













 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
When the data scientists at messaging software maker Synchronoss Technologies Inc. embarked upon a new project in 2014 to store, manage and extract insights from the massive amounts of data produced in their business, they thought they had found the answer to their prayers: red-hot software with the funny name of Hadoop.
Hadoop distributes and organizes data across an almost unlimited number of computers far more cheaply than can be done in traditional data centers. As a result, it finally promised to enable huge data sets — “big data,” as it came to be called — to produce the kind of insights about everything from their customers to their own operations that companies had always hoped they would. “We could just put everything in there,” said Suren Nathan, Synchronoss’ vice president of engineering, digital transformation and analytics.
And so they did. But it all quickly turned into what Nathan termed a “nightmare.” Since Hadoop had no key services for discovery, searches and the like, “it became a dumping ground for data.” Sure, there were tools to bring order out of that chaos. But in the free-for-all that was the Hadoop ecosystem at the time, it was up to Synchronoss’ engineers to figure out how to put a dozen or more open-source software components together — and that expertise was hard to come by. “Jungle knowledge,” Nathan sighed.
Synchronoss’ experience is all too common. As recently as last fall, research firm Gartner Inc. estimated that a stunning 85 percent of enterprise big data projects failed. As a mainstream business tool, at least, it appeared that big data was destined to join Silicon Valley’s hall of shame.
Does that mean the whole notion of big data has been a failure? Not even close. It turns out that data is simply too important an asset to ignore. Indeed, it’s seen by most companies as their most important asset of all. That’s why the failures — and the stubborn, fitful struggles to turn them around — actually gave birth to entirely new products and services, from ready-to-use data warehouses to data-as-a-service to machine learning in the cloud. They’re delivering value to enterprise customers without the headaches of integration and management.
As a result, far from drowning in its own complexity, big data — including the far-ranging set of tools and services to make use of it — has already changed the way companies relate to customers and spawned services that have transformed our daily lives. It’s also driving the digital transformation imperative that is turning entire industries from retail to media to software upside down. Most of all, it has laid the foundation for a revolution in artificial intelligence and machine learning that will redefine business and society in ways not seen since the Industrial Revolution.
Big data is thriving, even if the business looks very different from what the pioneers envisioned. It’s on the way to becoming a $200 billion industry by 2020, according to International Data Corp. Wikibon, the analyst group owned by SiliconANGLE Media, recently upped its estimate of the market’s worldwide growth (below) to 24.5 percent in 2017 thanks to a better set of tools and the support of public cloud computing providers such as Amazon Web Services Inc., Microsoft Corp. and Google Inc.

Synchronoss’ Suren Nathan (Photo: Twitter)
But big data is very much a work in progress, and what form the market will take remains uncertain. Software suppliers continue to struggle to figure out a sustainable business model in an open-source ecosystem, while cloud computing providers are quickly capturing an increasing share of enterprise business. There’s also a huge market emerging in prepackaged big-data services that business customers can buy by the drink instead of mixing their own. This rapidly maturing vendor ecosystem and emerging cloud-based options have made big data less of a do-it-yourself option, enabling users to focus more on applications than technology.
One thing’s for sure: Companies that don’t master big-data fundamentals will find themselves increasingly marginalized in the future. As SiliconANGLE’s BigData SV convenes this week along with the nearby Strata Data Conference in San Jose, California, SiliconANGLE sampled a variety of opinions from around the industry to get a sense of where big data is going. In short, it’s to the cloud, in the form of services, platforms and product integrations that will make the data an ever more integral part of doing business.
Mastering big data requires discipline and a shift in culture to think about data not just as an operational necessity but as a strategic asset, even if that asset doesn’t usually show up on the balance sheet. “The successful models come from businesses that have a clear target for what they’re trying to accomplish,” said Mike Tuchen, chief executive of data integration provider Talend SA. “They know the data they need to get, the analytics they want to run and where the value is coming from.”
Take Synchronoss: It eventually solved its data lake problems by putting a governance process in place that included a taxonomy, access controls, metadata and a limited set of data definitions. It also moved to MapR Technologies Inc.’s so-called converged data platform, which provides a set of integrated, supported data management tools. Synchronoss can now embed analytics in its cloud-based messaging products to deliver insights to its service-provider customers about how their services are used as well as to detect anomalies and predict failures. “When you have the tools to manage things, the rest takes care of itself,” Nathan said.
When Hadoop debuted in 2011, it was widely hailed as the Prometheus that would bring the fire of big data to the masses. With its roots in search engine technology, Hadoop could accommodate nearly any kind of information. Based on off-the-shelf hardware and a clustered architecture, it promised up to 90 percent lower cost and nearly infinite scalability. Best of all, it was free. Or so it seemed.
Organizations could move all kinds of data into a Hadoop store and then figure out interesting ways to combine them. The chief technology officer of Pentaho Corp. coined the term “data lake” to describe this large, loosely structured mishmash of information enabled by new information technology economics.
In Silicon Valley, Hadoop sparked a feeding frenzy of startup and venture capital activity, culminating in Intel Corp.’s massive $740 million investment in Cloudera Inc. in 2014. But on the ground, early adopters were having a different experience. “We realized Hadoop was nothing but a file system,” Nathan said. “The tools were there, but without the fundamental management layers, there was a closed set of people who could work with it.”
Hadoop was also widely misunderstood. Yes, the file system could accommodate nearly any kind of data, but without metadata, governance and purpose, it was nothing more than what skeptics came to call a data swamp. Some people thought Hadoop was too good to be true, and it turned out they were right.

PlaceIQ’s Steve Milton (Photo: PlaceIQ)
The new tools of big data required a change of perspective, since data was no longer predictable. “In the old relational days, you’d create a star schema and churn out reports for 25 years,” said Steve Milton, co-founder and chief technology officer of PlaceIQ Inc. “It isn’t that way anymore. Things change constantly.”
PlaceIQ processes 500,000 mobile device interactions per second and delivers information about what users are doing up to 6 billion times per day for merchants, advertisers and brands that want to understand how location relates to customer behavior. It was an early adopter of open-source big-data technology and has the bruises and prove it.
“You can’t assume that the data in your lake today is going to be the same as the data you put in three months from now,” Milton said. PlaceIQ had to smooth out and normalize petabytes’ worth of historical data for accurate time-based analysis. It also needed to perform consistency and quality checks for data streaming in from the field. Also, “every mobile phone could have a bug,” Milton said. “The multitudes of ways that error could be introduced into the system was huge.”
Commercial tools from Cloudera and Snowflake Computing Inc. – combined with lots of hard work — have helped PlaceIQ master the integration problem. But the task is never finished. “This has been a six-year path,” Milton said. “That’s how hard it is to build a data lake.”
Many organizations embarked upon big data projects without clear goals. Wikibon summed up the five most common causes of big data project failures, and it’s a damning list: immature technology, weak tools integration, costly infrastructure, poor collaboration and executive indifference to results.
By the time big data made its last appearance on Gartner Inc.’s Hype Cycle in 2014, it was sliding down the slope toward the “trough of disillusionment.” “The ‘big data’ term is losing favor in the industry,” analyst James Kobielus said in Wikibon’s recent report.
Nearly four years later, questions still linger about why big data failed to achieve its potential in the enterprise. “Big-data analytics has become a boardroom conversation, although too often the question being discussed is ‘Why aren’t we generating the expected returns?’” said Kobielus.
The failure of many early projects was less about technology than lack of understanding of how big data should be used, said Gene Leganza, a vice president and research director at Forrester Research Inc. “It’s not because big data didn’t deliver,” he said. “Most organizations were immature about data management and governance.”
But the struggles many enterprises had with early projects may overshadow the enormous changes that big data has already made in business and our lives — many we’re barely even aware of. Consider Waze, Google’s interactive navigation mobile app used by an estimated 65 million people every month. Waze continuously polls millions of devices for location, speed and road conditions in near-real-time, analyzes the data and feeds it back to drivers in time to make split-second decisions. Or consider Facebook Inc., which serves millions of concurrent users with a customized experience based upon the interactions of others, with nearly instantaneous updates.
Then there’s smartphone advertising, which brings together big data, mobility and cloud computing to deliver ads in a complex back-end process that combines personalization, location and context-relevance with a sub-second delivery. “There’s all this incredible technology in the background that causes just a momentary delay,” said Leganza.
Companies that don’t have the resources or interest to build their own data lakes can pay for preprocessed streams from companies such as PlaceIQ or Zeta Interactive Corp., which compiles data on more than 350 million people from a network of third-party providers and sells those profiles to marketers.
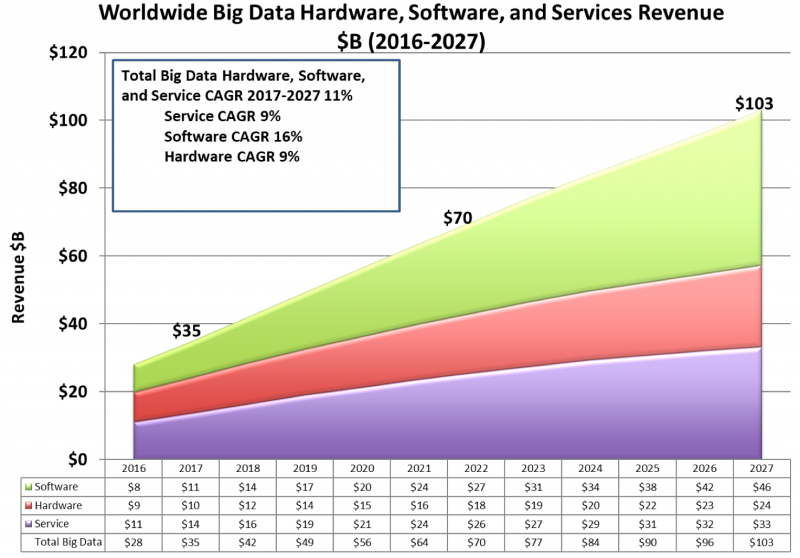
Worldwide big data hardware, software, and services revenue 2016-2027, in billions of dollars (Source: Wikibon)
These types of applications would have been unimaginable just a few years ago. Now, the economics of open-source big-data platforms and cloud infrastructure has spawned new industries based upon delivering massive amounts of data for specialized purposes.
Behind the network firewall, organizations are deploying projects that are perhaps less glamorous than the commercial services but no less valuable. For example, machine learning is being applied to IT operations management to sift through massive amounts of log data and identify the causes of performance bottlenecks or where the next slowdowns are likely to occur.
It’s also being integrated into intrusion detection and prevention software to identify aberrant behavior and isolate intruders before they can do much damage. Big-data-based AI is also set to revolutionize application development by enabling programmers to realize the long-sought goal of writing declarative business logic that is then translated into the appropriate code by the machine.
It all adds up to an acceleration in the pace and precision of business. Marketers can craft messages with unprecedented targeting. Sales representatives have a far more complete picture of their prospects’ businesses and needs before they pick up the phone. Logistics teams can manage their fleets using the same kind of technology that enables Uber Technologies Inc. – another beneficiary of big data – to coordinate the paths of a million private chauffeurs around the globe without human operators.
Doug Laney, vice president and distinguished analyst with Gartner’s Chief Data Officer Research team, has collected more than 500 examples of interesting enterprise applications of big data. “It’s clear to me that the conversation among our clients has shifted from ‘What is big data?’ to ‘How do we do big data?’ to ‘What do we do with all of this big data?’” he said. “They’re much more strategic.”
All this wasn’t quite what most people had predicted. A few years ago, conventional wisdom held that the new breed of big-data tools would proceed along the same adoption curve as data warehouses. Those are the traditional repositories for more structured data, and they were largely confined to corporate data centers.
The cloud changed all that. Indeed, cloud infrastructure providers such as AWS, Microsoft and Google are emerging as the odds-on favorites to get the lion’s share of enterprise big data projects in the future. “Anybody that doesn’t have the skills or desire to manage their own data lake is moving to the cloud,” said David Mariani, CEO of AtScale Inc., a company that integrates business intelligence tools with multiple back-end data sources. “Faced with the alternative of having to learn all this stuff or just park it on [Google Cloud’s] BigQuery or [AWS’]Redshift, it’s just easier.”

AtScale’s David Mariani (Photo: SiliconANGLE)
Wikibon expects the big data industry to coalesce around the three largest public cloud infrastructure providers by 2020. “The cloud guys can stitch this stuff together like the individual companies can’t,” said Wikibon analyst George Gilbert.
Cloud companies are obliging by rapidly rolling out services to support nearly every kind of big data application. Among the announcements at Amazon’s re:Invent conference last fall were major enhancements to its Aurora relational cloud database, enterprise-friendly upgrades to its DynamoDB NoSQL database and a new offering based on graph database technology. Google is using its BigQuery data warehouse and Bigtable NoSQL store in multiple new offerings in artificial intelligence and machine learning, where it’s considered the cloud market leader.
“Data analytics is one of the main growth factors in our cloud business,” said William Vambenepe, group product manager for data processing and analytics at Google Cloud. Cloud vendors are focusing on taking the complexity out of big data deployments to turn services into utilities for business users. “We’re building it to be like the plumbing in your home,” he said.
Suppliers that started out by integrating big data components into ready-to-use packages have shifted their focus toward applications. MapR, which in 2014 described itself as the company that “delivers on the promise of Hadoop,” today doesn’t even mention Hadoop in its company description. The same goes for Cloudera. “Hadoop is still alive and well, but it’s not the next big thing like it used to be,” said MapR CEO John Schroeder.
These strategies better align with what customers want, according to Kobielus. “These applications have so many moving parts in a multi-vendor pipeline that customers are placing a premium on consistency and simplicity integrated out of the box,” he said. “The infrastructure equivalent of Steve Jobs’ ‘It just works’ is becoming more important.”
With the big infrastructure decisions now largely complete, big data is set to move in more interesting directions. Wikibon expects growth rate for big-data application infrastructure, analytics databases and application databases to slow sharply beginning in 2023. This will be accompanied by rapid acceleration in the growth rate for advanced analytical applications, machine learning and stream processing with the takeoff of the “internet of things,” the myriad devices from smartphones to fridges to industrial sensors.
Systems of record, or databases considered the authoritative source for an organization, defined the first 60 years of data processing. But not for much longer. Systems of intelligence will define the future. Powered by big data, systems of intelligence deliver lasting competitive differentiation by anticipating, influencing and optimizing customer experiences. Much of their value in the immediate future will come from machine learning, which enables computers to take a small set of instructions and learn by continuously combing through large data sets to find, predict and test new patterns.
Machine learning is already showing up in a variety of IT infrastructure components, ranging from operations management to intrusion detection. It’s also appearing in consumer-facing services. Microsoft used it to teach its Skype voice-over-IP engine to translate multiple languages in real time starting with just a small subset of word pairs. Thanks to machine learning, computers are already much better than humans at identifying faces, and smartphones can now recognize speech as well as people. Evolutions of the technology will help scan images to pick out cancerous cells, or known terrorists. “A lot of amazing things will come out of machine learning,” said Gartner’s Leganza.

Cloudera’s Mike Olson (Photo: SiliconANGLE)
Enterprises have quickly gotten on board, too. A survey of 500 chief information officers last fall by service management software provider ServiceNow Inc. found that 89 percent of CIOs are using or plan to use machine learning, and 70 percent believe computers make more accurate decisions than humans. “Five years ago, I would have never said machine learning would be at the level it is now,” said Mike Olson, chief strategy officer at Cloudera. Cloud computing providers, with their voluminous data pools, are well-equipped to lead the charge in this area.
Although machine learning will make big data even easier to use, the trend is already evident in the industry’s focus on self-service and automated data preparation. The task of cleansing and normalizing data continues to occupy a disproportionate share of time for data scientists, who are in short supply. Traditional data integration companies such as Informatica LLC and IBM Corp. are tackling this problem along with a host of newer firms that include Talend, Trifacta Inc., Jitterbit Inc. and HVR Software B.V. “Big data still needs to be simplified for regular users and developers; it’s way too complex,” said Wikibon’s Kobielus.
Indeed, the desire to make big data more accessible to the ordinary person is the next big job for the industry. The state of big-data deployments in most organizations today can be compared to the personal computer circa 1983 or the internet of 1995. The technology is unfamiliar and difficult to use and requires a large staff of technology experts to manage. Big data will increasingly become part of the woodwork over time, in the same way that PCs and networks eventually became as routine as paper clips. Gartner’s Laney said the goal is to make enterprise decisions self-driving in the same that automobiles will become autonomous over time. That will be another big-data triumph.
Software companies such as Tableau Inc. and Looker Data Sciences Inc. are focusing on the front end of the self-service agenda, along with the crop of traditional business intelligence vendors. Data integration companies are working on the back end to simplify the integration component, and companies such as AtScale and Arcadia Data Inc. and working up and down the stack. “Self-service and consumability remain hurdles for mass adoption,” said Kobielus.
Oddly enough, the need to make big data more usable in the enterprise is driving a new focus on making data more structured, standardized and consistent — precisely the characteristics of the Structured Query Language relational databases that big data stores were supposed to leave behind. Companies such as Snowflake Computing and products ranging from Microsoft’s Azure Data Warehouse to Google’s BigQuery have sprung up out of the need for organizations to leverage their traditional SQL data investments in a big-data context. Numerous open-source projects also deliver various degrees of SQL support.
AtScale’s Mariani calls this trend “data lake 2.0,” with cloud providers putting things such as catalogs on top of file systems that look a lot like Hadoop’s. When combined with serverless infrastructure in the cloud — that is, systems that cloud providers provision automatically without users having to touch the controls — people can apply their favorite reporting tools to semistructured data without going through the mess of loading everything into a data warehouse.
In the end, then, big data isn’t replacing the warehouse and other traditional data tools. It’s reinventing them — and changing the world in the process.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





