















 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
We believe the future of intelligent data apps will enable virtually all organizations to operate a platform that orchestrates an ecosystem similar to that of Amazon.com Inc.
By this we mean dynamically connecting and digitally representing an enterprise’s operations including its customers, partners, suppliers and even competitors. This vision includes the ability to rationalize top-down plans with bottom-up activities across the many dimensions of a business – that is, demand, product availability, production capacity, geographies and the like. Unlike today’s data platforms, which generally are based on historical systems of truth, we envision a prescriptive model of a business’ operations enabled by an emerging layer that unifies the intelligence trapped within today’s application silos.
In this Breaking Analysis, we explore in depth the semantic layer we’ve been discussing since early last year. To do so, we welcome Molham Aref, chief executive of RelationalAI.
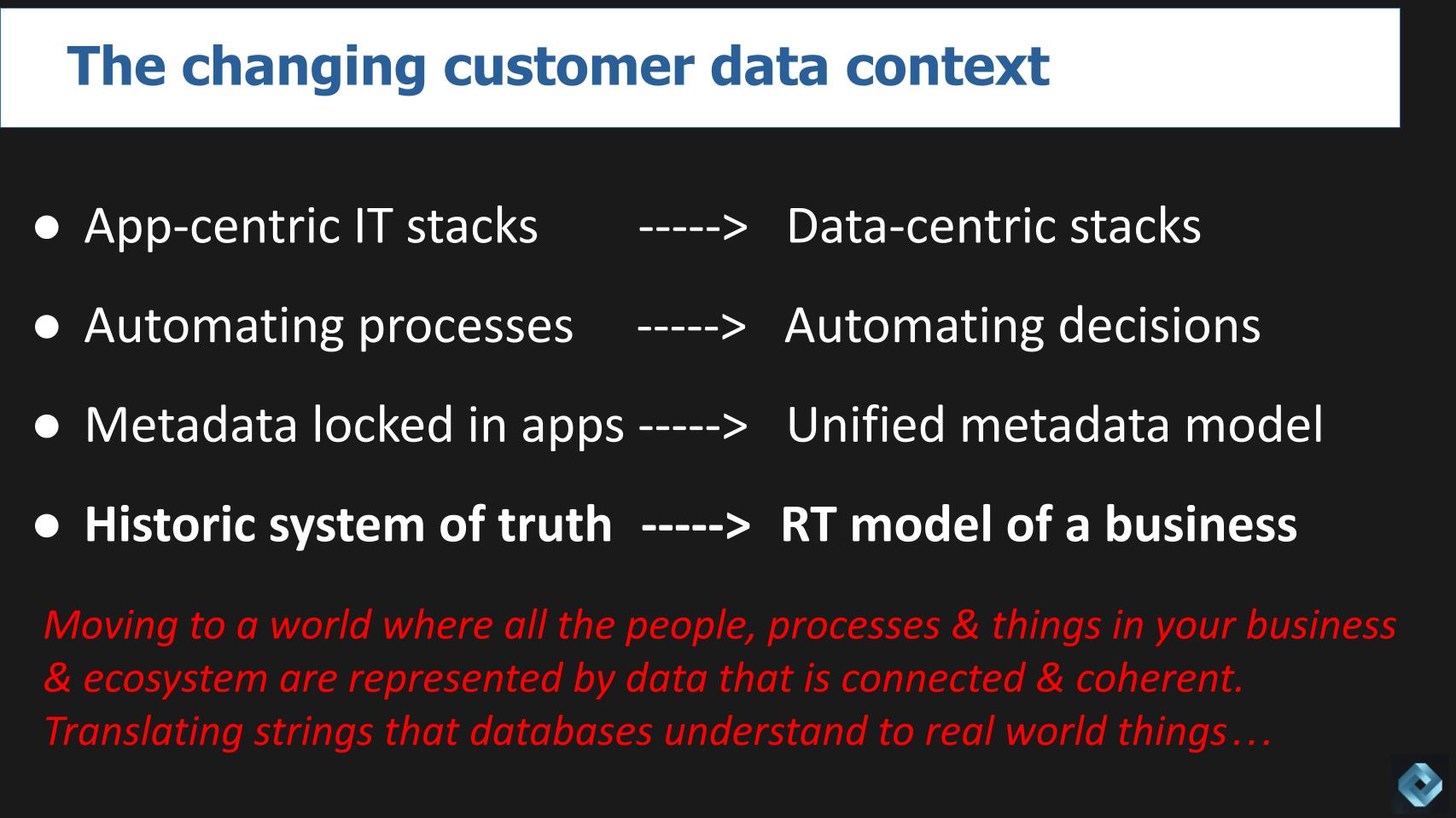
In the above graphic we attempt to depict some of the dimensions of the shifts taking place in customer environments, including:
To get us where we are today, we had to separate compute from storage to take advantage of cloud scale. We believe a new technology layer is needed to capture all the intelligence that has been locked inside of application silos for years. Our research indicates that by doing so, organizations can coherently work with that shared data across the enterprise, and we use Amazon’s retail business as an example of the desired outcome.
This capability to share data coherently across the enterprise is enabled by what the industry refers to as the semantic layer.
We asked Aref to explain his view of what exactly is a semantic layer, and how is it broader than the semantic layers that define metrics and dimensions for BI tools from firms such as dbt Labs Inc., AtScale Inc., LookML from Google LLC’s Looker, and the like?
Aref highlights the evolution of data management and the emergence of semantic layers in modern data stacks. As well, Aref discusses the challenges and solutions associated with integrating disparate data sources and the future direction of semantic technologies.
Aref emphasizes the critical role of semantic layers in modern data management, outlining the transition from fragmented data systems to unified, intelligent platforms. He underscores the importance of semantic layers in bridging the gap between disparate data sources and application logic, paving the way for advanced analytics with predictive and prescriptive modeling.
The future of semantic layers lies in their ability to evolve from mere descriptive analytics to incorporating intelligent semantics for predictive and prescriptive insights, thereby transforming data management into a more dynamic and foresighted field.
We asked Aref to explain the technology that needs to be created to unify our forward-looking vision – that is, enabling the ability to describe prescriptively all the activities for all the entities in a business.
Aref delves deeper into the intricacies of semantic layers, particularly focusing on the need for new technologies to encapsulate intelligent semantics and the distinction between code-based and model-based semantic capture.
Aref’s vision for the future of semantic layers is centered around a relational knowledge graph, which he sees as crucial for integrating more complex and intelligent semantics. This approach promises to overcome the limitations of current semantic technologies, fostering a more versatile and insightful data management ecosystem.
As we’ve discussed in previous Breaking Analysis episodes, knowledge graphs allow for expressiveness of data semantics but are cumbersome to query. Enabling the simplicity of SQL’s declarative queries for knowledge graphs will broaden their appeal in our view and open more use cases beyond today’s more narrow applications, such as cybersecurity.
The key to unlocking the full potential of semantic layers lies in the shift from traditional code-based semantics to relational knowledge graphs, enabling a vast array of analytical capabilities and ushering in a new era of intelligent data management.
Data platforms today get us only part way to our vision of embedded and accessible intelligence. Third party tools still introduce much fragmentation within each platform.
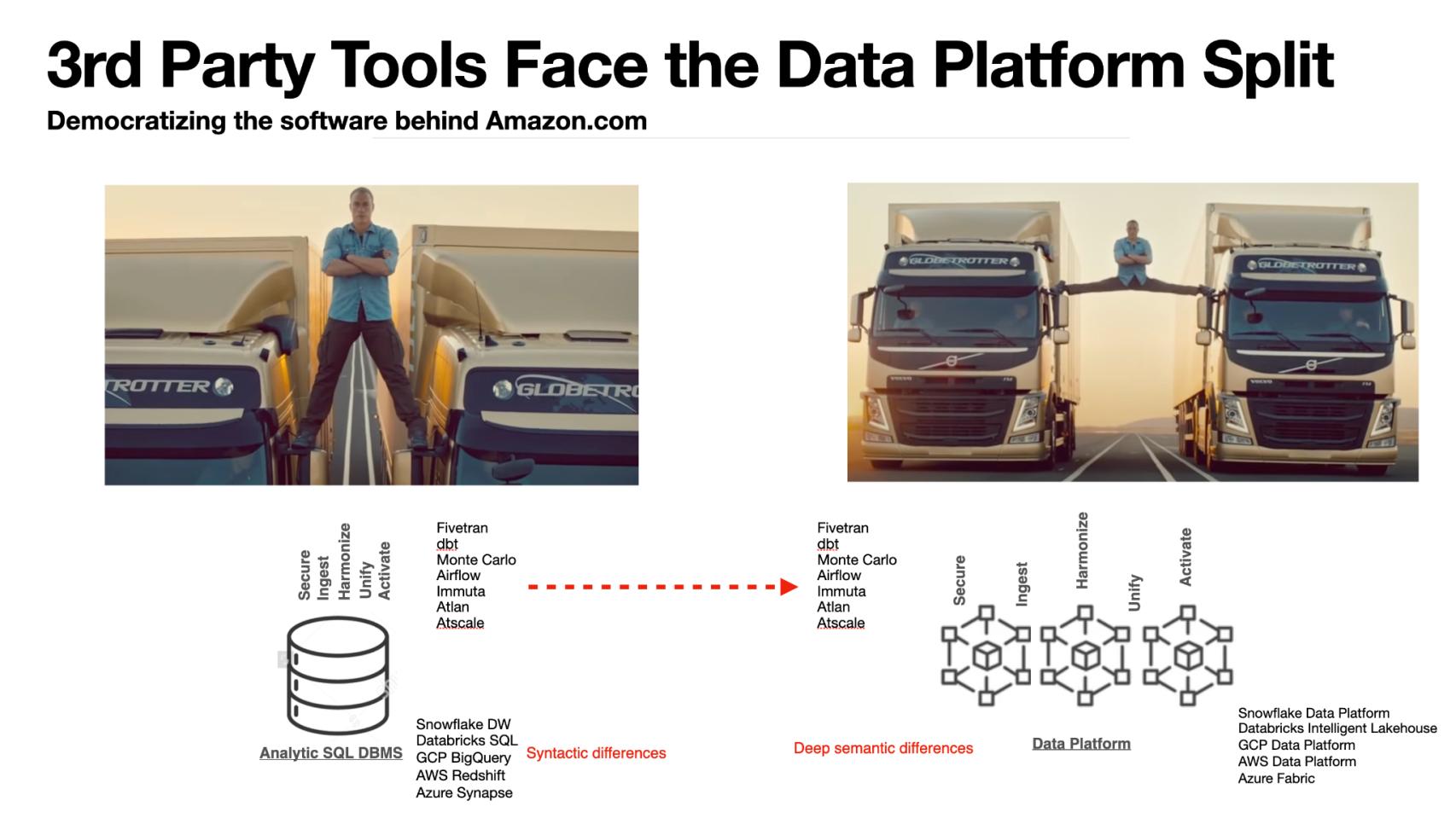
This dramatic graphic above shows Jean-Claude Van Damme straddling two 18-wheelers. The trucks represent today’s data platforms, which are mostly SQL DBMS-based. The picture on the left side implies that data platforms without rich semantics are pretty easy to straddle. However, as the platforms incorporate more of the application semantics, it becomes much harder to straddle them, represented on the right side of the graphic.
Thinking about the major modern data platforms today, we see Databricks Inc. with Unity starting to add semantics to its platform. Snowflake Inc. is likely going to follow suit by building its own extended metadata catalog. Amazon Web Services Inc.’s DataZone perhaps gives us clues as to its direction. Google’s Dataplex appears to be going down this path. Microsoft Corp.’s Fabric and the Power platform are the likely path for that company. Oracle Corp. will try to attack this from its very DBMS-centric point of view – we’ll see how this all plays out, but these are the clues we’re watching. VAST Data Inc. has gone as far as dissolving much of the distinction between data and metadata.
Today we have a collection of bespoke tools spanning governance, security, metrics, data quality, observability and transformation that can be cobbled together.
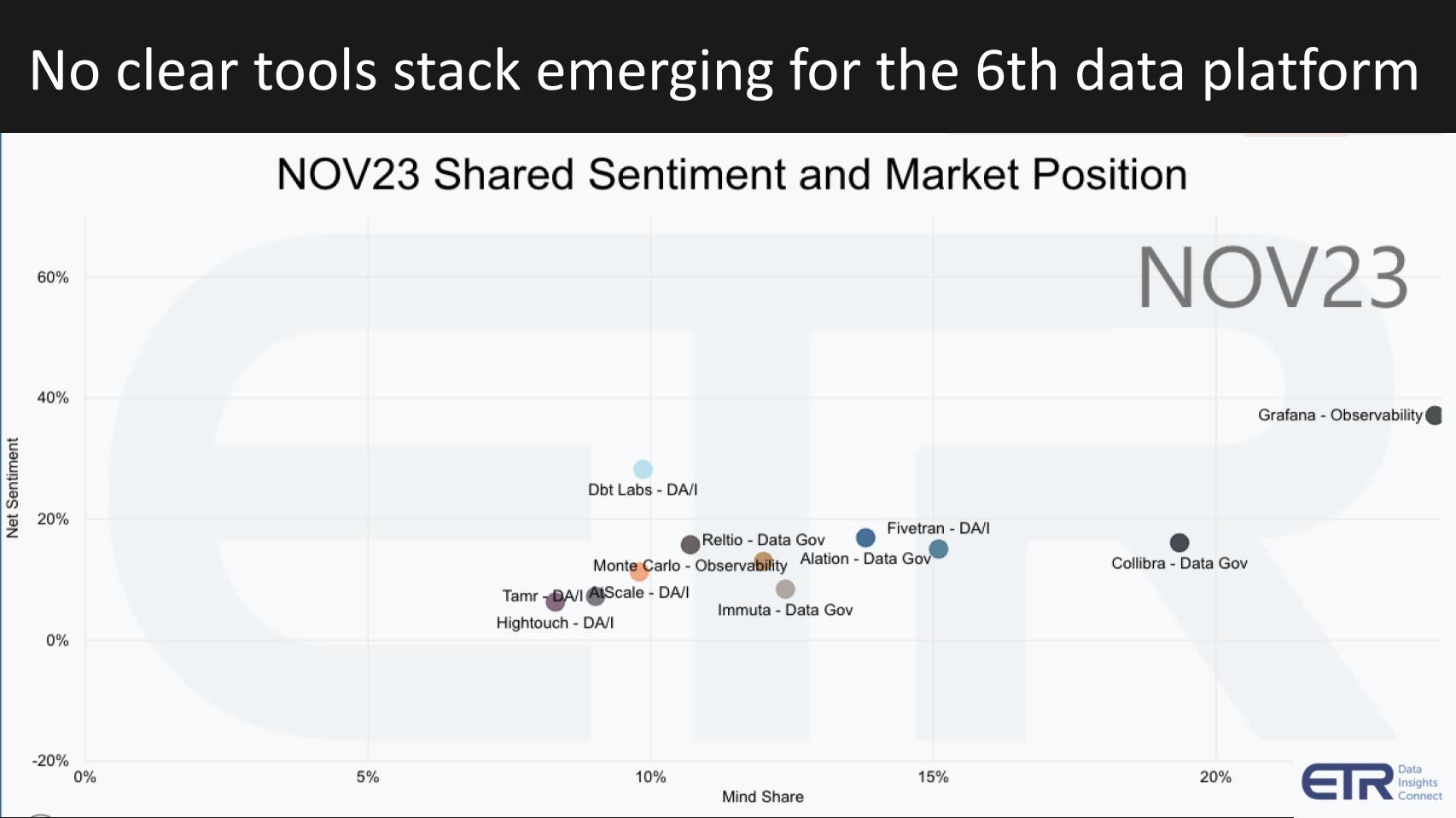
The above graphic is from Enterprise Technology Research’s Emerging Technology Survey. It’s a survey of more than 1,500 information technology decision-makers focused on which emerging tech platforms they’re using. This survey captures only nonpublic emerging companies.
The graphic shows selectively some of the tooling that is representative of the supporting data ecosystem and gets us partway to our vision of the future. The Y axis shows Net Sentiment, which is a measure of intent to engage. The X axis is Mindshare, which represents how well-known a company is to these customers.
Grafana stands out a bit. You see dbt and Fivetran Inc. are prominent, as is Collibra NV. But there are many choices that organizations have requiring them to stitch together different elements of the stack. There doesn’t appear to be a LAMP stack or an ELK stack equivalent.
The Salesforce Inc. Data Cloud and Palantir Inc. platforms are somewhat instructive with respect to the future. Earlier this month, theCUBE Research talked to the executive vice president of the Salesforce Data Coud. It’s uniquely up-leveling today’s data platforms by creating a metadata-driven set of semantics that also borrows the application semantics from the Salesforce operational apps. The relevance of this is that setting up a pipeline to ingest, transform and unify all the data becomes a configuration problem, not a code problem.
Palantir takes this somewhat further because it can model entities that represent the rest of the business.
But these are still both walled gardens.
We want to understand from Aref: For customers that are fully invested in the prominent data platforms, could Relational AI become a platform that hosts, simplifies, enhances and even unifies this cobbling of tools that is an attempt to add coherent semantics? And if so, how does the company think about solving this problem?
Aref elaborates on the approach of his company, emphasizing the principle of meeting customers’ existing infrastructures and needs, particularly focusing on integrating with data clouds such as Snowflake and supporting advanced analytics capabilities.
Aref puts forth a vision of seamlessly integrating advanced data analytics into existing data ecosystems. He advocates for a unified approach to semantic layers, focusing on relational paradigms and enterprise-specific models that enhance the value and efficiency of data management across various platforms.
In the evolving landscape of data management, the key to success lies in embracing a unified, enterprise-centric model, seamlessly integrating with existing data ecosystems and championing the relational paradigm for enhanced efficiency and value.
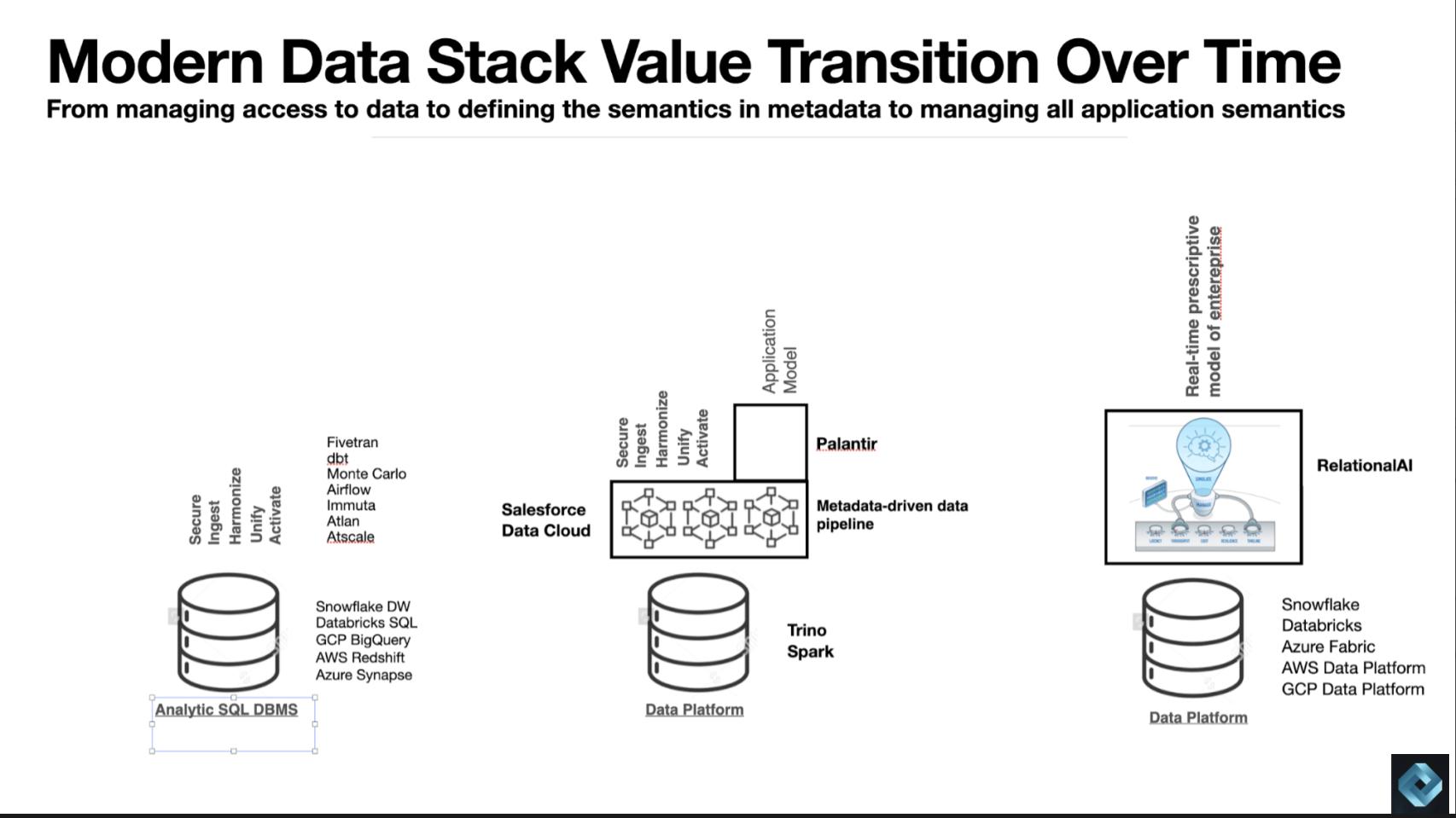
The idea of the above graphic is the foundational value has been in the analytic DBMS. We’re now layering additional value on metadata-based tooling (e.g. Salesforce Data Cloud or Palantir). The third stage is integrating all the intelligence that was trapped in application silos. Not just the application logic but also the analytics that enables a self-driving, continuous learning model of a business.
Clearly Aref sees RelationalAI as a complement and not a competitor to platforms such as Snowflake, a key partner. Although we are aligned with his vision, we found his answer to be diplomatic and wanted to push a bit on why he feels this is complementary and not disruptive.
His answer focuses on the complexity of building large-scale data systems such as Snowflake and Google’s BigQuery, but emphasized the importance of technological independence in semantic layers and drawing an analogy with Nvidia Corp.’s role relative to the central processing units. We found this both powerful and perhaps a validation of the nature of our question, as Nvidia is most definitely disruptive.
Regardless, here’s a summary of how Aref views this issue:
Aref underscores the necessity for semantic layers to remain technologically independent, advocating for a coprocessor approach akin to Nvidia’s relationship with CPU manufacturers. This strategy aims to enrich data clouds, transforming them into versatile platforms for a wide range of applications.
The future of data management hinges on the creation of technologically independent semantic layers, much like Nvidia’s role in the CPU industry, paving the way for versatile, coprocessor-enhanced data clouds that cater to the diverse and evolving needs of enterprises.
We’ve had decades of challenges building top-down enterprise models. Custom-built enterprise data models gave us packaged apps such as SAP, Oracle, NetSuite and Salesforce. Enterprise data warehouses bred data marts. Even with today’s BI, it has been challenging to get widely adopted shared semantics. Organizations have these bottom-up metrics (for example, bookings, billings and revenue). And there are top-down dimensions such as the organizational hierarchy. Rationalizing all this complexity has created markets for AtScale, dbt and others.
We asked Aref for his thoughts on the role of large language models in addressing these challenges.
His response explores the intersection of LLMs and knowledge graphs in the context of building semantic layers. He elaborates on the synergy between these technologies in simplifying and enhancing data management and semantic understanding within enterprises.
Aref underscores the transformative role of LLMs and knowledge graphs in revolutionizing semantic layers. He envisions a streamlined approach where complex data ecosystems are distilled into a few hundred core concepts, significantly simplifying data management and analysis for enterprises.
The fusion of large language models and knowledge graphs heralds a new era in semantic layer development, transforming the labyrinth of enterprise data into a navigable landscape of a few hundred key concepts, redefining efficiency and clarity in business modeling.
One of the goals in theCUBE Research is trying to understand the shifting value flow. In other words, where historically the center of gravity has been the DBMS (for example, Oracle and Snowflake), will the metadata and intelligence that defines the business entities becoming increasingly valuable, and how will that impact architectures, customer choice and vendor competition? We see early examples of the Salesforce Data Cloud and Palantir attempting to provide a model of the business with varying levels of intelligence. We see this future state as increasingly compelling for organizations.
Blue Yonder is another example where the company is reimagining supply chain and logistics ecosystems, rebuilding its applications on top of RelationalAI on top of Snowflake. We see three evolutionary stages becoming more clear — that is, moving from a world that is DBMS-centric to metadata-centric to an intelligent model of the business.
We want to understand how Aref sees this evolution playing out and we used Blue Yonder and the very complex supply chain and logistics example as a guide. Blue Yonder is a company run by Duncan Angove (former Oracle, Infor and others) with the legacy assets of firms such as Manugistics, JDA Software Group Inc., i2 and others that they’re reimagining in an AI-powered world.
Aref discusses the strategic shift of companies like Blue Yonder toward data-centric platforms like Snowflake and the transformative impact of translating traditional code-based business logic into knowledge graph-based systems.
Aref emphasizes the paradigm shift from application-centric to data-centric approaches in enterprise software, illustrating how companies such as Blue Yonder are pioneering this transition. He highlights the significant benefits of adopting knowledge graph-based systems, in terms of both operational efficiency and strategic alignment with current industry trends.
The transformation from code-based to knowledge graph-based semantics in enterprise applications is not just a technological shift; it’s a strategic imperative that significantly reduces complexity and cost, marking a new era of data-centric efficiency and intelligence in business operations.
We ask Aref to elaborate on the following premise. In the past we’ve had separate stacks for diagnostic analytics as well as those supporting predictive, prescriptive, planning, simulation and optimization efforts. We wanted to understand what customers can do when all of those stacks are integrated and that becomes one coherent model. We asked again about the Blue Yonder example for some use cases and impacts.
We asked Aref to react to our Amazon.com example where its operations are a closed learning loop, elaborating on the concept of a digital twin and the possibility of creating self-driving businesses through advanced semantic technologies.
Aref envisions a future where businesses operate like self-driving entities, continuously learning and optimizing operations through the use of digital twins and unified semantic layers. This approach promises to transform how businesses allocate resources and make decisions, moving away from the inefficiencies of siloed systems.
The concept of self-driving businesses, powered by digital twins and advanced semantic technologies, marks a revolutionary shift in resource allocation and decision-making, transcending the limitations of traditional, siloed business models.
Many folks, including us at theCUBE Research, are excited about RAG. We’ve built our own RAG with theCUBE AI and want to understand what role RAG plays in creating this coherent metadata-based model. Will it be a contributor, is it a stepping stone or will RAG disappear?
Aref sees the RAG technique as a crucial method for enhancing language models by integrating them with deterministic, symbolic and data assets.
Aref emphasizes the significant role of RAG in advancing language models, suggesting the value of relational knowledge graphs in teaching models about complex business concepts and relationships. He envisions a future where the integration of RAG with traditional AI and data via relational knowledge graph technologies leads to more robust and intelligent business systems.
The integration of retrieval-augmented generation with language models is akin to giving them a library and tools such as a calculator, vastly expanding their understanding and capabilities in interpreting and navigating the complex world of business data and relationships.
We’ve been talking about the future. So let’s explore more deeply what that looks like — specifically, what’s possible when applications can represent an end-to-end prescriptive model of the business, a system that tells you what should happen or what you should do versus what did happen.
The graphic below, created by George Gilbert, uses Amazon.com as the metaphor for the future. The difference is that this vision is enabled by technology that scales horizontally and is available to most organizations. We’ve talked about “Uber for all.” Here we’re talking about Amazon.com for all.
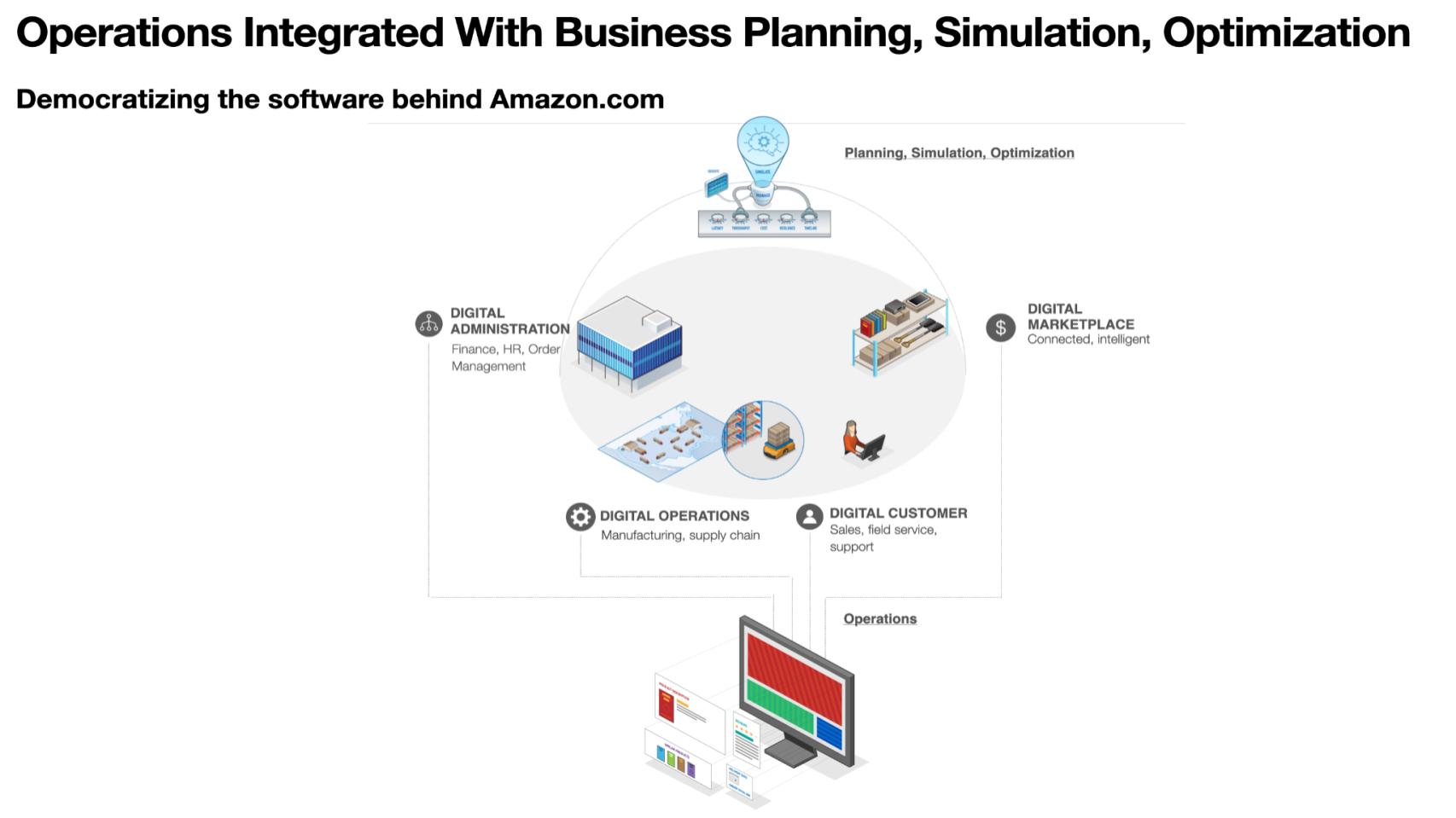
The graphic describes in more detail what Aref was starting to talk about with the Blue Yonder scenarios. But in the past, our enterprise applications were operational in nature mainly. They tracked what happened in the past. The big advances over decades were trying to integrate processes across functions and divisions and even globally. What we were talking about in the future is that not only are we integrating the processes, but we’re integrating predictive and prescriptive models along with the planning, simulation and optimization that might inform those models so that it works across functions.
The technical term is “fan out” so that you can look at it from different angles even if you didn’t originally forecast or plan from that angle. In other words, the model fills that out.
Legacy packaged applications did so much work to integrate all these processes. We wanted to understand Aref’s point of view on where they fit in a world where you start layering a prescriptive model on top of them and they become part of this bigger model.
Below, we summarize Aref’s thoughts on the gradual transition from traditional application-centric models to more data-centric architectures, acknowledging the challenges and opportunities in this shift.
Aref sheds light on the evolving landscape of application development, moving from traditional, code-embedded semantics to more accessible, data-centric, declarative models. He highlights the strategic investments being made in Silicon Valley and elsewhere to address these challenges, pointing toward a future where analytics and business semantics are more integrated and user-friendly.
The transition to data-centric architectures in application development marks a significant shift in the industry, aiming to transform business semantics from obscure code to accessible, relational models that empower business users with more autonomy and analytical power.
Although this transition won’t happen overnight, the bubbling up of trends that we’ve been highlighting, including what we call the sixth data platform, data mesh, data fabric and the end-to-end intelligent enterprise all underscore changing customer needs. In this future vision, elements of a business are represented digitally and in near-real time.
It won’t happen tomorrow and will evolve over a decade or more. As well, like flying a plane on instrument flight rules, customers will have to gain confidence in these systems, not only rationalizing nonintuitive recommendations but trusting that governance and privacy are integral to the system. Regardless of the challenges, the business value impact of unifying intelligence across disparate systems will be enormous.
Do you agree?
How do you see the future of intelligent data apps evolving? How long will it take? What are the missing pieces and which companies are best positioned to deliver?
Thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight, who help us keep our community informed and get the word out, and to Rob Hof, our editor in chief at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com, DM @dvellante on Twitter and comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail. Note: ETR is a separate company from theCUBE Research and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai or research@siliconangle.com.
Here’s the full video analysis:
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.





