







 AI
AI
AI
AI
AI
Meta Platforms Inc. today is expanding its suite of open-source Segment Anything computer vision models with the release of SAM 3 and SAM 3D, introducing enhanced object recognition and three-dimensional reconstruction capabilities.
Meta says the Segment Anything 3 model, to give it its full name, enables the detection and tracking of objects in images and videos via text prompts, while SAM 3D can generate extremely realistic 3D versions of any object or person in an image fed into it.
SAM 3 and SAM 3D are what’s known as “image segmentation” models. Segmentation is a subset of computer vision that teaches algorithms to recognize specific objects within an image or video. It’s used in a wide range of applications, such as analyzing satellite imagery and editing photos.
Meta is widely viewed as a leader in image segmentation, having debuted its original Segment Anything Model more than two years ago, in April 2023, alongside a massive dataset containing millions of images of objects to support the open-source artificial intelligence research community.
SAM 3 builds on the original SAM model. Meta claims much greater accuracy in terms of its ability to detect, segment and track individual objects within images and videos. The model also supports the transformation of these objects via detailed text-based prompts, so users can describe the specific object in an image they want to segment, and how they would like to edit it. As an example, people might upload a photo of themselves wearing a blue shirt, and ask the model to change it into a red shirt.
This is a big step forward, Meta claims. It says AI models have long struggled to link natural language inputs to specific visual elements in images and videos. Though most models can segment simple concepts such as a “bus” or a “car,” they generally only support a limited set of text labels, which means they don’t always understand more complex descriptions such as “yellow school bus.”
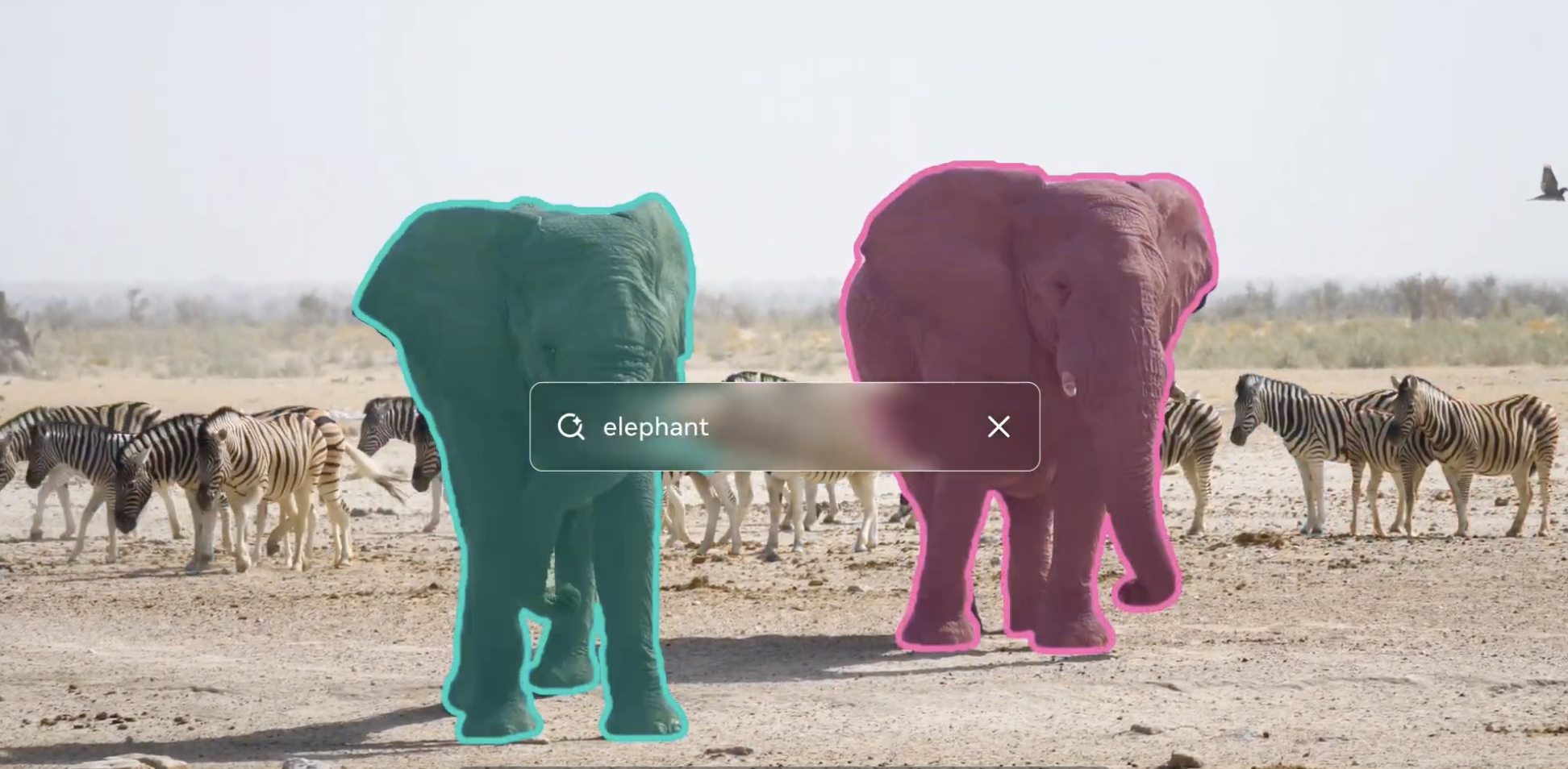
Meta said SAM 3 overcomes these limitations and can support a much broader range of descriptions. If someone types in “red baseball cap,” the model will segment all of the matching objects it finds in the image or video. In addition, it can be used in combination with multimodal large language models to comprehend even longer prompts, such as “people sitting down, but not wearing a red baseball cap.”
According to Meta, SAM 3 can enable numerous possibilities for photo and video editing applications and creative media. It’s experimenting with the model itself in Edits, its new AI video creation app, and plans to introduce new special effects that users will be able to apply to specific objects and people within their videos. In addition, it will bring SAM 3 to Vibes, a TikTok-like platform for creating short-form, AI-generated videos.
As for SAM 3D, it takes SAM 3’s image segmentation capabilities much further by not only recognizing but also rebuilding the objects, people and animals it recognizes in three dimensions. If, for example, someone has a photo of their late grandfather, they’ll be able to use SAM 3D to reconstruct his likeness in 3D, and then import it into videos or virtual reality worlds, the company said.
SAM 3D is powered by two different models, including SAM 3D Objects, which supports object and scene reconstruction, and SAM 3D Body, which is trained to reconstruct humans by carefully estimating their body shape and physique based on the 2D image it can see.
Meta believes SAM 3D has major implications for areas such as robotics, science and sports medicine, as well as creative use cases. For instance, it can support the creation of 3D virtual worlds and augmented reality experiences or maybe new assets for video games based on real-world objects and people. It also has uses in AI-enabled 3D modeling, the company said.
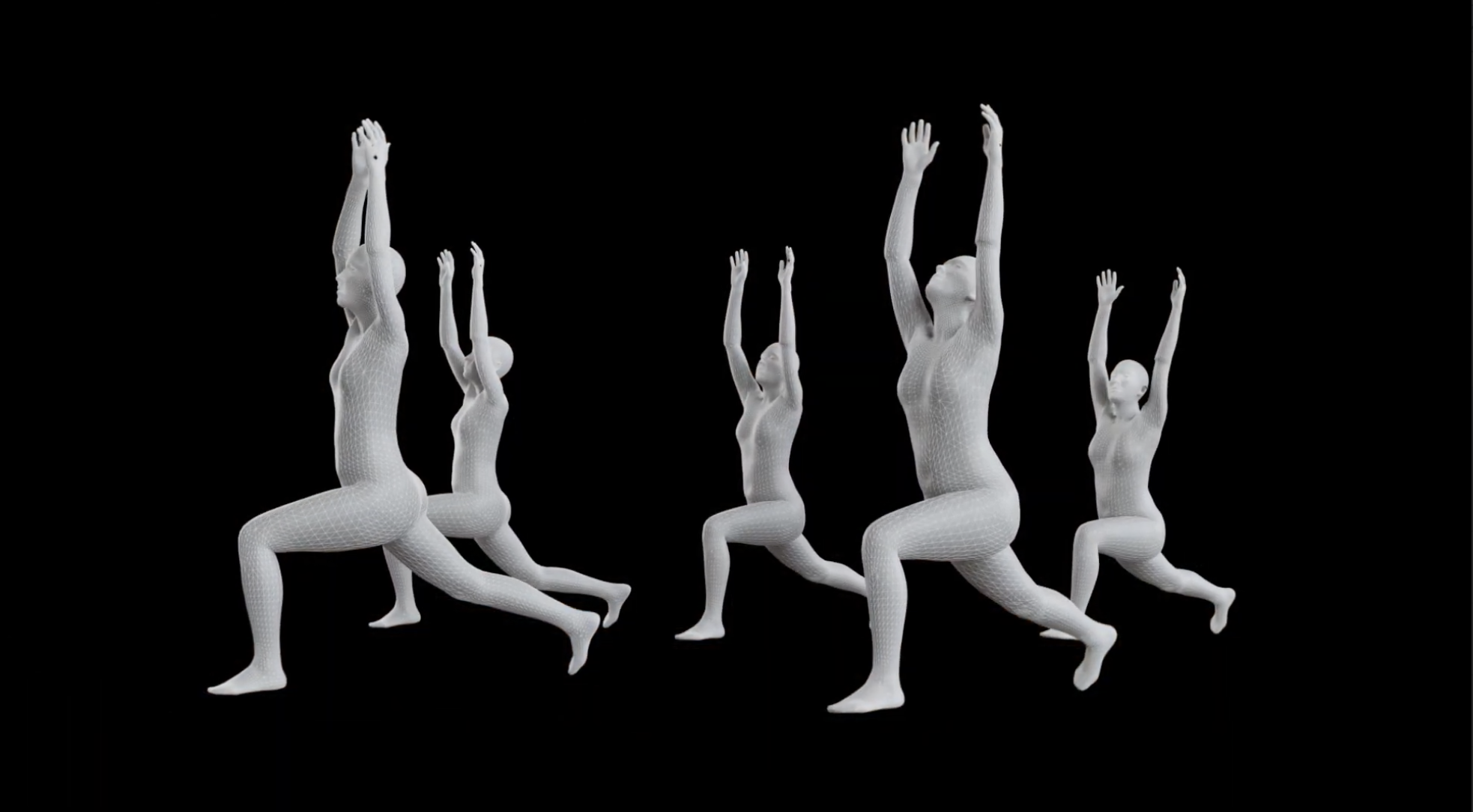
As usual, Meta is using SAM 3D itself to enable the new “View in Room” feature on the Facebook Marketplace. When someone is browsing through home decor items such as a lamp, table or chair, they’ll be able to model how it looks in their own living room before they buy it.
Both of the models are available to access in Meta’s new Segment Anything Playground, and the company said no expertise is needed to start playing around with them. Users can upload an image or a video and then enter a prompt to cut out different objects, for example. Alternatively, they can use SAM 3D to view the scene from a different perspective and virtually rearrange it or add special effects such as motion trails.
Meta is sharing SAM 3 with the rest of the research community, making the model weights available alongside its code. It’s also releasing a new evaluation benchmark and dataset for open vocabulary segmentation, plus a research paper that describes how it built the new model.
SAM 3D isn’t being fully open-sourced yet, but Meta said it will share the model checkpoints and inference code, which are being released together with a new benchmark for 3D reconstruction. There’s also an extensive dataset that features a wide range of different images and objects, for training purposes.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





