 CLOUD
CLOUD
CLOUD
CLOUD

CLOUD
The job of a site reliability engineer, also known as an SRE, is typically characterized as bringing engineering principles to infrastructure and operations problems, with a focus on creating reliable and scalable systems.
What most SRE job descriptions fail to add is that the job also requires an ability similar to that of a firefighter who must charge into a burning building and rapidly find the root cause of blaze.
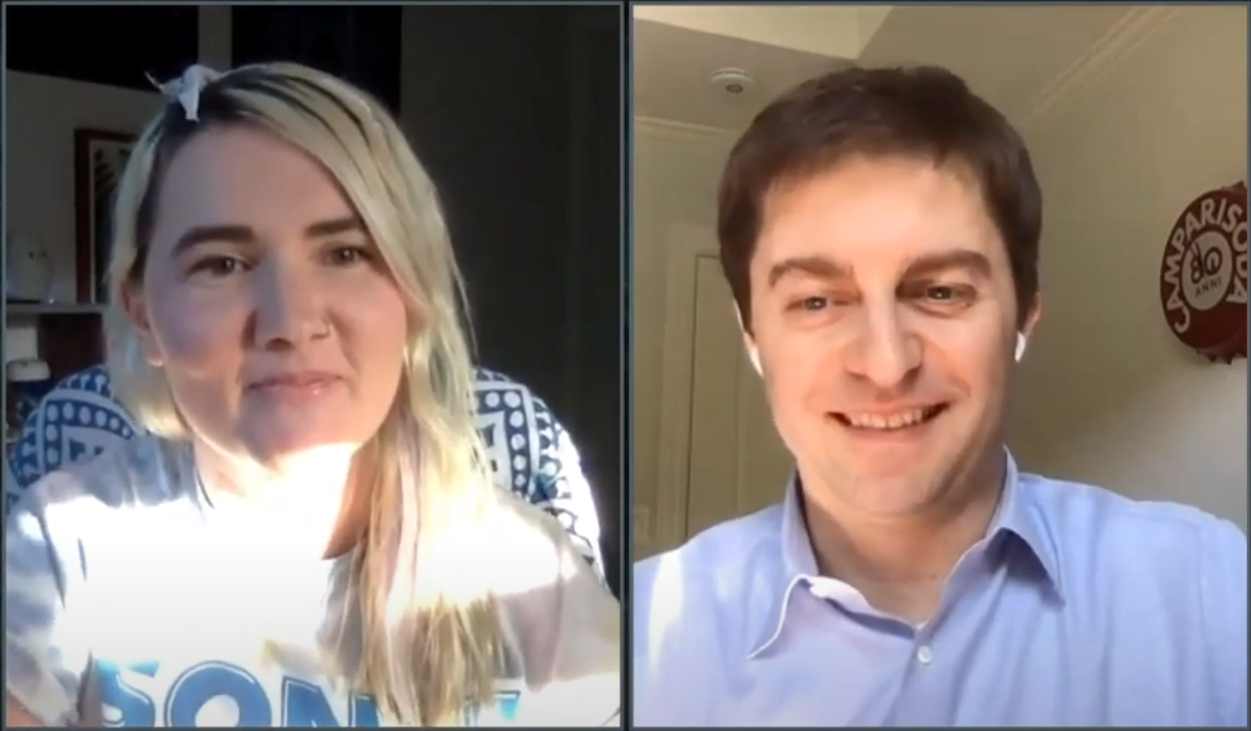
“With large-scale incidents, you really need to be able to act fast,” said Tammy Butow (pictured, left), principal site reliability engineer at Gremlin Inc. “If you detect an incident faster, then you’ve got a better chance of making the impact lower so you can contain the blast radius. If you have a fire in the saucepan in your kitchen and you put it out, that’s way better than waiting until your entire house is on fire.”
Butow spoke with John Furrier, host of theCUBE, SiliconANGLE Media’s mobile livestreaming studio. She was joined by Alberto Farronato (right), senior vice president of marketing at Gremlin, and they discussed the company’s approach toward protecting complex systems through testing and an upcoming free event.
Gremlin characterizes itself as the world’s first hosted chaos engineering service to build a more reliable internet by turning failure into resilience. The goal is to safely experiment on complex systems before they fail and cost enterprises millions in lost business.
“It’s not so much about creating chaos, but managing chaos that is built into our current system and exposing vulnerabilities before they create problems,” Farronato explained. “You need a fundamentally different approach to go and find where your weaknesses are before they happen.”
This practice can be especially helpful within large financial institutions, such as the National Australia Bank, where Butow worked for six years prior to joining Gremlin.
“We would do large-scale disaster recovery,” Butow said. “That’s where you would failover an entire data center to a secret data center in an unknown location. The reason is because you’re checking to make sure that everything operates OK in a nuclear blast, and you had to do that practice every quarter.”
The coronavirus pandemic was an opportunity for Gremlin to create a new conference – a free virtual event called Failover Conf, scheduled now for April 21. This is in addition to the annual Chaos conference.
“We quickly pivoted as a company and created a new online event to give everyone in the community the opportunity,” Farronato said. “This is a conference for anybody who is interested in resiliency if you want to know from the best on how to build business continuity across systems, people and processes.”
Here’s the complete video interview, one of many CUBE Conversations from SiliconANGLE and theCUBE:
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.