visualization from the likes of SAP SE, Microsoft Corp., Oracle Corp. and others. And there was significant expansion by Amazon Web Services Inc. of its zero-ETL, or extract/transform/load, capabilities for tying together operational databases with Redshift and OpenSearch, addressing a key weakness in its database portfolio.
And as we expected, reality checks hit the data mesh, as enterprises grappled with the complexities of making federated data governance real. There is a new awareness for treating data as a product, but the definition of data products remains in the eyes of the beholder.
As for data lakehouses, which we termed as “the revenge of the SQL nerds,” Apache Iceberg became the de facto standard open table format bridging the data warehouse and lake together. Even Databricks Inc. opened the door by making Delta tables look like Iceberg.
During the first quarter, there was hardly any mention of gen AI. But strangely, around April 1, the tech world pulled a 180-degree turn, as we noted in our gen AI trip report published back in the summer. Having been unleashed the previous November, OpenAI’s ChatGPT garnered 100 million users in barely a couple months; that’s a lot faster than Facebook, Instagram and what’s left of Twitter (X) ever did.
And suddenly, every data, analytics and AI solutions provider had to have a gen AI story. Vector data support became a checkbox feature with operational databases. English (and increasingly, other popular speaking languages) was fast becoming the world’s most popular application programming interface and software development kit. And there was humongous interest in the potential for gen AI to autogenerate coding, despite intellectual property issues.
Of course, generative transformer models work with more than language. They can also assemble pixels into a picture, spit out boilerplate code for requested functions, piece together musical notes to form songs, and work with molecular structures, geospatial and just about any other forms of data to find probabilistic connections. But most of the attention was on large language models.
In the background, hardware became as cool as Jensen Huang’s trademarked black leather bomber jacket. The Nvidia Corp. CEO became virtually ubiquitous at almost every cloud conference we hit; keynotes were just not complete without Huang making some appearance on stage.
Although everyone wants to be Nvidia’s BFF, the race is on for second sources. Scarcity of graphics processing units has gotten to the point where enterprises can only gain access through long-term, one-to three-year commitments for silicon for just-in-case capacity that is only likely to be about 20% utilized on average. Going meta here, we could see AI enabling an aftermarket of unused GPU cycles emerging for AI jobs.
Here’s the data angle: The success of every AI model – generative or classic machine learning – depends on the relevance, performance and accuracy of the model, and of course the relevance and quality of the data. In the new generative world, “garbage in, garbage out” remains as pertinent as ever.
AI venture funding trends 2012-2020
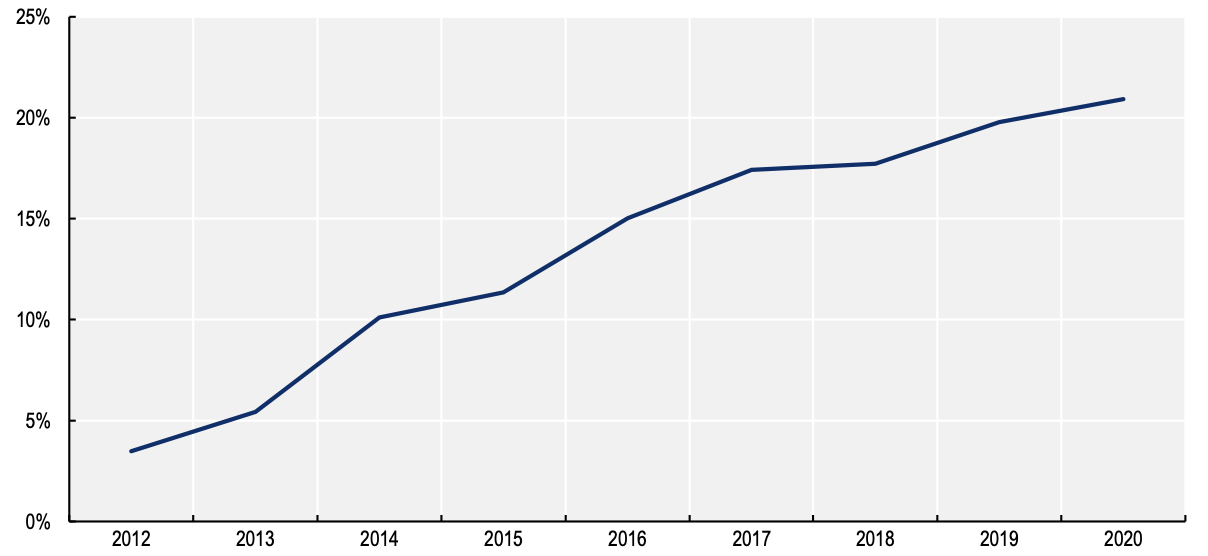
Source: OECD.AI (2021), processed by JSI AI Lab, Slovenia, based on Preqin data of 4/23/2021, www.oecd.ai.
A decade ago, data was the epicenter for venture funding. Glancing at our meeting schedules for the old Strata big data conferences of the 2010s, our agenda was crammed with startups providing lots of ancillary tools and services centered around Hadoop, streaming, catalogs and data wrangling.
Suffice it to say that there was a pretty high mortality rate, which is the Darwinian order of things. Fast-forward to today, and AI has supplanted data as hotspot for venture investment. According to the Organization for Economic Cooperation and Development, over the past decade, AI has been the fastest-growing sector for venture funding during that period, as shown in the chart, which extends only through 2020. A related fun fact from the OECD is that actual AI venture funding grew by 28 times over that period.
Admittedly, the last few years have been more fallow, but if the OECD chart were more current, we’d expect that growth in the percentage of venture deals and the multiples for AI would have continued.
According to PitchBook, the third quarter of 2023 saw overall venture financing dip to its the lowest level since 2017, with early-stage funding moving in unison with a five-year low. But the rich are getting richer, with Open AI as the obvious poster child with Microsoft’s $10 billion backing. And then there’s Anthropic PBC, with roughly $5 billion from AWS and Google LLC behind it, recently scoring another $750 million round, placing its valuation at a rather sublime $15 billion, or 75 times revenue.
The question isn’t whether, but when, there will be a popping of this bubble. With interest rates likely to decline next year, that moment of reckoning won’t likely come immediately. The tech is too new for customers to get disappointed. Yet.
But wait a moment. OpenAI, Anthropic, Cohere Inc. or otherwise, 2024 will likely be marked as the start of a Cambrian explosion of fit-for-purpose, and more compact, foundation models or FMs. We expect we’ll see an upswing of funding in this category to longer-tail firms.
Growth of these fit-for-purpose FMs will be driven by a backlash to the huge expense of running large models such as GPT. When it comes to LLMs, the meek (in the form of smaller language models) will inherit the Earth. With the learning curve, data scientists will grow more prescient at optimizing right-sized training data corpuses for generative models.
And as we noted a few months back, gen AI might be the shiny new thing on the block, but behind the scenes “classical” machine learning models will continue to perform the heavy lift. There will be more of a balance, using the right models for the right parts of the task, when the dust settles.
On the database side, we see a flight to safety. There is scant appetite for new database startups in a landscape that still counts hundreds of engines, but shows the top 10 most popular ones remaining largely stable. The usual suspects from three segments including the relational world (for example, Oracle, SQL Server and various dialects of MySQL and PostgreSQL), nonrelational databases (for example, MongoDB, Elastic, Redis) and the hyperscalers.
We’ll go out on a limb and state that the longer tail has limited prospects for growth. Couchbase Inc. is a good example of a second-tier player that, having recovered from a lost decade, has managed to eke out respectable growth, but it will never reach market share parity with MongoDB, with which it once vied. Beyond this group, we see scant prospects for 2010s-vintage startups such as Cockroach Labs Inc., Yugabyte Inc. or Aerospike Inc. displacing the established order.
So, what should we look for in the 2024 database landscape? A broad hint is that much of it will be about supporting and internally utilizing AI.
Vector indexes won’t be the headline, and neither will gen AI-business intelligence integration. But this is where the most significant database innovation will come in 2024. Database vendors will expand on their generic vector index offerings today with a greater variety of optimized choices, and they will incorporate orchestration that allows gen AI queries to be enriched with tabular, BI-style results.
Back to basics, so what does gen AI have to do with databases? For running routine queries, it’s more efficient to persist the data rather than populate it on-demand. And for generative models, having access to new or more relevant data is key to keeping them current beyond the corpus of data on which the models were trained. That’s where retrieval-augmented generation, or RAG, and vectors come in.
Not surprisingly, the database sector responded last year by adding the ability to store vector embeddings. For existing operational databases, it was pretty much a no-brainer, as vectors comprise just another data type to add to the mix. AWS, DataStax Inc., Microsoft, MongoDB Inc., Snowflake Inc. and various PostgreSQL variants hopped the bandwagon.
We also saw emergence of specialized vector databases, such as from Pinecone Systems Inc. and Zillis Inc. with its Milvus. We expect that the vector database landscape will evolve in the same way as graph: A couple of specialized databases emerge for serving use cases that involve extreme scale and complexity, with most of the action coming from the databases that we already use that are, or are in the process of, adding vector data support as a feature.
With most operational databases adding vector storage, we view indexing as the next frontier, and that’s where much of the differentiation in gen AI support will come. Most databases adding vector storage are starting out with rudimentary indexing that is not optimized for specific service level agreements. That is about to change.
Here’s why: Vector indexes are not created equal. Vector indexes search for “nearest neighbors” that identify similar items (aka “similarity searches”), but there are different ways to optimize similarity searches that will in turn shape the choice of what databases to use based on which types of indexes they support.
Among the variables for vector indexes are recall rates, which measure the proportion of relevant data entities or items that are retrieved for a specific query. Essentially the choice is between low recall rates, which are quick-and-dirty approaches that are more economical to run and provide a general picture, and high-recall indexes that are more comprehensive and exacting with the results they return.
So, a generative application for producing marketing content could probably get by with a low-recall-rate vector index, whereas a compliance-related use case will require more comprehensive, and expensive, high-recall searches. There are other variations in vector indexes as well that are optimized for parameters such as speed (performance) or scale
For instance, Milvus offers nearly a dozen different vector index types optimized for data set size, speed, recall rates, memory footprint and dimensionality (a measure of query complexity), while Oracle offers a choice of an in-memory index for more compact searches and one designed to scale in parallel across multiple partitions.
The flip side of the coin is the ability to mix and match results of vector queries with tabular data. This will literally be the visible side of gen AI database innovation. For instance, a provider of market intelligence to business clients that delivers a natural language alternative to keyword searches, correlating summarized data on customer sentiment from the vector store with heterogeneous data from a document database such as MongoDB.
Here’s another use case: A manufacturer using gen AI to conduct root cause analysis of product quality issues can correlate with tabular data from a relational database tracking warranty and service costs. We expect to see better connective tissue inside database platforms that can orchestrate such compound queries.
Today, data governance and AI governance are separate toolchains, run by different practitioners: database administrators and data stewards at one end, and AI developers and data scientists on the other. The problem is not confined to gen AI, but applies to all types of AI models, and a convergence is long overdue. We expect to start seeing movement in the coming year toward bringing data and AI governance together through tracking and correlating lineage.
It’s a messy challenge. Just take data governance: In most organizations, it is hardly monolithic. Typically, different teams and players take the lead with data quality, security and privacy, compliance and risk management, and overall lifecycle management. And often these efforts will be overlapping, as most organizations have multiple tools such as data catalogs performing the same task.
The disconnect in data governance triggered the discussion over data mesh, which was about reconciling data ownership with responsibility for data products over their full lifecycle. That dominated the data discussion back in 2022.
Meanwhile, AI governance has emerged in spurts as adoption of machine learning spread from isolated proof of concepts toward becoming routinely embedded in predictive and prescriptive analytics. It typically focused on tracking model lineage, auditing, risk management, compliance and, in some cases, explainability. Gen AI has compounded the challenge, requiring more attention to citation of data sources while introducing new issues such as detecting (and enabling deletion) of toxic or libelous language; hallucinations (of course); and copyright and IP issues, to name a few examples.
The challenge, of course, is that with AI, models and data are intertwined. The performance, safety and compliance of a model is directly linked to both the training and production data sets that are used for generating answers. That is why, when detecting model bias, the problem could just as easily lie with the data or with logic or algorithm, or some combination of both.
For instance, it’s well-documented that the reliability of facial recognition systems gets easily skewed by over- or under-sampling of different races and nationalities. The same goes with analyzing demand for products or social services when different census tracts or demographic cohorts are sampled at different rates.
Then there is the question of drift; data and models can drift independently or interdependently. Data sources may change, and the trends in what the data is revealing may also require the model in turn to adapt its algorithms. You don’t want to be solving yesterday’s problem with today’s data or vice-versa.
In the coming year, we expect AI governance tools to start paying attention to data lineage. It is the logical point where the audit trails can begin, assessing which version of which model was trained on what version of what data, and who are the responsible parties that own and vouch for those changes.
From there, more sophiscated capabilities could later emerge, tracking and correlating data quality, accuracy, compliance and so on. With many machine learning models executing in-database, we see huge opportunity for data catalogs to incorporate model assets, and from there to become the point where governance is applied.
We viewed with interest that IBM closed the acquisition of Manta Software Inc. for data lineage around the same time that it took the wraps off watsonx.governance for AI governance. Although IBM’s timing was coincidental, we hope that it will eventually take advantage of this serendipitous opportunity.
It’s hardly surprising that the most popular use cases for gen AI have been around natural or conversational language interfaces for tasks ranging from query to coding. We expect that data discovery and governance will be a major target for gen AI augmentation in the coming year.
Let’s start with natural language or conversational query. A few good early examples include ThoughtSpot Sage, Databricks LakehouseIQ and Amazon Q in QuickSight that pick up where keyword-oriented predecessors such as Tableau Ask Data left off. We expect the Tableaus and Qliks of the world to respond in 2024.
We also expect that natural language will come to a variety of functions around the blocking and tackling involved with the data lifecycle, from cataloging data to discovering, managing, governing and securing it. Atlan, a data catalog provider focusing on DataOps provides glimpses of what we expect to see more of this year. Atlan starts with a common natural language search function that is quite similar to the natural language query capabilities that a growing array of BI tools are offering.
But it ventures further by adapting the autodiscovery of database metadata (for example, the table and columns names, schema specifications and lineage of the data asset) to generate documentation in plain English. As a mirror image to natural language SQL code generation, Atlan can translate existing SQL transformations into plain-language descriptions.
This is just the tip of the iceberg. A logical extension to these auto-documentation capabilities would extract data from business glossaries and correlate them with table metadata, or vice-versa. The automatic summarization capabilities of gen AI could be pointed at written policies, rules and incidents to document compliance with risk management guardrails. The reading of table metadata and SQL transformations could enrich or generate reference data that reconciles data between databases and applications, and identifying gaps or omissions. These are just a few of the possibilities that we expect will emerge this year.
Following in the footsteps of automatic code generation or guidance, gen AI could also help database designers streamline development and deployment of databases. Of course, this will continue to require humans in the loop – we shouldn’t let a smart bot loose on designing a database without intervention. But the ability for language models to scan, summarize and highlight a corpus of data could make it a major productivity tool in database development.
Admittedly, AI is already being used in many aspects of database operation, from query optimization to index creation, autotuning, provisioning, patching and so on, with Oracle Autonomous Database being the poster child for complete self-driving automation. Although there are areas of operation where machine learning is already being used to optimize or provide suggestions that could be supplemented by gen AI, we believe that the biggest bang for the buck will be with aspects of the database dealing with the content of the data, and that’s where we expect the next wave of gen AI innovation will happen in 2024. As noted, we have already seen glimpses with natural language query and SQL code generation.
In the near term, we expect to see gen AI database innovation to focus on structuring the data. Taking advantage of the same types of capabilities that transformer models use for summarizing and extracting the highlights of documents, we could see this being applied to scanning requirements documentation for applications for data modeling through outputting E-R diagrams, schema generation, and synthetic data generation based on the characteristics of real data. And taking advantage of code generation capabilities and the ability to detect implicit data structure, we could see gen AI being applied to create data transformation pipelines.
Longer-term, we could see generative AI coming in to supplement the tasks where machine learning is already being applied, such as with index creation, error and outlier detection, and performance tuning. But we don’t view these functions as being first priority for database providers in 2024, as the benefits there will be incremental, not transformational. As with any shiny new thing, let’s not get carried away.
Tony Baer is principal at dbInsight LLC, which provides an independent view on the database and analytics technology ecosystem. Baer is an industry expert in extending data management practices, governance and advanced analytics to address the desire of enterprises to generate meaningful value from data-driven transformation. He wrote this article for SiliconANGLE.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





{kind=link}