















 AI
AI
AI
AI
AI
Facebook Inc.’s artificial intelligence team today revealed a way to build speech recognition systems without using any transcribed audio data to train them.
Speech recognition is one of the most common types of AI, widely used in lots of popular applications. Amazon Alexa and Google Assistant, for example, use speech recognition to understand their user’s commands. And transcription tools such as the automatically generated captions on YouTube also rely on it.
But not everyone gets to benefit from speech recognition. The technology has been implemented only for speakers of some of the world’s most common languages, such as English, Arabic, Chinese, Spanish, French and so on. But for speakers of less common languages, such as Basque, Swahili or Tagalog, speech recognition systems are much more limited.
The reason for this is that such systems need to be trained on large amounts of audio that has already been transcribed. Massive amounts of that data are available in English and other common languages, but that isn’t true for many of the less widely spoken languages in the world.
It’s for speakers of these languages that “wav2vec Unsupervised” was created. Wav2vec-U, as Facebook’s researchers call it, is a method that can be used to create high-quality speech recognition models without any labeled training data.
“Wav2vec-U is the result of years of Facebook AI’s work in speech recognition, self-supervised learning, and unsupervised machine translation,” Facebook AI researchers Alexei Baevski, Wei-Ning Hsu and Michael Auli wrote in a blog post today. “It is an important step toward building machines that can solve a wide range of tasks just by learning from their observations.”
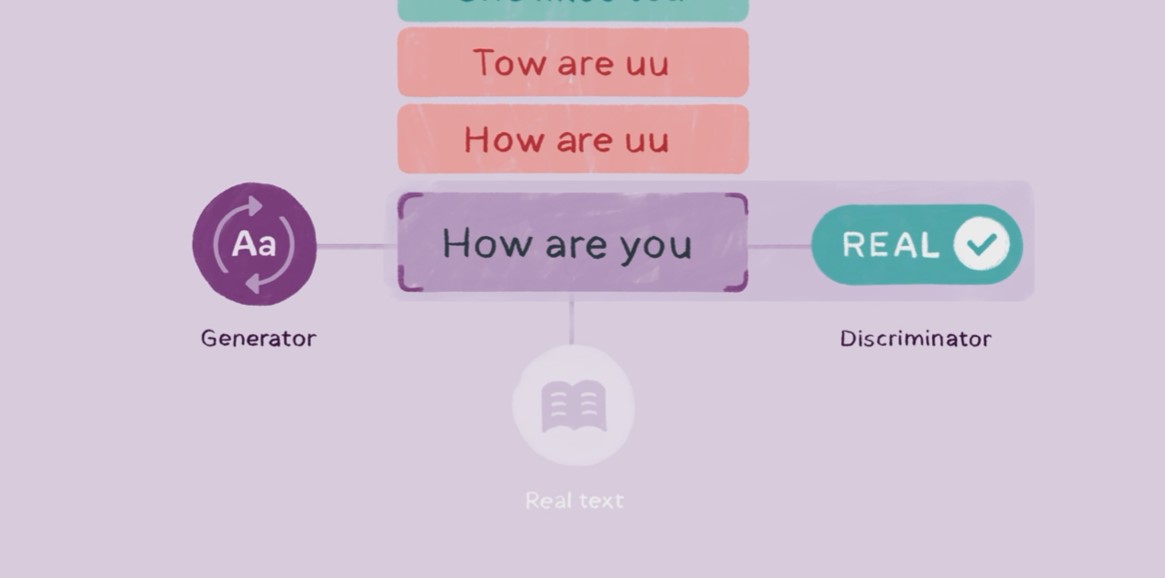
Wav2vec-U still needs training data, of course, but it can learn using recorded speech audio and unpaired text, which means there’s no need for less common audio transcriptions. It begins by learning the structure of the target language’s speech from the unlabeled audio.
It then uses what’s called a “generative adversarial network” consisting of a “generator” and a “discriminator” to teach the model to associate texts from the target language with the unlabeled audio that is fed into it. Initially, the transcriptions created by the generator will be pretty poor, but the discriminator provides feedback that enables the model to become more accurate over time.
The results of Facebook’s experiments show that models trained using wav2vec-U eventually become extremely accurate. When the first models were evaluated on the TIMIT benchmark, it was found to reduce error rates by 63% compared to other unsupervised learning methods.
Facebook’s researchers also compared wav2vec-U’s performance against supervised AI models that were trained the traditional way. Using the Librispeech benchmark, it was found that wav2vec-U was just as accurate as what were considered state-of-the-art speech recognition models just a couple of years ago.
Facebook said wav-2vec-U is an important development because it believes speech recognition shouldn’t only be of use to people that are fluent in the world’s most widely spoken languages. It wants everyone to be able to benefit.
“Reducing our dependence on annotated data is an important part of expanding access to these tools,” the researchers said. “We hope this will lead to highly effective speech recognition technology for many more languages and dialects around the world.”
Wav-2vec-U also brings us closer to building AI models that can learn in a much more human way, the researchers explained.
“More generally, people learn many speech-related skills just by listening to others around them,” they wrote. “This suggests that there is a better way to train speech recognition models, one that does not require large amounts of labeled data.”
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





