BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
In order to support the vision of the sixth data platform, that is, a capability that allows a globally consistent, real-time, intelligent digital representation of a business, we believe the industry must rethink the single system of truth.
Specifically, we envision a new data platform that marries the best of relational and nonrelational capabilities and breaks the multi-decades tradeoffs between data consistency, availability and global scale. Further, we see the emergence of a modular data platform that automates decision-making by combining historical analytic systems with transactions to enable artificial intelligence to take action.
In this Breaking Analysis, we welcome two innovators, Eric Berg, chief executive of Fauna Inc., and S. Somasegar, managing director at Madrona Ventures.
Before we get into it, let’s set the context with some spending data from Enterprise Technology Research.

This chart above shows spending intentions data from the January survey of 1,766 information technology decision makers. We’re showing some of the top operational data platforms. The vertical axis represents Net Score, a measure of spending momentum on a platform. The horizontal axis shows the presence of the platform within those 1,700-plus accounts. The table insert shows you the data for each axis which informs the placement of the dot. The red dotted line at 40% indicates a highly elevated spending velocity level.
We’ve stretched the ETR taxonomy a bit here because the categories used in the survey do not break out operational from analytic databases. We know pure plays such as MongoDB Inc. represent operational data stores, but as the asterisk indicates, several firms such as Microsoft Corp., Amazon Web Services Inc. and IBM Corp. comprise multiple database types. That said, the following key points are worth noting:
This picture gives a view of the percentage of customers spending on these operational data stores. It is not a dollar value view, it’s a customer view – that is, the percentage of customers spending.
To get to a new vision of the single source of real-time truth, we need these operational data stores to be married with historical analytic data. With AI we bring intelligence and begin to enable automation, systems of agency and we can begin to build what we call intelligent data applications.
Q1. Soma, each year, Madrona has its IA Summit (Intelligent Apps). Please explain your point of view on what are intelligent data apps.
The following summarizes Soma’s thoughts:
Summary:
The initiation of the Intelligent Application Summit was inspired by the recognition of a pivotal shift in the tech landscape, moving from on-premises to software-as-a-service models, and the anticipation of a similar transformation toward intelligent applications. This transition underscores the growing importance of applications that are not just data-driven but are inherently capable of continuous learning and adaptation. The concept of intelligent applications is a critical evolutionary step, where the integration of AI and continuous learning systems within applications significantly enhances their value and utility, making them indispensable in the modern digital ecosystem.
Key points:
Bottom line:
The evolution toward intelligent applications represents a cornerstone in the ongoing transformation of the tech industry, signaling a future where continuous learning and adaptability become foundational to application design and functionality. This movement not only redefines the trajectory of application development but also emphasizes the necessity for companies to integrate intelligent capabilities to remain relevant. The Intelligent Application Summit serves as a catalyst for this transformation, providing a platform for leading innovators to converge, share insights and drive the industry forward. This initiative reflects a broader recognition of the critical role intelligent applications play in navigating the complexities of modern data architecture.
Q1a. Part of the focus of our narrative has been on how the data platform is evolving to support these types of applications. And, you know, sometimes you can find like a lighthouse example, not just of the applications, but an attempt at building the platform to support those applications. One example we use for the application side is Uber, where you have riders and drivers and fares. Another platform company that has attempted to enable these digital representations of things that are driven by data is Palantir. But there’s something missing in the platform, which we think is transactions, where you need to perform operations that require shared visibility. Walk us through how the platform needs to expand to support that type of application.
Soma’s answer to this follow-up question is summarized below:
Summary:
There are critical requirements in data systems essential for building AI-powered applications at scale. Microsoft’s acknowledgment of the necessity for a document-relational database such as Cosmos DB for AI applications highlights the market’s recognition of new types of databases. This aligns with Fauna’s mission, which aims to address the demands of modern applications through advanced data management solutions. There are foundational attributes of new data systems.
Key points:
Bottom line:
The evolving landscape of AI-powered applications demands data platforms that are not only versatile in handling a range of data types but also excel in global distribution, developer agility and stringent security measures. Advanced data systems will play a pivotal role in enabling the next generation of intelligent applications. By focusing on these core attributes, data platforms such as Fauna are strategically positioned to support consistency, availability and partition tolerance, something that traditional NoSQL databases could not offer.
This next graphic highlights some of the tradeoffs we’ve had to make over the years.

We use the metaphor of the Gordian Knot to describe these challenges. The legend of the Gordian Knot says that whoever can untie the seemingly intractable knot will rule all of Asia. Let’s come back to that….
Today we’re exploring how to rethink the single system of truth and untangle that knot with unconventional methods: Combining the best of SQL’s ability to join data and the schema flexibility of NoSQL. And solving for globally distributed consistency without the complexity of having a hardware-based atomic clock. And further breaking the tradeoffs of two phase commit – that is, having to choose between waiting for synchronization and scaling out nodes globally.
And not least, addressing Brewer’s theorem or CAP theorem problem, which says it’s impossible for a distributed data store to accommodate more than two of three key attributes: 1) consistency; 2) availability; and 3) partition tolerance, which is a fancy way of saying when things go awry between nodes, the system can recover without losing data.
Imagine a world where you didn’t have to make these tradeoffs. How would that change the way applications are written and the value proposition to customers?
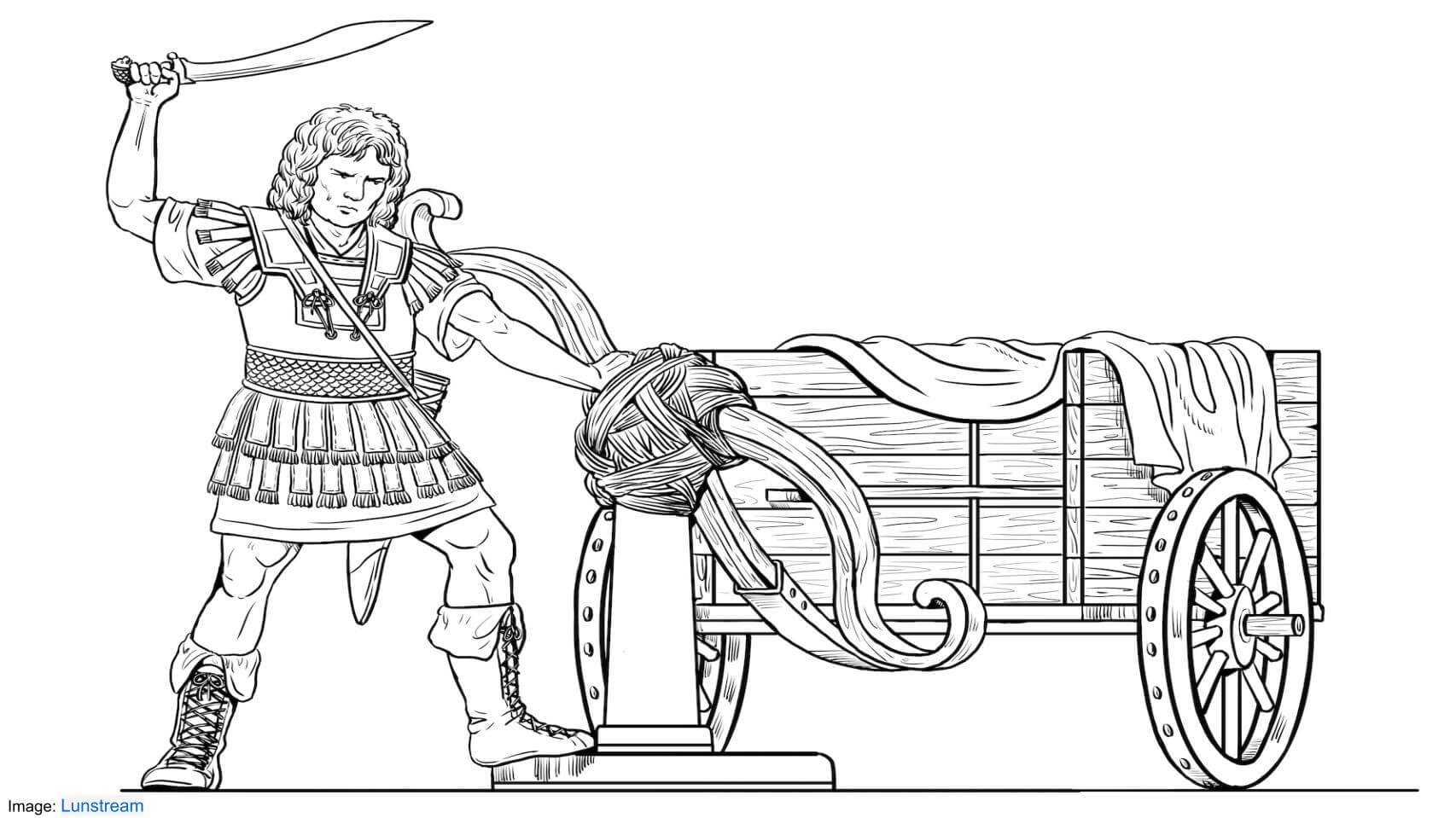
Alexander the Great slashed the knot with his sword. In essence he solved this impossible problem with an unconventional approach that broke the accepted rules and removed the constraints.
Q2. Eric, please explain what Fauna has done to rethink these tradeoffs and slash open the Gordian Knot.
The following summarizes what we heard from Eric.
Summary:
There are critical requirements and innovations in database technology that address the challenges faced by developers, especially in the context of building cloud-native, internet-facing applications. Data systems have to accommodate semi-structured data, global responsiveness and agility in the software development lifecycle. Fauna’s approach combines the best of SQL and NoSQL with a focus on being able to support agility by starting without a schema. Developers can get the benefits of schema management as their application evolves, providing structure for a team and a production application. Distributed transactions allow applications to scale globally.
Key points:
Bottom line:
Fauna’s innovative approach to database design and management directly tackles the challenges of building and scaling intelligent, responsive applications in a global context. By bridging the gap between SQL and NoSQL benefits, Fauna offers a solution that supports the rapid, agile development of applications that are based on rich data and globally distributed. This reflects a broader movement within the technology sector to create more adaptable and secure data platforms. Fauna’s advancements in handling semi-structured data, schema flexibility and distributed transactions are pivotal in modern database architecture, offering a blueprint for addressing the inherent challenges posed by creating real-time systems of truth.
In previous Breaking Analysis segments, we’ve talked about working with strings – that is, stuff that databases understand, such as rows and columns – and things or objects that represent people, places and things. To drill down on this, we see Fauna as marrying the best of MongoDB and the best of Google Spanner.
Q3. Eric, help explain how you can work with what starts out as a schemaless database, but then, as the application evolves, you might have different views of that data. In other words, you can still get the capability that SQL would give you with essentially the ability to join. But the developer still gets to work with objects – i.e. things – but the database has the flexibility of working with strings that it can join at scale. Can you elaborate on that?
Eric’s response is summarized below.
Summary:
The discussion delves into the innovative data model termed “document relational” that Fauna has adopted, marking a significant departure from traditional relational database models. This model leverages the flexibility of JSON and document formats while retaining the relational model’s power, addressing modern data and developer needs more effectively. The conversation also emphasizes the importance of evolving not just the data model but also the developer interface to better suit application development requirements. The Fauna query language or FQL is particularly adept at meeting these needs, offering a more natural interaction for developers familiar with modern programming languages and ensuring strong consistency and transactional integrity in data operations.
Key points:
Bottom line:
Fauna’s approach to database architecture, with its document relational model and FQL, represents a significant advancement in aligning database technologies with contemporary application development needs. By rethinking the fundamental aspects of data modeling and developer interaction, Fauna addresses the evolving landscape of software development, where flexibility, consistency and ease of use are paramount. This strategy contributes to the broader dialogue on overcoming traditional database limitations, presenting a compelling solution to today’s data-intensive environments.
Q3a. An important followup is that a relational database, say Oracle, could support JSON objects on top of an underlying relational model. But our understanding is it’s still schema-on-write, is that correct? So the developer still has to declare the data model of the database before they get started. And if we understand what you’re saying, Fauna can evolve as the application requirements evolve until the developer or the data architect feels like they are ready to nail down the schema. Is this a correct understanding?
Eric’s response follows:
That’s absolutely right. I think there are two key differences. The fundamental question is, “Can I just store JSON documents in a tabular database and be done with it?” There are two constraints. There’s the one that you mentioned, which is that ability to start with a flexible data model and then add the schema over time as you hone in on the structure. As I mentioned, we support schema enforcement as well as you would in a relational database.
The other piece you brought up earlier as well, which is you’re still then constrained with the query language that you’re working with, i.e. SQL. And that tabular data model, not being able to bring back data in the structure that’s required and needed by your application.
So when you have a more expressive query language that is more similar to TypeScript or JavaScript or Python, it allows the application developer to do that [more easily]. Application developers want that kind of power in the language that they use with data just as they do with their application code.
Q3b. And just again, to nail this down and be clear, you’re trading the declarative query of SQL. In other words, the ability to just say what you want and have the database figure out how to get it, because that’s really useful for complicated queries in analytic databases. And here you don’t mind expressing how to get the data in a TypeScript-like language because then you get to deal with the objects or things that your application system cares about.
Eric’s response follows:
Correct. And the other thing I would add to that is our co-founders experienced a lot as they were scaling the different data infrastructures in their careers. When you have that query optimization layer, you get very inconsistent [and unpredictable] performance. So as a developer who’s starting to build a system that really scales, there’s a real trade off that’s valuable to be able to dictate that.
Q4. IT folks in our community want to know where the tradeoffs are – the so-called “gotchas.” Eric, let’s double-click a little bit. In particular, we want to understand where the bottlenecks are. For example, if your transaction log is in a single availability zone, what happens if you lose that AZ? And if the log is not in a single AZ, how do you ensure that you can maintain adequate performance?
Eric’s response is summarized below.
Summary:
Fauna is not magic. It can’t solve the CAP theorem completely but it can address the inherent limitations it imposes. Think of Fauna as a CP (Consistency and Partition tolerance) system. At the end of the day Fauna runs into the unavoidable constraints of physics: the speed of light. The system’s design prioritizes consistent writes across regions, accepting the tradeoff of slightly higher latency in write operations to maintain strong consistency. As such, it will not have the performance of an eventually consistent database. Fauna compensates for this tradeoff with its distributed geographical architecture, enabling faster read operations close to the user location. Fauna’s approach to replication and the strategic deployment across multiple geographical zones enhances availability without sacrificing consistency, and is a nuanced balance within the constraints of the CAP theorem.
Key points:
Bottom line:
Fauna’s transaction log does not live in one AZ. Fauna’s approach to reconciling the challenges posed by the CAP theorem underscores a compromise, prioritizing consistency and partition tolerance while mitigating availability concerns through its architecture. This balance highlights Fauna’s north star to provide a robust, distributed database solution that navigates the speed of light’s limitations. By leveraging a distributed geographical presence and sophisticated replication strategies, Fauna offers a novel model for achieving strong consistency and high availability, pushing the boundaries of traditional database capabilities within the inherent constraints of distributed systems.
On Fauna’s Web page, there’s a section that caught our attention called “Why Fauna.” In this the company discusses its knockoffs relative to DynamoDB, MongoDB, Postgres, Aurora Serverless V2. As well, we’re interested in how it stacks up to Google Spanner.
Q.5 Eric, your competitors are entrenched, well-financed with large customer bases and as we showed with the ETR spending data, many have strong momentum. Please summarize your point of view on the limitations of today’s popular operational systems and address “Why Fauna?”
Eric’s response follows.
The operational database market is, I think, one of the largest markets from an IT spend perspective. As a result, there are a lot of different players. So the way I like to approach this is how we see our customers making decisions. Fundamentally, there is a branch at the top of the tree where if people have existing applications, for example, that are wed to SQL and they’re looking for a way to move to the cloud, and SQL is their query language of choice, which brings in Postgres and a lot of the RDS systems and Cockroach and others that you mentioned. Clearly, that’s not something that Fauna is focused on, independent of whatever those architectural differences are. That query language choice makes a big difference.
Fauna versus Postgres
Today, we do see people who will go from Postgres to Fauna, and it’s typically because they hit that multi-region expansion problem, and they’re really looking for a way to not have to take on all those cross-data center challenges themselves. In that case, they’re actually willing to migrate from something like Postgres or SQL to Fauna. Probably easier today is if people have made that choice upfront and said, ‘Hey, the flexibility, scalability, and performance of NoSQL is more important to me.’ For those customers, we are bringing to them all the power of a relational database that they had to give up as they moved to NoSQL.
Amazon DynamoDB versus Fauna
I mean, DynamoDB is a great example where I think they were one of the earliest and most popular serverless databases and they did a great job there. But if you talk to customers and get into Dynamo, it goes back to what Dynamo was designed for initially, which was really to offload a hotspot on a relational database and be able to horizontally scale read requests very quickly. Dynamo has a lot of tradeoffs. They have a very rigid data model called a single table design. If you know exactly what your application is going to evolve to and exactly what the read-write patterns are going to be, then it’s a great solution. But that doesn’t apply to most people who are building and evolving their application. Dynamo by default is single region. It takes a lot of work to make it work across regions. And by default, it’s eventually consistent. You can pay a lot more and try to configure it to approximate strong consistency, but you absolutely don’t get that out of the box.
MongoDB versus Fauna
Mongo is a great example, and one that we look at in terms of answering your question of how do you grow a new franchise in this market? One of the things that Mongo did very well is they intercepted a lot of net new development and then grew with their customers. That’s a big part of how Fauna started out as well, attracting these modern developers who are building these new applications, sometimes in very large enterprises, sometimes in smaller customers. And now increasingly we’re also starting to see people migrate off of that. Mongo again, they have the document piece down, which I think is great because that’s fundamental and core to us, but we brought all that relational capability that you don’t get. And then we’ve abstracted the operational level up so that you have a pure API. So instead of, like for example, their popular Atlas service, you still have to know about the hardware underlying the service. Again, with Fauna, that’s completely taken care of for you, and it’s available globally. And then the last thing I’ll mention is while they have a query language that is not SQL, it’s relatively limited in terms of what you can do as a developer. And back to our earlier conversation, FQL is a very expressive language, similar again to TypeScript and Python, and it allows developers a lot more power, the relations, the joins, etc., but also in terms of how they structure their data for their application. So it’s much more developer-friendly.
Q5a. Eric, popping back up a level where we have these future intelligent data applications using Uber as an example, where things in the real world change like a rider requests a driver, the system has to match the rider with the driver, it has to calculate a fare and a route and an ETA. What we’re trying to understand is how much of that app lives in this real-time system of truth, which then orchestrates all the other transactions, to the extent there are transactions, and how much lives in the historical system of truth and who orchestrates that whole flow where that happens? Can you elaborate and enlighten us?
I think, like any application decision, there are tradeoffs in terms of how you approach it. We’re a fan of a best-of-breed approach and having strong integration with systems that do things uniquely well. For example, we’re not focused on compute, historical reporting, or traditional OLAP workloads. We haven’t pursued vector capability, deciding instead to partner with Pinecone and others who are best of breed in that area. This speaks to our architecture and the types of applications we see being built.
We are an API, consumed as an API, making it very easy to integrate Fauna into a more event-driven, loosely coupled architecture. Our answer, in terms of what we see, is that we are handling core transactionality, determining where the issues are and resolving them. We’ll be fed from either results that might be done offline in batch mode, then updating information in Fauna that partakes in that query, to actually resolve issues like new driver, new location, etc. Conversely, we’ll get information out of Fauna into warehouses, whether it’s Snowflake or Databricks or wherever that might reside. We believe in a best-of-breed, integrated architecture in that world.
Bottom-line takeaway: The application objects, like the rider and the driver, might be Fauna objects. And if they need to be informed about historical data, they would be informed by the historical system of truth. But the application objects that need real-time state would live in Fauna.
Q6. Soma, Eric referenced earlier that the majority of spend is on these types operational systems is large. How do you think about the Fauna total available market. What is its market opportunity and how will Fauna tap that opportunity from a go-to-market perspective? Summarize your investment thesis and in doing so think about how the market seems to have shifted from emphasizing operational databases to analytic databases over the last decade or so. But when we have intelligent apps that are driven by data that need to have visibility on transactions comes into play. How does that dynamic change again?
That’s a great question. The simple answer to how we think about TAM is it is huge. It’s humongous. As Eric mentioned, the operational database is probably one of, if not the largest, spend items in IT budgets. This has been the case for many years now, and it’s only growing as the world uses more data, and new kinds of applications come that have an enormous appetite for this data. Whether it is $200 billion or $400 billion or $600 billion, different people can come up with different charts and numbers, but they’re all large enough that we think TAM is not the issue here.
The reason why we got excited about Fauna, I would say, is twofold. One is if you look at the co-founders and the founding team for Fauna, the pedigree, background, and experience they’ve had building at scale data systems in other enterprises and understanding what works and what doesn’t work and having a pulse for what modern developers need in a database. We felt that that pedigree was fantastic.
The second thing is, as we know, data explosion is happening. There’s a new class of applications, whether it’s intelligent applications, applications on the edge or IoT-driven applications. There’s a whole class of new applications where they need access to data in a globally available way with low latency and high performance.
We felt like if somebody can pull together a system that meets all of these attributes in a serverless form, then we thought that’s a database that can have legs and can have a meaningful play in the ecosystem.
As you guys talked about the competitive landscape, there are a lot of database systems, so you’ve got to be thoughtful that on the one hand, there’s a lot of demand, but there’s also a lot of supply. But when you see inflection points, whether it is platform inflection or the kinds of applications that are being developed, there is an inflection point. In this situation, you want to think about what is the database system that provides the best use case and best value for people who are building data-driven or AI applications? That’s the reason why we got excited about Fauna. We think a system like Fauna that’s truly global, truly available, and has the consistency that people need in today’s day and age in terms of being agile and being able to move things fast around the world, there is a huge opportunity.
Q6a. Just a followup on that, Soma. Because the answer that it’s huge is perfectly reasonable, but it’s also nuanced. In other words, when we think of, for example, the early days of Snowflake, it was very easy to understand the separation of compute from storage, the massive scalability of the cloud and the simplicity of Snowflake’s design is going to target and replace platforms in the market – for example, Teradata. That was the entry point for Snowflake. Then they embarked on a TAM expansion strategy and their TAM is huge. It’s data. So the question is, what is Fauna’s approach to tapping its TAM? Are there outside dependencies where certain pieces have to line up or come together or is there a more clear vector for the company?
Soma’s response follows.
Just to revisit your point, I was also an investor in Snowflake, so I have some knowledge in this area. I can tell you that when Snowflake started, their focus was on building the best cloud-based data warehousing solution. Over time, they expanded into data sharing and eventually evolved into a data cloud platform. Their TAM has been expanding as their aspirations grew.
Now, when we look at Fauna, there are two interesting use cases to consider. One, as Eric mentioned earlier, when organizations using existing database solutions reach a point where they need to scale or expand geographically, and their current system can’t meet those scale needs, they start looking for a new solution. How can we tap into this and get them excited about Fauna? Migrating databases can be hard, but sometimes it’s necessary for an application’s continued success, and Fauna is well-positioned to assist in these cases.
Secondly, as organizations embark on creating new AI-driven applications, edge applications, and other innovative projects, they will search for the best-suited system. I believe Fauna will be at the top of their list when considering these new opportunities. In some cases, Fauna might have the opportunity to attract users away from other database systems, especially when they encounter limitations and seek a new solution. As the pipeline of opportunities expands, Fauna has the potential to secure a meaningful share.
Eric added the following commentary:
And if I can add to that. I totally agree. I mean, you know, a significant part of what you have to do in one of these massive platform businesses, and I’ve built a few of them, is precisely what Soma said. You have to focus in on your wedge initially. I’d go a step further, and I know Soma knows this. In the very early days of Snowflake, it was failed Hadoop deployments that they were able to pick up because they had great support for semistructured data, and they didn’t have to do all of this data model conversion. They were able to go in there and swoop those up very early.
For us, the moral equivalent, as I was talking about earlier, is people who’ve said, ‘Hey, I want to go to documents, I want to go to NoSQL for that flexibility, et cetera, but are really hitting pain points because of the scale or the desire to bring in relational capability, querying power at strong consistency, et cetera. That’s our failed Hadoop equivalent.
Now fundamentally, because Fauna is a document-relational, and, as you guys started out your slide with the [Gordian] Knot, there’s a massive opportunity over time. But we’re focused on where the most pain is and where the least religious tension is, if you will, from a query perspective. Then as it gains scale, just like something like Snowflake, you get to waves and broader waves of adoption as people’s risk tolerance goes down.
Many thanks to Eric Berg and Soma Somasegar for sharing their perspectives on the market. It’s clear to us that new capabilities are required to support intelligent, real-time data apps. Innovators such as Fauna will come up against established players that are well-funded and continuously evolving their platforms. Perhaps a company like Fauna will be absorbed by one of those as part of that evolution. Or perhaps Fauna will reach that coveted escape velocity, which eludes so many firms.
What do you think? Is Fauna’s approach compelling? Is the TAM enormous and what chances do you give them in the future?
Let us know what you think.
Thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight, who help us keep our community informed and get the word out, and to Rob Hof, our editor in chief at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com, DM @dvellante on Twitter and comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail. Note: ETR is a separate company from theCUBE Research and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai or research@siliconangle.com.
Here’s the full video analysis:
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of theCUBE Research. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.