









 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Input from theCUBE and data practitioner communities suggests that acceleration in compute performance and the sophistication of the modern data stack is outpacing the needs of many traditional analytic workloads.
Most analytics workloads today are performed on small data sets and generally can run on a single node, somewhat neutralizing the value of distributed, highly scalable data platforms. As such, we believe today’s modern stack, or MDS, which started out serving dashboards, must evolve into an intelligent application platform that harmonizes complex data estates and supports a multi-agent application system. Data platforms are sticky, but we believe market forces are conspiring to create tension on existing business models.
In this Breaking Analysis, we welcome Fivetran Inc. Chief Executive George Fraser. Fivetran is a foundational software company that has a front-row seat and exceptional visibility on data flows, size of data, sources of data, how data is being used and how it’s changing. In this episode, we test the thesis that much of the analytics work being done on data platforms risks being commoditized by good enough, cost effective tooling, which is forcing today’s MDS leaders to evolve.
Many folks in our audience are familiar with the epic series of lectures by Clay Christensen at Oxford University where he so brilliantly described his theory of disruptive innovation in compellingly simple terms.
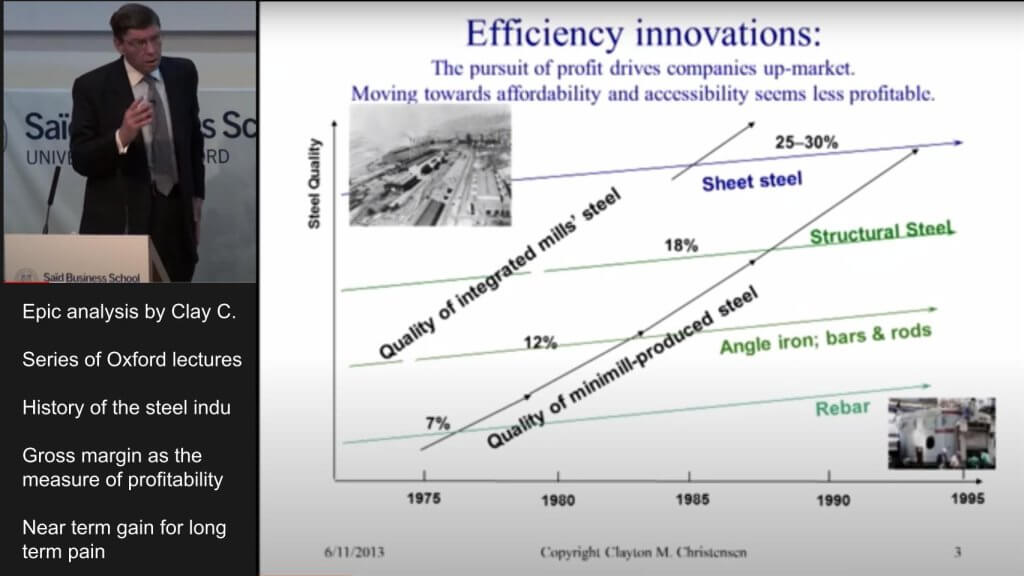
For those not familiar with the lectures, here’s the TL;DR:
Christensen explained his model in the context of the steel industry, where historically, most steel was made by integrated steel mills that cost $10 billion to build at the time. But these things called mini-mills emerged that melted scrap metal in electric furnaces and could build steel for 20% less than the integrated mills.
Mini-mills became viable in late 1960s. Because the quality of steel made from scrap was uniformly bad, mini-mills went after the rebar market and the integrated mills said, “Let the mini-mills have the crummy 7% GM business,” as shown in the diagram above. By getting out of the rebar market, the integrated steel companies’ margins improved, lulling them into a sense of calm.
But when the last of the integrated mills exited the rebar market in the late ’70s, prices tanked, commoditizing rebar. So the mini-mills moved upmarket where there was a price umbrella. The same thing happened with angle iron steel and then structural steel and it kept going until the integrated steel model collapsed and all but one manufacturer went bankrupt.
As Christiansen points, out this happened in autos with Toyota and many other industries. We’ve certainly seen it in computer systems and we think a similar dynamic could take place in the software industry generally and specifically the data platform stack — with some definite differences.
Below we show a chart to represent the data equivalent of the steel industry in Christensen’s example.
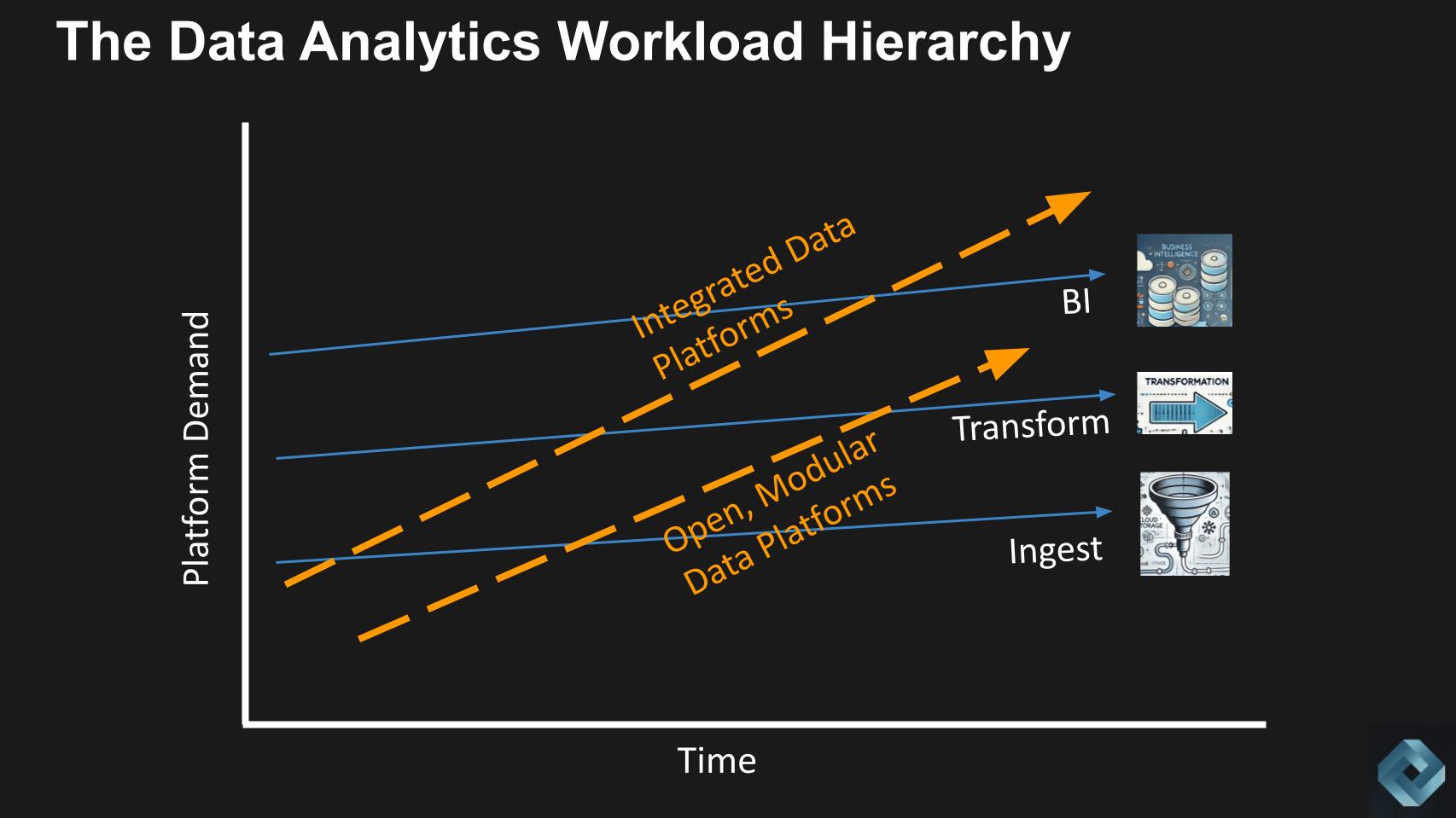
Ingest, transform and business intelligence are rebar, angle iron and structural steel, respectively. To be clear, we’re talking about the demands on the data platform in this analogy. The connectors that extract data from the application are sophisticated, but the demand it places on the system to land the data is minimal relative to the increasing scale and sophistication of today’s data platforms.
In other words, for most workloads, the sophistication in terms of distributed scale out management capabilities is outstripping what’s needed for most workloads. And the modern data platform, in order to justify the investments in their sophistication, must move up the stack to new workloads.
Note: Where the analogy breaks with the steel industry is the integrated steel mills hit the ceiling of the stack – there was nowhere for them to go and they failed as a result. Firms such as Snowflake Inc. and Databricks Inc. have total available market expansion opportunities that we’ll discuss in detail.
With that as background we bring George Fraser into the conversation. Fivetran is one of the iconic companies that defined the modern data stack. Snowflake, Fivetran, dbt Labs Inc. and Looker were considered the four horsemen of the original MDS.
This slide below from Enterprise Technology Research will give you a sense of how prominent a position Fivetran has in the market.
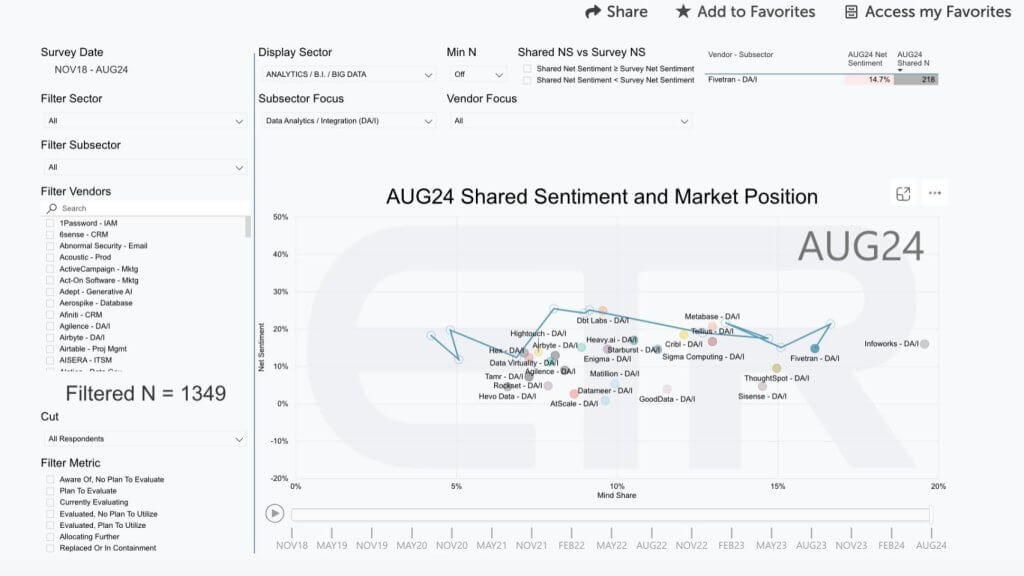
The data is from the August survey of 1,349 information technology decision makers and shows emerging companies (privately held firms) in the data/analytics/integration sector within the ETR data set. Net Sentiment is shown on the vertical axis, which is a measure of intent to engage and the horizontal axis is Mind Share. You can see the dramatic moves that Fivetran has made since 2020 shown by that squiggly blue line.
Q1. George Fraser, is today’s modern data stack out over its skis with respect to the sophistication and scale of the platform relative to the vast majority of workload requirements running out there?
I think it’s a really interesting moment. The data platforms are stronger than they’ve ever been, but I think there’s a question of whether we’re, after a long period — really, 10 years of bundling — about to see a moment of a bundling again.
There’s an interesting fact that hangs over the entire world of data platforms, which is that most datasets are much smaller than people realize. We see this at FiveTran, where we’re putting data into data platforms. What we find is that many of these so-called “huge datasets” often come from inefficient data pipelines, doing things like storing another copy of every record every night when the data pipeline runs.
If you have an efficient data pipeline, the data sizes aren’t that large. You also see that a lot of workloads running on these data platforms are processing many small queries rather than one big query. Right now, we’re seeing the emergence of data lakes, which are the fastest-growing destination for FiveTran — specifically Iceberg and Delta data lakes.
One of the interesting implications of data lakes, while they’re typically thought of as a place to store huge datasets, they also have other characteristics. For instance, with a data lake, you can bring multiple different compute entities to the same data, opening up the possibility of using specialized compute engines that are more optimized for the actual data sizes most people work with on a day-to-day basis.
There’s a lot more I could say about this, but I’ll pause here for now. It’s a fascinating moment, and I think there’s a mismatch between how these systems get talked about and how they’re actually used in practice.
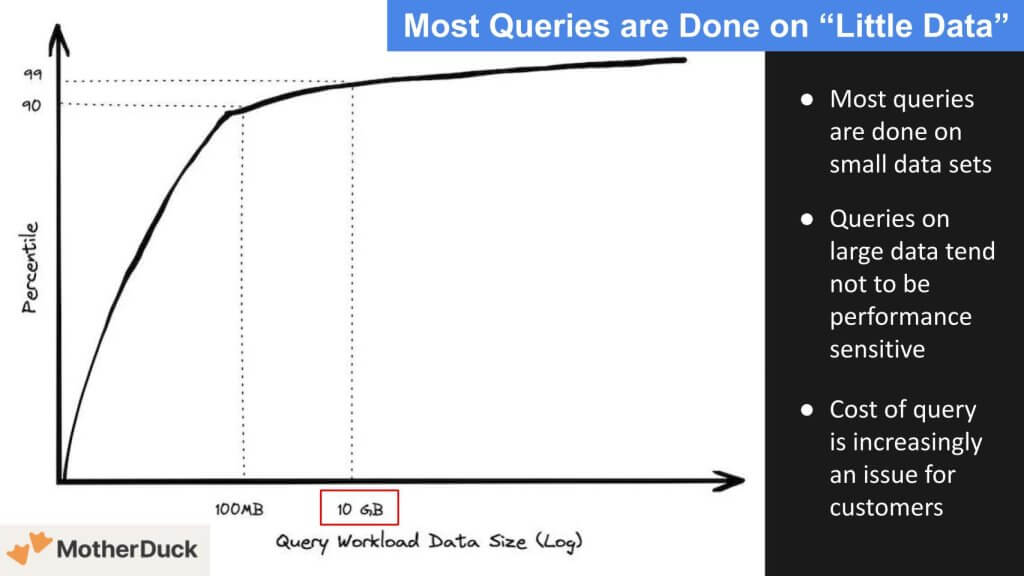
Let’s double-click on that notion of data sizes. The slide below shows that only 10% of the queries are more than 100 megabytes, and only an additional 9% go up to 10 gigabytes. So 99% of the queries are less than 10GB. This is largely because most queries are done on data that is fresh. That’s where the value lies. The data below comes from the blog MotherDuck and specifically, Jordan Tigani’s “Big Data is Dead” post. Tigani was head of product for BigQuery at Google and is CEO of MotherDuck. The data is only a couple years old but we believe it reflects today’s market.
Question 2. George Fraser, are we correct that Jordan’s data reflects today’s reality?
[Where’s all the big data? Listen to Fraser’s response]
Jordan has spoken a lot about this, and I’ve talked to him about it as well. I’ve also recently been looking at Snowflake.
A few years ago, Redshift actually published a representative sample of real-world queries that run, showing what real-world query workloads look like. The data is a bit older — Snowflake’s goes back to around 2017, and Redshift’s is a little more recent. While you can’t see the exact queries, you can view summary statistics, including metrics like how much data they scanned.
What I found when looking at this data was astonishing. The median query — this was true for both Snowflake and Redshift — scanned just 64 megabytes of data. That’s remarkable! Your iPhone could theoretically handle that query.
Now, of course, you can’t run full workloads on your iPhone, but the point is that it’s not the size of the data that’s the challenge; it’s the sheer volume of queries. This aligns with what we’ve seen with our customers at Fivetran. It opens up the possibility for a different architecture in the future.
Imagine a system with a data lake and diverse compute engines talking to it.
Many of these compute engines might be single-node because most workloads don’t need a massively parallel processing (MPP) system. And one of the cool things about data lakes is that multiple systems can collaborate over the same datasets. For those rare, extreme workloads that require massive resources to run, you can still have an MPP system participate in the same database as other, more optimized query engines — or even DataFrame libraries — that handle the smaller queries, which actually make up the bulk of the work people do.
Let’s continue exploring the current market dynamic with some additional data from MotherDuck.
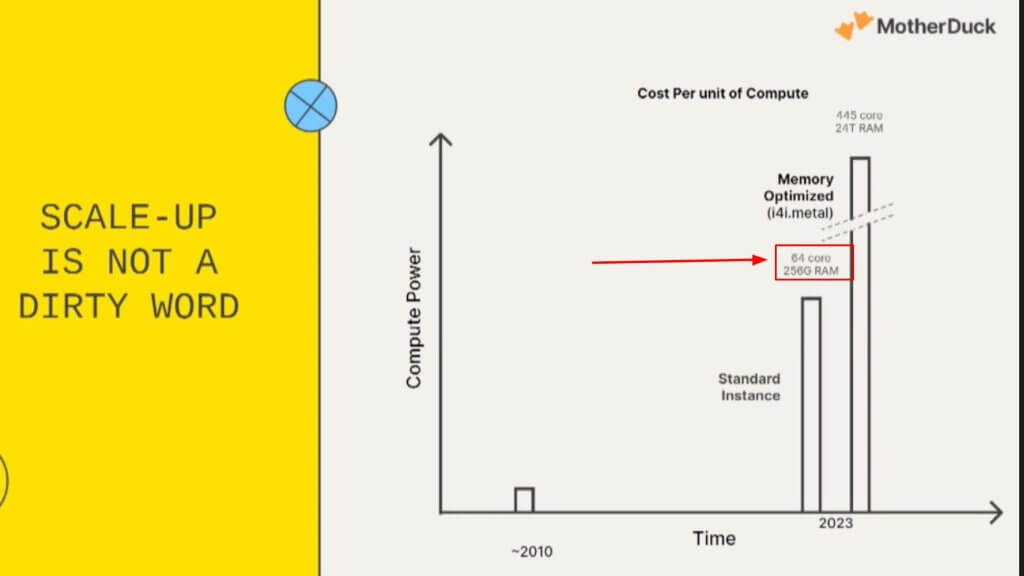
The graphic above shows the standard instance of AWS EC2 has 256 gigs of RAM, so you can put the entire dataset in memory, meaning you only need a single node for the vast majority of queries and workloads. Now to be clear, you’re not necessarily doing all these queries in memory, but the point is you don’t need a distributed multinode cluster to do a query for most situations today.
Q3. George Fraser, you’ve analyzed recent data from Snowflake and Redshift about workload sizing. What does your experience tell you about where the costs are incurred and the scope of queries, especially now that customers have a choice of compute/execution engines?
[Watch Fraser discuss his research on ingest as a portion of the overall workload]
I started looking at this data because I wanted to better understand what ingest costs are as a percentage of people’s total costs.
We’ve seen examples where, for individual customers, just getting the data into the platform — ingestion — was around 20% of the total workload. This is consistent across a broader population, which surprised me. I would’ve thought it would be much smaller. However, ingest actually accounts for a large portion of what people do on these platforms.
What does this all mean?
It’s hard to say for sure what the future holds, but there’s an interesting tension embedded in these observations. I believe we’ll see more diversity in compute engines going forward. The major platforms we use today aren’t going anywhere, but as open formats become more popular, parts of workloads will start to peel off and use more specialized compute engines for particular tasks.
For example, if you sign up for the Fivetran data lake offering today, we ingest the data into the data lake using a service we built, which is powered under the hood by DuckDB. This is a great example of a purpose-built engine designed to do one thing more efficiently. It participates in a data lake, which is then shared with platforms like Databricks, Snowflake or whatever else the user needs to do with it.
Coming back to the idea that “good enough” tooling has the potential to, like the steel industry, commoditize the data stack.
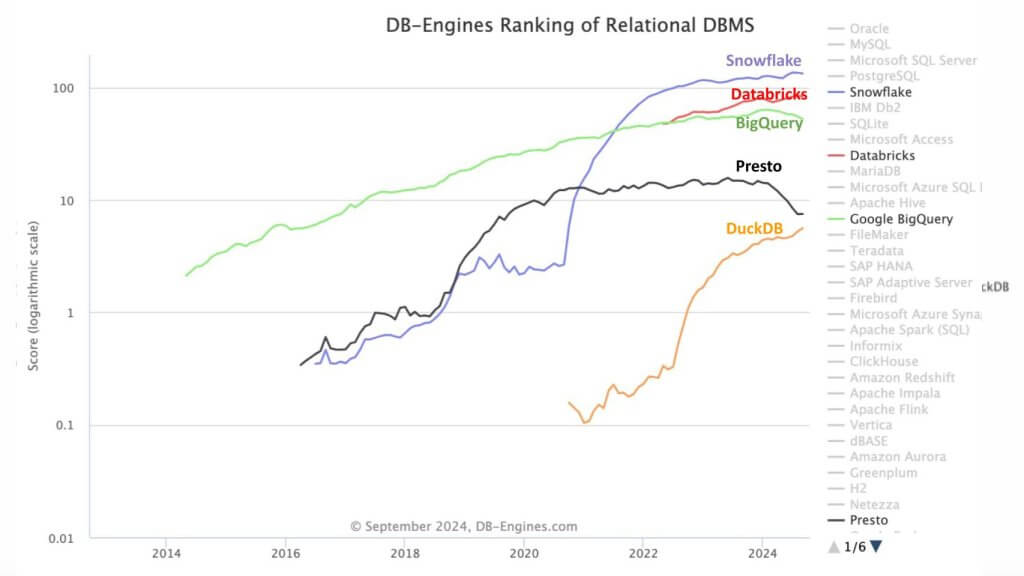
This is very recent data from DB-Engines. They are the go to site for database engine popularity. What this graphic shows is the increasing popularity score of DuckDB relative to other data platforms. DuckDB has improved by almost two orders of magnitude since 2020. The point is DuckDB is open-source and single-node, and in our steel analogy is the mini-mill, whereas Snowflake, Databricks and BigQuery are the integrated steel mills.
Q4. George Fraser, what are you seeing? Is there a looming shift in adoption of open-source analytic databases and do you see it as potentially eating into the popularity of integrated data platforms?
[Watch and listen to Fraser’s comments that the demand for data platforms is virtually infinite]
The thing about data workloads is that the demand is infinite. The dynamics of our industry are always less competitive than people think. If you find a way to do things more efficiently, customers will simply ask more questions of the data.
For example, Snowflake was very much a drop-in replacement for the previous generation of data warehouses. It was better in every way and worse in none for a certain category of things enterprises already had. It was also 10 times more cost-efficient in terms of running workloads. What we saw was that people replaced their legacy data warehouses with Snowflake, but their budgets didn’t decrease — they just did more with their data.
So, to answer your question briefly: Maybe. But keep in mind that in the world of data management, as we find more efficient ways to do things, people just do more.
I would also add that it’s not just about database engines. It’s also about things like DataFrame execution engines. For instance, there’s a lot of talk about PolarDB, a very fast single-node data frame execution engine. There are many players in this ecosystem, and as data formats become more open, there’s much more opportunity for customers to find the right match.
Q5. George Fraser, you have insight into how today’s integrated vendors can improve in terms of speed and simplicity. Like Snowflake now with its declarative data pipelines, with the incremental update, the low-latency ingest and processing, and how it can directly feed a dashboard. Specifically bringing that end-to- end simplicity to move the bar up in terms of doing things that the component parts or single node is not capable enough to do. In other words, can today’s MDS players move the goalpost, in a way the integrated steel mills could not?
[Listen and watch Fraser’s claim that an integrated approach wins the day]
I think for a lot of customers, the simplicity of an integrated system will win the day. You have to remember that the most expensive thing in the world is headcounts. You can say that I can put together DuckDB and this and that and the other thing and build a system that’s more efficient mathematically. And you’re right. But for any particular company, it doesn’t take [very much] work from an engineering team before you’ve undone all of the gains that you have.
So there are a lot of customers just opening the box and thinking what comes in the box is still going to be the right answer simply because it’s efficient from a people perspective. Even if maybe there is out there a configuration that more efficient from price perspective.
In order to justify the sophistication of today’s integrated data platforms, we believe they must add new functionality. We’re showing below three new elements that MDS players could pursue, including: 1) The addition of retrieval-augmented generation; 2) A harmonization layer; and 3) Multi-agent systems. These are capabilities that firms like Snowflake and Databricks are working on or have an opportunity through partnerships, to absorb the integrated simplicity that we believe is overshooting many of the traditional workloads at the bottom layers.
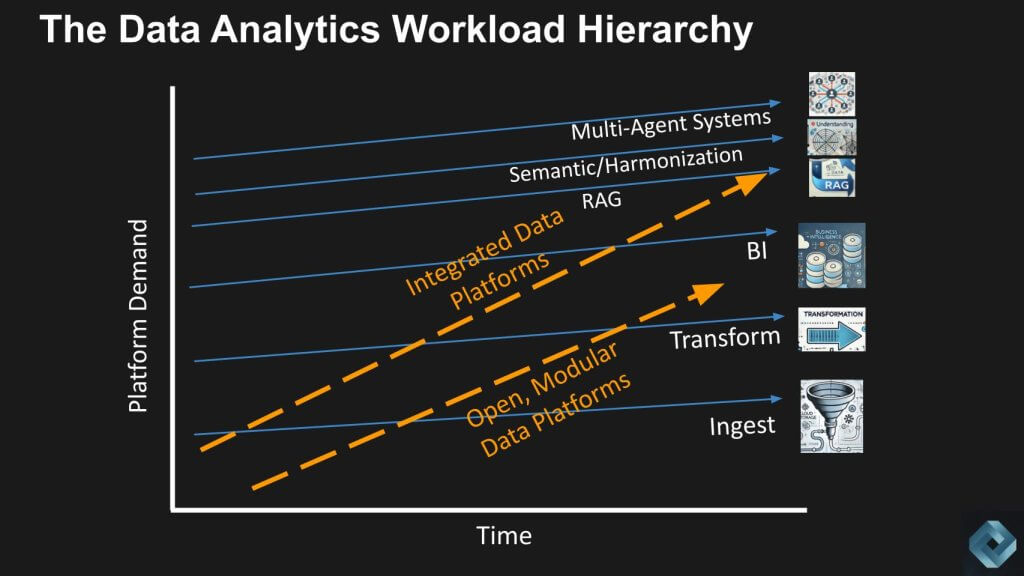
Importantly, in comparison to the steel industry analogy, integrated steel mills couldn’t move up the stack.
However, in the data platform world, if you want all the data to speak the same language — for instance, in the BI world, that would be metrics and dimensions — it becomes much more complex when you want to do this across your entire application estate. The goal is to ensure the data has the same meaning no matter what analytics or applications are interacting with it. That’s a complicated challenge to solve and a real opportunity to bring new value.
We’ve discussed this on our shows with Benoit Dageville at Snowflake. We’ve also had conversations with Molham Aref from Relational AI and Dave Duggal from EnterpriseWeb. It’s almost like we’re moving toward a new kind of database that functions as an abstraction layer. As data platforms move up this layer, they provide integrated simplicity for application developers, enabling them to work more efficiently.
Right now, retrieval-augmented generation is using a large language model to make sense of different chunks of data, but it also needs a semantic layer to be truly effective. Without diving into the technical details, this is what’s called GraphRAG. The next layer above this on the chart is when LLMs can actually take action and invoke tools without being preprogrammed for every step. This is where agents come into play, and you need a multi-agent framework to organize what is essentially an org chart of an army of agents.
These are all layers that today’s application platforms can evolve into, unlike the steel mills in our analogy. This is what we’ll continue to explore in the coming months and years as we track how the application platform evolves.
Let’s now revisit how we envision the modern data and application stack evolving to support intelligent data apps.
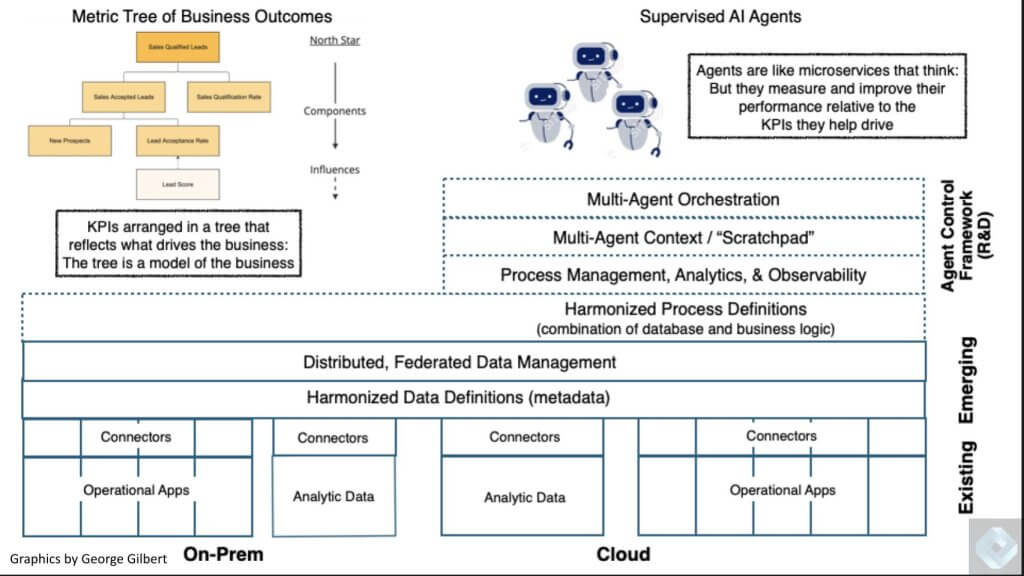
You may remember last week and a few episodes back on Breaking Analysis, we laid out a vision of the evolving intelligent data applications stack. A key point here is a missing link is the harmonization layer, sometimes referred to as the semantic layer.
And in the upper right is a new, yet to be created piece of real estate that represents a multi-agent platform. We’ve reported that firms such as Salesforce Inc., Microsoft Corp. and Palantir Technologies Inc. are working on or evolving to incorporate some of this new functionality.
But they are confined to their respective application domains — whereas firms such as UiPath Inc., Celonis Inc. and other emerging players we’ll talk about have an opportunity to transcend single application domains and build horizontal, multi-agent platforms that span application portfolios and unlock trapped value.
So it’s not only a matter of Snowflake and Databricks going at it. There are others now in the mix as these firms aspire to be platforms for building intelligent data apps.
Below we have an eye chart from Insight Capital that shows some of these emerging players within the agentic space. We don’t expect you to read this, but the point is there are many potential players here that can add value as partners, M&A targets or competitors. There are armies for existing and new firms springing up to compete for this important layer.
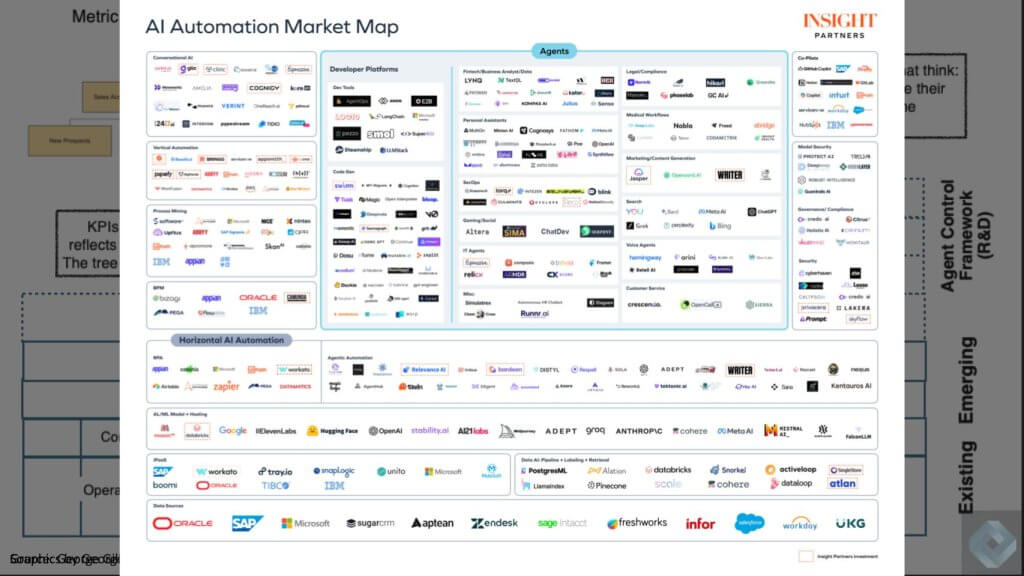
The definition of an application for decades was the database and the data model. The processes, the workflow, that was the application logic, and then the presentation logic. And that formed all these islands of automation. The idea of redefining this complicated field with a harmonization layer is that you abstract all those islands and then you can put an agent framework around it, That agent framework will allow all these personas or functionally specific or specialized agents to collaborate in a larger enterprise wide context, mapping to top down goals and executing in a bottom up fashion.
We see this as the big challenge and opportunity for artificial intelligence return on investment over the next five to 10 years.
Q6. George Fraser, perhaps you can comment on how the discussion today feeds into the idea that, while these modern data platforms are sticky, there’s some tension that we’ve highlighted here which suggests that data lakes might be transformed in a way that many people are not talking about.
I think one of the non-obvious implications of the emergence of data lakes is that there will be more diversity of execution engines. We may see some workloads get pulled away from the integrated data platform, but at the same time, there’s always new things to do, like many of the things that you just mentioned.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





