







 NEWS
NEWS
NEWS
NEWS
NEWS
In the world of Big Data, 2015 is rapidly shaping up as the year of Spark. The Apache analytics engine has captured the industry’s imagination and prompted some people to predict that Spark will be a bigger deal than Hadoop, which was yesterday’s shiny bauble. IBM closed out the first half of the year with an exclamation point, announcing its intention last month to embed Spark in all of its analytics and ecommerce platforms, commit more than 3,500 researchers and developers to Spark-related projects and train more than one million data scientists and engineers to use it.
Why is Spark such a big deal, and is it really a competitor to Hadoop? We asked Wikibon analyst George Gilbert for his no-nonsense view. His bottom line: Hadoop isn’t going anywhere soon, but Spark has unquestionably stolen some of the the momentum. “Eventually, you might be able to do everything on Spark that you now do with the Hadoop ecosystem. However, the mainstream usage scenarios generally involve a combination of Spark and Hadoop, such as YARN and HDFS,” Gilbert said. But could Spark eventually put Hadoop out of business? “Potentially.”
Here’s the background you should know. Hadoop is a batch processing framework that provides a set data processing engines for analytic workloads. It’s not a product so much as an ecosystem that supports a variety of processing engines – that are tuned to different tasks, such as querying data or calculating statistical probability. One of the great things about Hadoop is that the data processing engines can cooperate with each other to perform very sophisticated analysis. All of this sophistication comes with considerable complexity, however, since each engine has to be managed separately.
Hadoop’s original data processing engine is MapReduce, which is often criticized for being slow and complex. Spark was developed as a replacement for MapReduce, “and they did such an amazing job that many parts of the ecosystem that once relied on MapReduce are moving to Spark now,” Gilbert said.
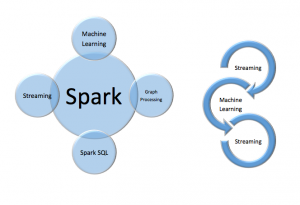 Spark is a unified in-memory analytics engine that runs on top of Hadoop’s HDFS and YARN and other platforms. Like Hadoop, Spark can process multiple analytic workloads but rather than employ discrete engines, it uses multiple personalities on top of one engine. More important, they’re integrated with each other. In contrast to Hadoop, which must saves the output of each process before another can start working on it, Spark can do everything in memory. What’s more, personalities can swap data back and forth fluidly. That enables capabilities like real-time analytics involving streaming data, SQL queries, and machine learning to work on the same data, which is all the rage right now.
Spark is a unified in-memory analytics engine that runs on top of Hadoop’s HDFS and YARN and other platforms. Like Hadoop, Spark can process multiple analytic workloads but rather than employ discrete engines, it uses multiple personalities on top of one engine. More important, they’re integrated with each other. In contrast to Hadoop, which must saves the output of each process before another can start working on it, Spark can do everything in memory. What’s more, personalities can swap data back and forth fluidly. That enables capabilities like real-time analytics involving streaming data, SQL queries, and machine learning to work on the same data, which is all the rage right now.
Clickstream analysis is one example of real-time analytics. Ad-serving engines need to analyze user clickstream data very quickly to understand which ads will deliver maximum results and therefore profits. Using Hadoop, this process is fairly slow because clickstream data must be first saved to disk and then loaded into an analytics engine. In Spark, data collection, queries and analysis happen at almost the same time. That enables much faster decisions to be made.
So aren’t Spark and Hadoop two different animals? Doesn’t Spark require a Hadoop engine? Not really. Spark runs just fine on Hadoop’s HDFS file system, but it can also grab data from Cassandra NoSQL, HBase, and Amazon S3 sources, among others. It can also work on other, non-YARN cluster resource managers such as Mesosphere. When combined with the shortcomings of MapReduce, that means that Spark has effectively turned the tables: Hadoop may need Spark more than Spark necessarily needs Hadoop.
That’s why these two technologies are being billed as a battle of the Big Data titans, and it’s happening just as recent research has painted a somewhat disappointing view of Hadoop adoption.
Spark isn’t the Holy Grail, of course. It has performance limitations of its own due to its reliance upon the Java execution platform. The Spark community is working on a compiled version that will be faster, but delivery dates are unclear. For now, compiled engines like Cloudera, Inc.’s Impala deliver better performance, but at a cost.
One thing is for sure: Spark has changed the conversation “An enterprise can’t make a commitment to a Hadoop infrastructure without at least having Spark as a complement,” Gilbert said. “If they can use Spark as a grand unified analytics operating system, they might approach an analytics strategy quite differently than they would have a year ago.”
For now, the much-hyped competition between Spark and Hadoop is more theatrics than substance. But that could change.
THANK YOU





