















 CLOUD
CLOUD
CLOUD
CLOUD
CLOUD
Google LLC is beefing up its cloud data storage capabilities with new features and products aimed at making it easier for companies to protect their most critical information across a wide range of applications and use cases.
In an interview with SiliconANGLE, Google Cloud General Manager of Storage Guru Pangal and Director of Product Management Brian Schwarz talked about the importance of dual-region and multiregion buckets in Google Cloud Storage. These features, unique to Google, rely on technologies such as Colossus and Spanner and enable what a “continent-sized storage system” that spans different geographic regions, they said.
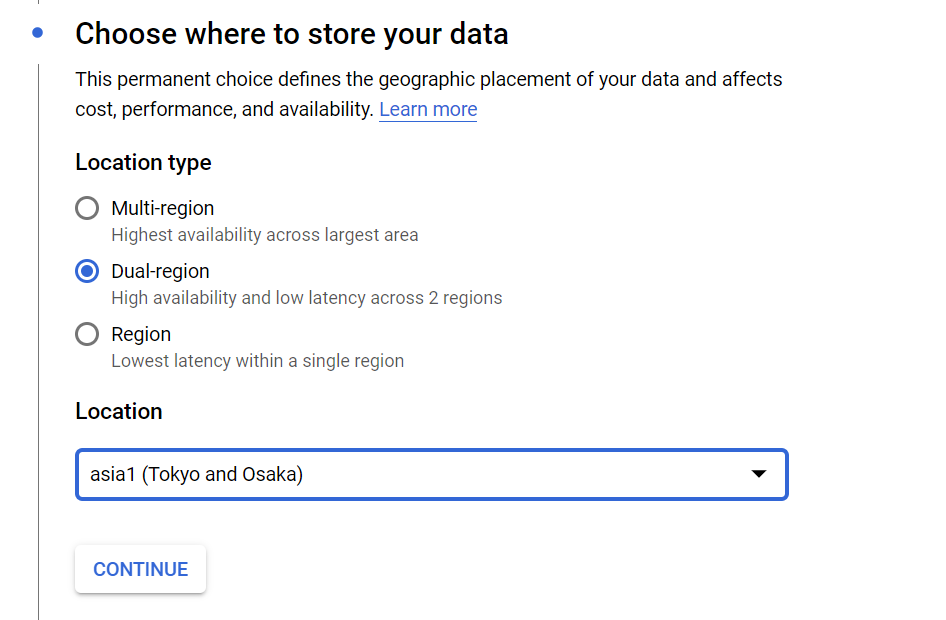
Dual-region buckets are one global namespace that create a single bucket spanning two regions. In other words, while it looks like everything is kept in one place, the underlying storage is in two different locations.
As useful as this feature is, it has been limited because Google previously always assigned two region pairs for customers to choose from. So, for example, if they selected the asia1 region, it would automatically assign the Tokyo and Osaka regions.
That’s changing, Pangal and Schwarz said, and starting today customers will be able to choose their own regions based on the requirements of their applications or workloads, or perhaps their regulatory and compliance needs. So, a financial firm with offices in Frankfurt and Los Angeles will now be able to select a pair of regions close to its bases.
In a second update to Cloud Storage, Google is adding a new Turbo Replication capability to dual-region buckets that it says is able to replicate 100% of a customer’s data between two regions in 15 minutes or less, backed by a service level agreement.
Onto the new products, and Google announced Backup for Google Kubernetes Engine. GKE is the company’s fully managed Kubernetes service that’s used by enterprises to deploy and manage modern, container-based applications. According to Pangal, users are adopting GKE in droves.
“It’s a rocket ship for us,” Pangal told SiliconANGLE in an interview. “We’re seeing customers’ applications get more and more stateful, meaning more and more mainstream workloads. And they need data protection for that.”
Enter GKE Backup, a new service in private preview from today that’s designed to help GKE users better protect their container-based data.
“More and more of our customers are traditional enterprise customers, and we need to provide them with more simplicity,” Pangal said.
Also in public preview starting today is Google Filestore Enterprise, a new tier in Google Cloud’s fully managed file-storage service. It’s targeted at tier-one enterprise applications such as SAP Hana databases that need to share files.
In addition to high-performance reads and writes, Filestore Enterprise offers high availability via synchronous replication across multiple zones in a region. So if any single zone within a region becomes unavailable, Filestore will continue to serve data transparently to the application without any intervention required.
International Data Corp. analyst Matt Eastwood said enterprises want to spend minimal time on managing storage. They just want it to work automatically without needing to think about it.
“Although public cloud is growing fast, it is still new in many organizations, and skill gaps are something we know slows cloud adoption,” he said. “It is great to see Google Cloud focusing on ease of use as they bring new services to market.”
With reporting from Robert Hof
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





