AI
AI
AI
AI
AI
Snowflake Inc. today said it’s integrating technology into some of its hosted large language models that it says can significantly reduce the cost and time required for artificial intelligence inferencing, the use of trained models to make predictions or generate outputs based on new input data.
The technique, called SwiftKV, is an optimization technique for large language models developed by Snowflake AI Research and released to open source that improves the efficiency of the inference process by essentially recycling information called hidden states from earlier layers of an LLM to avoid repeating calculations of key-value caches for later layers.
Key-value caches are like memory shortcuts for a language model. They store important information about input text so the model doesn’t have to recalculate it every time it generates or processes more text. That makes the model faster and more efficient.
Snowflake said the technique can improve LLM inference throughput by 50% and has reduced inferencing costs for the open-source Llama 3.3 70B and Llama 3.1 405B models by up to 75% compared with running without SwiftKV.
The company is initially integrating the technique with the Virtual Large Language Model — a separate but similar technique encompassing end-to-end inferencing – and making it available in those two Llama models. The same optimizations will be added to other model families available within Snowflake Cortex AI, a feature in Snowflake’s Data Cloud platform that enables businesses to build, deploy and scale AI and machine learning models directly within Snowflake. However, Snowflake didn’t specify a timeframe for supporting other models.
By avoiding redundant computations, SwiftKV reduces memory usage and computational overhead, enabling faster and more efficient decoding, particularly for autoregressive tasks in real-time AI applications. Those tasks involve generating one token — a word or part of a word — at a time, where each word is predicted based on the previously generated ones. The process is commonly used in applications such as chatbots, real-time translation and text generation, where speed is critical.
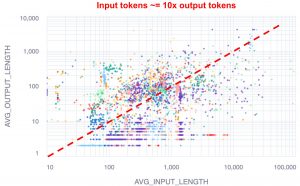 The company said SwiftKV’s performance gains are predicated on the assumption that most computational resources are consumed during the input or prompt stage. Many business tasks use long questions and generate short answers, which means most of the computing power goes into interpreting the prompt. Snowflake posted a distribution chart on its engineering blog (right) that shows that the typical Snowflake customer workload contains 10 times as many input as output tokens.
The company said SwiftKV’s performance gains are predicated on the assumption that most computational resources are consumed during the input or prompt stage. Many business tasks use long questions and generate short answers, which means most of the computing power goes into interpreting the prompt. Snowflake posted a distribution chart on its engineering blog (right) that shows that the typical Snowflake customer workload contains 10 times as many input as output tokens.
“SwiftKV does not distinguish between inputs and outputs,” said Yuxiong He, AI research team lead and distinguished software engineer at Snowflake. “When we enable SwiftKV, the model rewiring happens for both input processing as well as output generation. We achieve computation reduction on input processing only, otherwise known as prefilling computation.”
SwiftKV saves time by reusing completed work instead of repeating the same calculations, reducing extra steps by half with minimal loss of accuracy. It also uses a trick called “self-distillation” to ensure it remembers everything it needs, so answer quality doesn’t change. In benchmarks, Snowflake said it saw accuracy decline by less than one percentage point.
“There is a very small quality gap between the two,” He said, “but if a customer is particularly concerned with this area, they can opt to use the base Llama models in Cortex AI instead.”
The technique enables performance optimizations on a range of use cases, Snowflake said. It improves throughput on unstructured text processing tasks such as summarization, translation and sentiment analysis. In latency-sensitive scenarios, such as chatbots or AI copilots, SwiftKV reduces the time-to-first token — or the amount of time it takes for a model to generate and return the first piece of output — by up to 50%.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.