

















 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
The way to solve business resiliency is not inventory, it’s software – Duncan Angove, CEO of Blue Yonder
The “sixth data platform,” or intelligent data platform, represents a cutting-edge evolution in data management.
It aims to support intelligent applications through a sophisticated system that builds on a foundation of a cloud data platform. This foundation makes it possible to integrate data across different architectures and systems in a unified, coherent and governed manner. Harmonized data enables applications to use advanced analytics, including artificial intelligence, to inform and automate decisions.
But more importantly, a common data platform enables applications to synthesize multiple analyses to optimize specific objectives, ensuring, for example, that short-term actions are aligned with long-term impacts and vice versa. More than just a dashboard that informs decisions, this system increasingly incorporates AI to augment human decision-making or automatically operationalize decisions. Moreover, this intelligence allows for nuanced choices across various options, time frames, and levels of detail that were previously unattainable by humans alone.
In this Breaking Analysis, we introduce you to Blue Yonder, a builder of digital supply chain management solutions that we believe represents an emerging example of intelligent data applications. With us today to understand this concept further and how it creates business value are Blue Yonder Chief Executive Duncan Angove and Chief Technology Officer Salil Joshi.
Let’s frame the discussion with some of the key issues we want to address today.

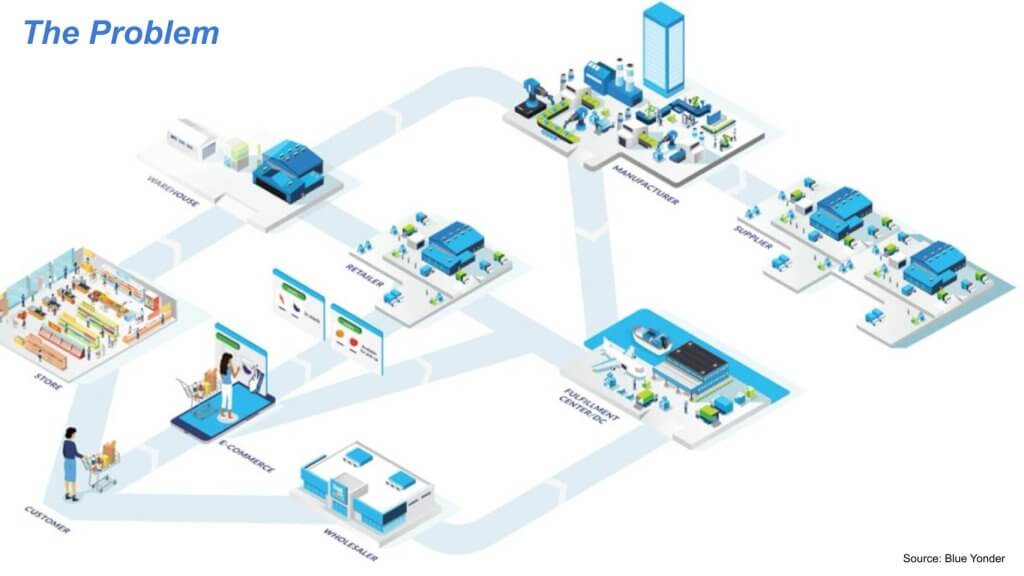
The practice of supply chain planning and management has evolved dramatically over the past couple of decades and hopefully we’re going to help you understand how legacy data silos are breaking down, how AI and increased computational capabilities are forging new ground, and the technologies that are enabling much greater levels of integration and sophistication in planning and optimization across a supply chain ecosystem. We’ll try to address how organizations can evolve their data maturity to achieve a greater level of planning integration and how they can dramatically improve the scope of operations and their competitive posture.
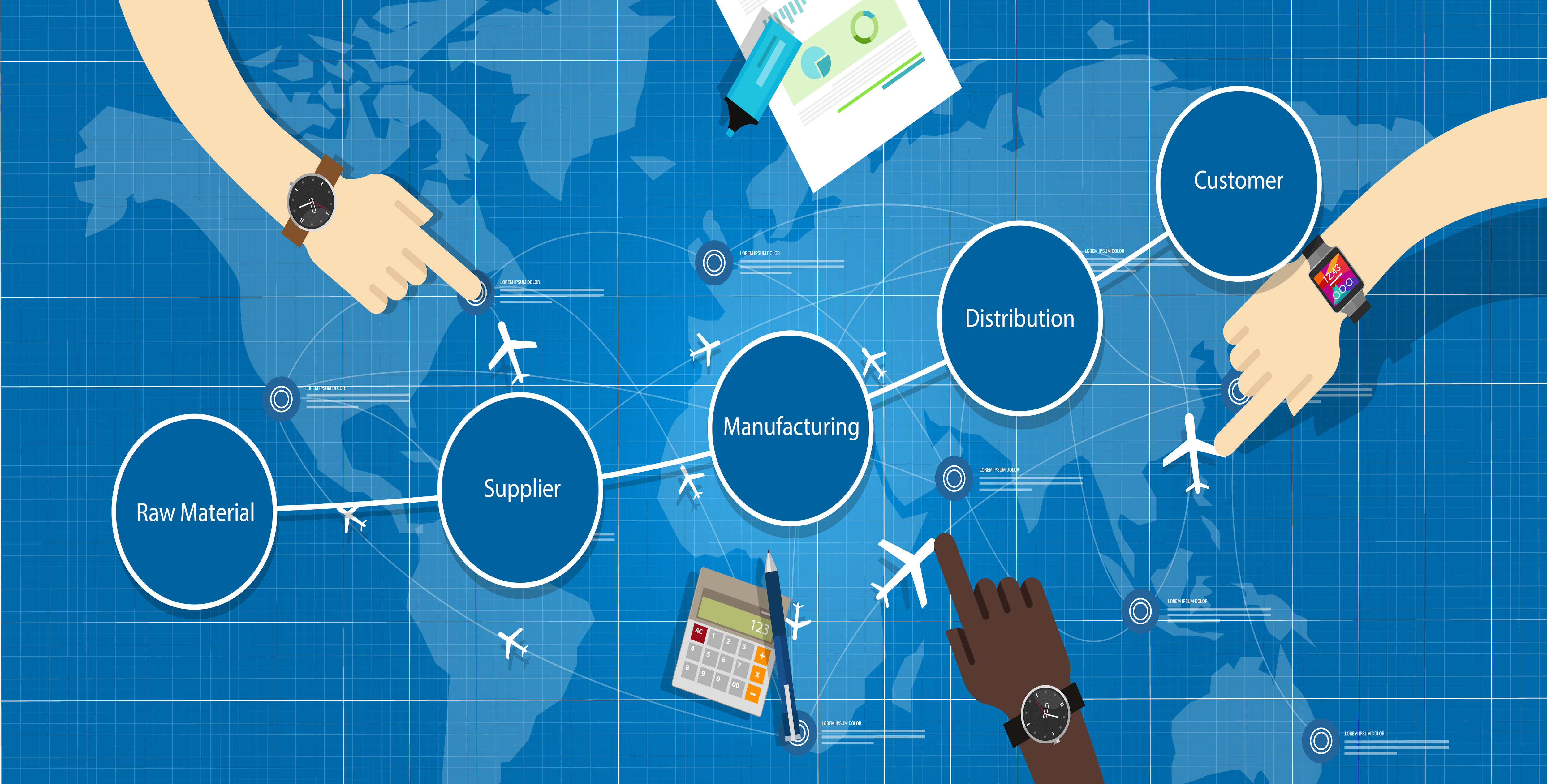
Below is a graphic that we scraped from the Blue Yonder website. The goal here is to optimize how to match supply and demand according to an objective such as profitability. To do so, you need visibility on many different parts of the supply chain. There’s data about customer demand and different parts of an internal and external ecosystem that determine the ability to supply that demand at a given time. The data in these systems historically has been siloed, resulting in friction across the supply chain.
Duncan Angove elaborates:
Supply chain is arguably the most complex and challenging of all the enterprise software categories out there, just because, by definition, it’s supply chains that involves multiple companies versus one like an ERP or a CRM dealing with customers, and just the data and complexity of what you’re dealing with when you think about, if you’re a retailer, SKU times location times day. So it’s billions and billions of data points. And so, that makes it very, very challenging. So you have to predict demand at the shelf, and then you have to cascade that all the way down the supply chain, from the transportation of the trucks that get it there to the warehouse, inbound and outbound, back to the distributor, the manufacturer, that manufacturer’s supplier’s supplier’s suppliers.
So it’s very, very complex in terms of how you orchestrate all of that, and it involves billions and billions of data points and extreme difficulty in orchestrating all of that across departments and across companies. And supply chain management, unlike other categories of enterprise software, has always been very fragmented, to the point that Dave made. And that means it’s fragmented in terms of the data, the applications, a very diverse application topology, which means you have unaligned stakeholders in a supply chain. Because of the volume that’s involved here, it’s generally being a very batch-based architecture versus real-time, which means there’s a lot of latency in moving data around, manipulating it, and all of that.
And it’s generally being limited by compute, which means that, again, it’s batch-based, and companies generally trade out accuracy for time. It just takes too long because of the compute, and it’s generally been very, very hard to run in the cloud, because it’s mission-critical. It requires instant response time. If you’re trying to orchestrate a robot in an aisle in a warehouse, that requires instantaneous decisioning and execution. So it’s very, very challenging from that perspective. And at the end of the day, it’s fundamentally a data problem and a compute problem. So that’s how I would characterize it.
Salil Joshi adds the following technical perspective:
So if you think about supply chain problems and the functional silos that, inherently, supply chain is in, the fairly static nature of how supply chains have been in place, today, technology is such that we are able to solve a much larger problem than what we used to in the past, where we are basically saying that in the past, our ability to solve problems was limited by, to point Duncan made, around the compute. We now have hyperscalers like Microsoft, who are able to provide us an infinite compute.
Through the Kubernetes clusters that we have, we are able to scale horizontally and solve the problems that we, frankly, were not able to solve in the past five, 10 years. The whole nature of having a data cloud now available to us, separating compute against storage, that allows us to scale in a manner that is a lot more effective, cost-effective, as well as ability to be a lot more real-time than what we were in the past. Again, from a data cloud perspective, one of the things that has always bogged supply chain issues is integrations.
If you think about all of the different systems that we need to have in place from an integration standpoint, data flows from one to another system. It was extremely complex. Now, what we have is ability where we are able to materialize data in a much more seamless manner from one aspect of the supply chain to the other aspect, so that visibility is there. And the ability to then scale that beyond what we had in the past is now evident. So, for example, we partner with Snowflake, and what we have leveraged there is this aspect of zero-copy clones, which is really an ability to materialize data, clone data, without replicating it over and over again.
And as a result of which, we can play out operational scenarios, figure out what is going on by changing the levers, and then choosing what is the most optimal answer that we want to get. So the modern data cloud is helping us solve problems at a scale that we were not able to solve in the past. And finally, adopting generative AI to really change the interface of how users have used supply chains in the past is also a very important aspect of how we solve supply chain challenges in the future. So these are the various different technology advances that we see now that we are able to use to solve some of the challenges that Duncan talks about, from a compute perspective and from a data integration perspective.
Q. Salil, Duncan had talked about the scope of supply chains now. And when you’re talking across companies in an ecosystem, even within a single company, all those legacy applications are silos. How do you harmonize the data so that your planning components are essentially analyzing data where the meaning is all the same?
Salil’s response:
So it starts with the data. Traditionally, in supply chain, data has been locked within application silos. And that has to come together meaningfully in what we call a single version of the truth, have a single data model that is consistent across the entire enterprise, bringing the canonical data form in place such that we are able to define all of the atomic data and store the atomic data in a single place, in the right data warehouse. On top of that, then you need to establish or have what we are calling the logical data model or the semantic data model, in some sense, the enterprise knowledge graph, where you have all the definitions of the supply chain for that particular enterprise defined in a very, very consistent manner, such that you have all the constraints defined in the right manner. You have all the objectives that are connected in the right manner, and all of the semantic, logical information that is needed for solving the supply chain problems consistently are available. So once you have the data in a single version of truth, and then this logical data model, you can then have applications connect to each other in a meaningful manner where not only the data, but the context is also passed in a relevant manner.
Q. Just to clarify, the knowledge graph, is that implemented inside Snowflake as a data modeling exercise versus another technology that is almost like a metadata layer outside the data cloud?
It definitely uses Snowflake, but there is a technology that we have used about Snowflake, on top of Snowflake. There are a couple of ways. We have homegrown technology, but also leverage technology from RAI (RelationalAI) that builds the knowledge graphs to allow us to solve the larger, complex optimization problems.
Our discussion further uncovers that along with Blue Yonder IP, this all runs as a coprocessor natively inside Snowflake for those specific workloads. According to Duncan Angove, it’s particularly good at solvers and AI. But it runs in a container in Snowpark and is native to Snowflake.
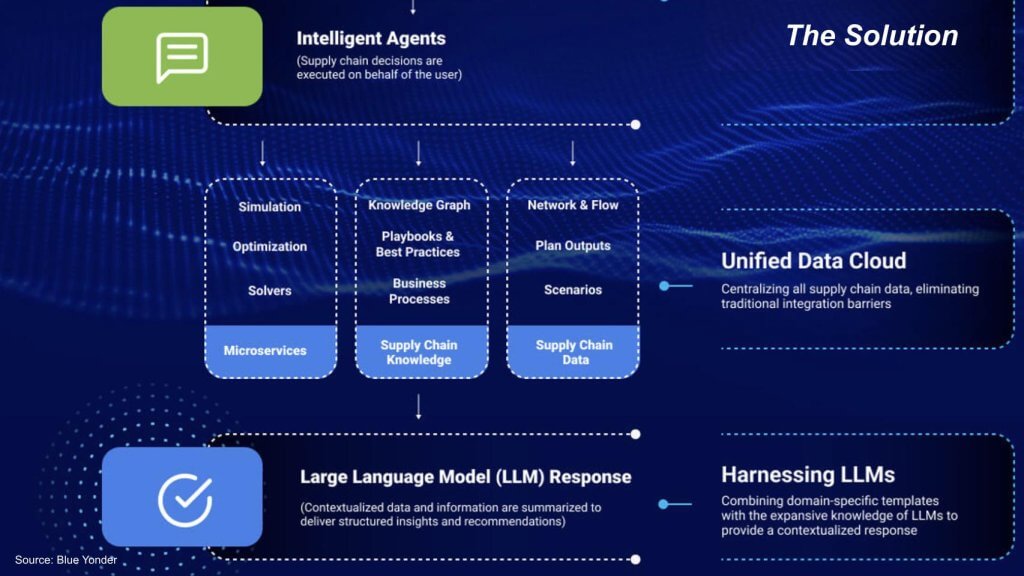
We pulled the above conceptual framework from Blue Yonder’s website. It basically describes the company’s technology stack. Our take is the approach is to gain visibility within all the parts of the supply chain, but to solve the problem it takes an end-to-end systems view. Once you have visibility, you can harmonize the data, you can make it coherent, and then you can do analysis on not only the individual parts, but how they fit into the system as a whole, and how all those perspectives inform each other. And the point is, this is an integrated analysis with a unified view of the data. You’ve got domain-specific knowledge, and then you contextualize that data, not just from an individual component point of view, but the entire system.
Q. Please explain how you think about the Blue Yonder stack and how you think about solving this problem.
Salil responds:
As I mentioned, the first thing is to have the data in a single version of the truth, and establish that in place, have the logical data model defined in a very dynamic manner. So those are the two first building blocks of the piece. We also then have what we call an event bus, because of the fact that, Duncan mentioned this, that supply chains were traditionally in a batch mode. And now, with the requirement for real- time responses, with the requirement for event-driven responses, we have an event bus on which all of the supply chain events get carried through, and these events are then subscribed to by the various microservices that we play out across the entire spectrum of our supply chain.
So what will end up happening is, as an event is coming through, whether it be a demand signal, whether it be supply disruptions that are happening, these events are then picked up by the various microservices on the planning side of the equation or the execution side of the equation, such that the appropriate responses are provided. And not only that, once the event is treated, understood, reacted upon, then signals and actions are sent to downstream processes, where the downstream processes then take that into account and then take it out into actioning and execution. So that’s the overall view that we are putting in place together where, one, you have the data, the logical data ability to take in events, understand what that event does from an insights perspective, create the actions that are required for downstream processes, and make sure that those actions are executed against. Once those actions are executed against, you get a feedback loop into your entire cycle such that you have continuous learning happening through the process.
Q. You had mentioned agents earlier. Some of what we’re learning about is that agents, the way we’ve seen them referred to so far, are intelligent user agents where they’re sort of augmenting the user interface. But we’re hearing from some people as well that some of the application logic itself is being learned in these agents, where we’re used to having deterministic application logic specified by a programmer. But now, the agents are learning the rules, but probabilistically. Can you explain the distinction between an intelligent agent that augments a user looking at a dashboard and an agent that actually is taking responsibility for a process?
Salil’s response:
I’ll give you an example in the forecasting world. In the past, we would forecast based on historical data and then say, “Here is a deterministic calculation of what the forecast will look like from the history,” and you get a single number for it. And let’s say the answer is X amount at a particular store at a particular time. Now, in the new world, you get multiple signals, which are causals in nature. Right? There are some which are inherent within the enterprise, some that are market-driven.
And you need to kind of get a sense of, what are the probability of those causals to happen? And as a result of that probability, what is the range in which an outcome will take place? So, for example, instead of having one number for a forecast, you now have a probability curve on which this forecast is available to you, where, depending on the different causals that are out there, you will have a different outcome. And what will end up happening is, when you have that information over a period of time, a system will learn the manner in which these probability curves are taking effect in actuality, and that those learnings will, again, make the system far more intelligent than what it is today. And as a result of which, you start getting more and more accurate answers as the system learns.
Duncan adds:
It’s a very good question because fundamentally, prediction and supply chain is where the field of operations research started…remember the milk run, the beer run solvers, which aren’t sexy anymore, because now gen AI is what’s sexy, and then you had deep learning, machine learning applied to it, and now there’s generative AI. Those former things, to your point, are deterministic. Precision matters. It’s mathematics. Right? These are stochastic systems. Hallucination here is good. It’s called creativity and brainstorming, and it can write essays and generate videos for you. That’s bad in math world, and they’re not good at math today. However, they’re going to get better and better and better. So when we think about intelligence, it’s the combination of all of these things. We’ve got solvers that do a phenomenal job, for example, in the semiconductor industry, ran the table last year, because it does a very good job of that.
We’ve got machine learning. We run 10 billion machine learning predictions a day in the cloud for fresh food, because it’s very, very good at that. Right? And then you’ve got generative AI, which is good at inference and creativity and problem-solving. The combination of those three things we sort of refer to as the cognitive cortex. Right? It’s the combination of those three things, which gives you a super powerful result. And then there’s tactical things, like the token length of the field. It would be insane if we use Gen AI for forecasting. What are we going to do? Feed 265 billion data points into the prompt box? No. So what happens is, as Salil was talking about this event-driven architecture, as events happen, that’s a prompt. It goes into a prompt, and Gen AI knows to call this solver to do this. And when it figures out what it should be doing, it calls an execution API, “Move a robot in a warehouse to pick more of this item. ” Right? That’s sort of how it hangs together.
And Gen AI is the orchestrator, that’s what we call it, the Blue Yonder Orchestrator.
Q. As the agents get better, or as the foundation models get better, at planning execution, do you see them taking over responsibility for processes that you’ve written out in procedural code, or do you see them sort of taking on workflows that you couldn’t have expressed procedurally because there are too many edge conditions?
Duncan responds:
I think it’s a bit of both. So first of all, people are trying to use gen AI to solve problems that have already been well-solved by other technology, whether it’s ML or it’s a solver or it’s RPA, which isn’t sexy anymore either, or enterprise search. Let’s use it for what it’s good at and understand the deficiencies it has right now. And again, it’ll get better and better. Our belief is, is that things that can be learned and are heavily language- or document-oriented, are ripe for this. That’s why it’s gone after law and all of this other stuff. Right? It’s easy to do that. Listen, supply chains run on documents, as you know, purchase orders, bill of ladings. Right? It’s all that EDI stuff that we used to dread. Those are all documents. So there are things there that will be easier to do.
Our belief is that workflow applications where it’s very forms-based are at high risk of being displaced for sure. Planning is much, much harder. No one wants to look at a time horizon pivot table through a chatbot. I mean, no one wants a chatbot on top of their Excel. You might want some generative AI embedded in cells and stuff like that, but those will be harder to go after, and they do require the intellectual property we have around solvers and ML and all of that. But ultimately, we’re shipping agents that amplify all the different end-user roles that we have. But some of them will go a long, long way to reducing the amount of work they have done, repetitive stuff. There are some roles, like super sophisticated planners in semiconductor, where it’s harder, but there’s still progress you can make there. But at the end of the day, these things are just going to get smarter and smarter. I mean, let’s be clear. The large language models today don’t even learn. Memory is a new thing. So you would like to think that the longer an end user interacts with their own agent, it learns their style of working, it remembers context, and it just gets better and better and better and more useful over time. And it will happen a lot faster than we think.
In a somewhat tangential conversation we discussed the the linkages between the digital and physical worlds, the relationship to the sixth data platform and the fundamental “plumbing” that’s been laid down over the years – in robotic process automation, for example – and of course in supply chain. The following summarizes that conversation:
Gen AI is a threat to legacy RPA systems as shown in the Enterprise Technology Research data. During the COVID-19 pandemic, RPA saw a significant surge above traditional momentum lines. However, with the advent of large language models, the enthusiasm for standalone RPA solutions has waned. Companies that have not transitioned to more comprehensive, end-to-end automation vision are beginning to see the limitations of their approaches.
The importance of connecting digital capabilities to physical world applications cannot be overstated. Effective automation systems do not just operate in a digital vacuum; they integrate deeply with physical systems, allowing for tangible actions like rerouting traffic or managing logistics. The foundational work done by RPA technologies, laying down the digital plumbing, is critical as it enables this bridge between the digital and the physical worlds. The same is true in supply chain.
For example:
This is why we’ve been wanting to talk to Blue Yonder in the context of the “sixth data platform,” which we’ve described as the “Uber for everybody.” This platform aims to contextualize people, places and things — elements commonly understood by the public (i.e. things), but often abstract in database terms (i.e. strings). The challenge and opportunity lie in transforming these abstract data strings into actionable real-world entities.
In practical terms, this involves:
We see this holistic approach to digital-physical integration as crucial for the next generation of intelligent data applications, ensuring that technological advancements translate into effective, real-world outcomes.
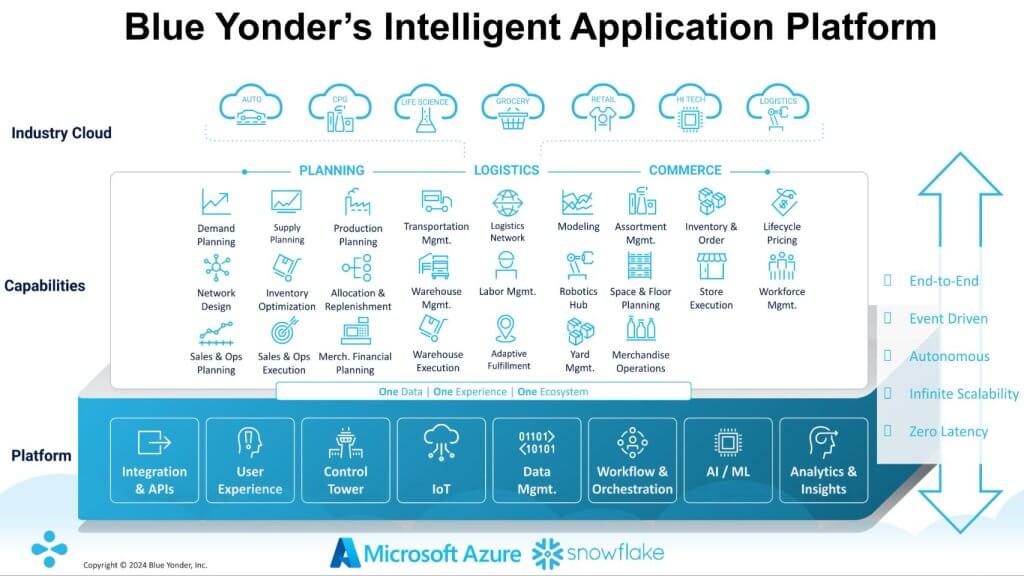
The graphic above depicts the various parts of the Blue Yonder solution. We wanted to better understand the technical elements of this picture. We asked Blue Yonder to explain how the applications it delivers work together using that common view of data that we’ve been talking about. How do you integrate all the analytics such that the applications that have different details can inform each other?
Duncan frames the conversation as follows:
I’ll tee up the design, what the design objectives were, and how what’s happening in the world shaped it, and Salil can bring it to life with the application and tech footprint and some examples.
So no one knew what a supply chain was before COVID. It’s funny, when something breaks, people suddenly recognize there was something doing something. But reality is, we’re going through a generational shift in supply chains we haven’t seen in 30 years or 40 years. For the last decades, it’s been about globalization and productivity, and let’s use China as the world’s factory and then ship stuff everywhere. And the philosophy was all around just in time. OK? Those two things kind of did it. And there is so much disruption happening now, the rewiring from China, the re-shoring of manufacturing, the friend-sourcing. There’s sustainability. There’s e-commerce. There’s demographic time bombs with labor shortages. There’s the impact of climate change, the Panama Canal, the Mississippi River, global instability, the Houthis, you name it.
We’ve never seen it like this. So J.P. Morgan did a report of 1,500 companies in the S&P, and in the last two years, working capital has increased by 40%. That’s inventory. It’s staggering, right? That’s money that isn’t being invested in growth or in the consumer. It’s sitting on someone’s balance sheet. That can’t be the answer to resiliency. The answer is software, and reimagining how a supply chain should run with software. And what companies need is agility. They need the ability to aggressively respond to risk and opportunity, and they need to be fully optimized. So the things that you need technically there is you need visibility. It’s hard to be agile if something hits you at the last minute. You need to be able to see there’s a supply disruption. Today, it takes, on average, four- and-a-half days for a company to learn of a disruption in supply.
That doesn’t work. You can use prediction in AI. I can predict that I’ll have a supply issue, that this order is going to be late, that this spike in demand is going to be happening. So agility is critical, and it’s fueled by technology. The second thing is, how do you aggressively respond? It’s very hard in supply chain to do that, because everyone’s siloed. You need everyone coordinated to go solve a problem. The logistics people that are scheduling trucks need to talk to the people in the warehouse, in the store, the people that are figuring out what to buy. That has to operate as one, and it doesn’t today because it’s in silos, and all the data is fragmented and everywhere. So that’s the second thing. And then to be fully optimized across all of that, you need infinite compute and you need unified data, and you have to get out of batch, and you have to connect the decisioning systems, which is planning, to the execution systems.
Those are the things that you need. That design point actually describes an intelligent data app. That’s exactly what solves this. So that’s a little bit on the design point we aim for.
Q. Salil, give us an example of a use case, of a supply chain where there is an unanticipated disruption and you need to replan so that you’re changing both your long-term plans and your short-term plans, and you want to harmonize all those things, and then drive execution systems with a new set of plans.
So take, for example, a large order has just come into your laps. You had a plan in place. That plan had been sent to your warehouses, the logistics systems, and all of that is in place and it’s in motion. And a large order that has come in and preempted, right? This preemptive order now has come in, is, one, there is an order reprioritization that has to happen. Once that order reprioritization has happened, it has to then go into your execution systems where now, suddenly, the warehouses have to be aware of the fact that, “Oh, now my pick cycles have to change. My shipping has to change. The logistics plan that was in place and was in execution has to change. ”
And today, as Duncan mentioned, these signals are not in real time. These signals happen in a batch environment. So what ends up happening is you are not able to respond to this large order that has come in. So what we have started putting together is this interoperability, as we call it, or the connection across the various different systems where… And all the way from the planning side of the equation to the execution side of the equation, there is a connection.
Now, the interoperability, in this most basic form, could be just data integration, right? But that is not good enough. The data integration and the level of evolution is to say, “Now I have workflows that I have established that are able to connect the different changes that.… The start point of the disruption and all of the consequences downstream into the system are connected by a workflow basis.” The final evolution of that is that I’m able to orchestrate all of the pieces of the puzzle that I have within the supply chain together, and optimize it together. So that is really the nirvana that you draw into.
Duncan adds several key points including a focus on sustainability:
Just a really simple example. Companies spend so much time and intellect on the plan. It’s probably the smartest people. That’s where the AI is. There’s all this manipulation to get it there, and it doesn’t survive the day. You release it out, go pick these orders. We’ve forecasted demand at the store, all of that. And what you know is a robot goes down an aisle, and by the way, we’ve not just planned the perfect order, we’ve optimized it in transportation. The load is full. The whole thing is beautiful. Right? A robot goes down an aisle, and the inventory’s damaged for one of the items that have to go on the truck. And what happens today is that truck goes out without those orders on it and we short-ship a store, because there’s no closed-loop feedback, there’s no event, anything. Right? What happens in the future world is the robot goes down there.
It immediately communicates that order, “Item number seven is not available. ” It calls an order sourcing engine, figures out it can pick up from another source, communicates back to the planning system. The planning system says, “Put this order on that truck instead. ” It calls load building, re-optimizes the load, and that truck goes out full. Full, and the order is satisfied. All of that happens in seconds when you connect all of this stuff in real time and you have infinite intelligence. By the way, it’s also a more sustainable order. You sent out a less-than- full truckload in the previous example, so this is also more sustainable. And that’s saying: Obviously, we announced the signing of one network last month, which takes that same value proposition across a multi-tier network. So the same example could have been where, instead of the inventory being damaged in an aisle, it could be a supplier communicating to you, “Hey, we can’t fulfill this order.”
You automatically find an alternate supplier. It calls the carrier. The carrier won’t tender the load, unless it knows that the dock door available, calls the dock door system, “Yes, the door’s available. Yes.” And the whole thing is just orchestrated. So planning becomes a real-time decisioning engine. The whole thing is event-driven. So it’s more sustainable. It’s more efficient. It’s more resilient.
In our view, this is the best application use case that we’ve had for the intelligent data platform, which is, once you’ve got this data harmonized from all these different sources, even outside the boundary of a company, then you harmonize the meaning. The technology seems to be a knowledge graph. It’s not clear to us, actually, how else you can do it other than embedding the logic in a bunch of data transformation pipelines, which is not really shareable and reusable. But then once you’ve got that data harmonized, you have visibility, and then you can put analytics on top. But it’s not one analytic engine. It’s many analytics harmonizing different points of view. And then, whether it’s through RPA or transactional connectors, that’s how you then drive operations in legacy systems. That’s the connection between the intelligent data platform driving outcomes in the physical world.
Q. Is that a fair recap of how you guys are thinking about solving this problem?
Duncan responds with a view of how this changes enterprise software deployments:
That’s right. And there’s actually another element to this. It also changes the way enterprise software is deployed. So the way you’d normally deploy a planning system is you have to go and use ETL from all these disparate databases and applications. You batch-load it into the plan, and then you do a bunch of planning, and all of that. In the new world, I mean, just say half our customers at least use SAP. Most of that’s the planning data that we need. They’ve already got it in Snowflake. We go to the customer and we say, “Can you give us read access to these fields?” We don’t move the data. We run the intelligent data app natively on it. There’s no migration. There’s no integration. There’s nothing. The knowledge graph provides context and allows us to understand what it is. “Oh, wait a second. We want to grab some weather causals.” Snowflake Marketplace. The data is already in the unified cloud. We’re not moving anything. We’re just doing a table join.
“Oh, the CPG company would like to see what that gross has planned.” You’ve got your CPG data as: Hey, there’s a join between the CPG data and our data and the causal data, and we’d run our forecasting engine on top of it. It’s game-changing. You move the applications and the process to the data. You don’t do the opposite. So the speed at which you move is dramatic. We’ve deployed all of our intellectual property as microservices on the platform. It’s a forecast as a service. It’s a load build as a service. It’s slotting optimization in the warehouse. So these are all intelligent data apps sitting on unified data.

We’ve chosen supply chain as a great example of the sixth data platform or the intelligent data platform. As we heard from Blue Yonder, supply chain is a great example because it’s complicated and there are so many moving parts. There’s a lot of legacy technical debt that needs to be abstracted away.
To take advantage of these innovations, you have to get your data house in order. Blue Yonder and Snowflake’s prescription is to put all data in the Data Cloud on Snowflake. This is a topic for another day, but there are headwinds we see in the market in doing so. Many customers are choosing to do data engineering work outside of Snowflake to cut costs. They are increasingly using open table formats such as Iceberg, which Snowflake is integrating. They want different data types including transaction data and Snowflake’s Unistore continues to be aspirational.
Moreover, many customers we’ve talked to want to keep their Gen AI activities on-premises and bring AI to their sovereign data. They may not be willing to move it into the Data Cloud. But Snowflake and Blue Yonder appear to have an answer if you’re open to moving data into Snowflake. The business case in this complex example may very well justify such a move.
Once your data house is in order, you can integrate the data, make different data elements coherent, i. e., harmonize the data. And we’re taking a system view here. Oftentimes, managers are going to maybe do a great job of addressing a bottleneck or optimizing their piece of the puzzle. And, for example, they might dramatically improve their output, only to overwhelm some other part of the systems and bring the whole thing to its knees, essentially just moving the deck chairs around, or maybe worse.
And finally, with gen AI, every user interface surface is going to be enhanced with an agent technology. It’s going to reduce cycle times over time, dramatically simplify supply chain management. And in this example, yes, supply chain, but also all enterprise applications. And a very powerful takeaway from today is: The answer to business resilience is not excess inventory, it’s better software. It’s the intelligence data platform.
Salil’s final thoughts:
I would like to say, with the availability of technology now on our hands, whether it be ML/AI, whether it be the infinite compute, whether it be the platform data cloud, whether it be now generative AI, this whole notion of the end to end, the whole notion of the connected supply chain, the ability to have that visibility, ability to orchestrate across the entire spectrum… companies will now be able to start measuring, at a very different level, the objectives and the metrics relative to what they have done in the past. No longer are you going to talk about cost per case at a warehouse.
You’re going to talk about cost to serve at a customer level. So it’s going to be very different moving forward with these technologies at play. With the kind of superpowers that these systems are going to provide, the software is going to provide, the essential supply chain operator role is going to change drastically. Our supply chain operators will become superheroes. The notion of, you touched upon this, around sustainability and ESG. There is not going to be just metrics and measures that are reports down in the dungeons, but it is really going to be part of the optimization solve, and get better answers to this. So companies will become that much more competitive because of the fact that we have these supply chain applications in place, and that’s the excitement of pivoting to this new transformation.
Duncan’s final comments and takeaways:
The way to solve resiliency is not inventory, it’s software. And that’s exactly what we’ve built, next- generation solutions that allow companies to be more agile, aggressively responsive, and fully optimized, and all built in what we think is the next- generation enterprise software stack with intelligent data apps. And that’s what we’ve built. So we’re living in a moment in time where supply chains have never been more uncertain, and transformation is required, just like we just lived through the last 20 years of digital transformation, which was sort of consumer-driven, and then we’re seeing the same necessity now around supply chains. So thank you very much for having us on. As always, really enjoyed the chat. You guys asked very insightful questions.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





