BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
In June, we put forth our scenario about “Uber for all.” We believe a new breed of intelligent data apps is emerging and we used Uber Technologies Inc. as an example where data about people, places and things is brought together in a data-coherent, realtime system.
The premise is that increasingly, organizations are going to want a digital representation of their business with incoming data informing the state of that business and then taking actions in real time. We’re envisioning Uber-like data apps that every company can access via commercial and open-source software. In our view, this represents the evolution of data apps for the masses – those that don’t have 2,000 Uber software engineers at their disposal.
In essence, the future of data apps can be summarized by the following two points: 1) A coherent, real-time digital representation of a business end-to-end; 2) An enterprise-wide set of digital twins that can orchestrate activities in real-time.
In this special Breaking Analysis, we sat down with friend of theCUBE, entrepreneur, investor and software executive Bob Muglia. Bob formerly worked at Microsoft, was the CEO of Snowflake and is a visionary trend spotter.
Bob’s new book is The Datapreneurs:

Dave: Tell us, why did you write this book?
Bob: Well, I thought there was something that I had to say and it’d be helpful for people to hear.
I was very fortunate to have a perspective of watching the data industry mature over a 40-year period, if you go all the way back.
I’ve watched what’s happened in this industry and how the people that have been involved have really made such a difference. We sort of see the AI world we’re in today and the incredible things you can do. People think it just sort of came about all at once.
In some senses it certainly does seem like it did that. But there’s a long history that sits behind that. I thought it’d be useful for people to hear that story and understand how we got to where we are. I also wanted to give some idea where we’re going in the future.

Some of the salient attributes of today’s modern data stack are shown below:
We want to dig into today’s data apps and the so-called modern data stack.
You’ve got ELT pipelines with modern lakehouses and tools such as dbt and 5Tran exposing metrics through APIs. We frequently use Databricks and Snowflake as reference examples. You’ve also got BigQuery as an extremely capable cloud native data platform. We recently went to Google Cloud Next and it was of course heavily data- and AI-centric. Azure Fabric is a new and interesting entrant into the market. AWS’ bespoke set of data tools are also widely adopted. And you’ve got the BI layer on top of these platforms.

Dave: Bob, how would you describe today’s modern data platforms in terms of the stack and the scope of applications that they support?
Bob: Just as you pointed out, David, there’s really five platforms right now that different vendors are building. They are all viable choices for people to build a modern data solution on top of.
I think the characteristics of all of them is that they all leverage the cloud for full scale. They can support data of multiple types. Now we’re beginning to see in addition to structured and semistructured data, all the things that people tend to call unstructured data – video, audio, files – which I think of as complex data. There’s clearly structure to that data. It’s just complex compared to other data structures. They’re all working with these different types of data. I think a lot of problems have been solved. You can finally corral your data in one place and make it available to your organization.
What’s still missing from the modern data stack?
Bob: The platforms are all well situated to be able to add those capabilities and augment what they can do. There’s still quite a few issues in the modern data stack that are unresolved. These are the things that I’ve been focusing on really more than anything else:
There’s still quite a few issues in the modern data stack that are unresolved.
Dave:How should we think about the requirements of the new modern data platform?
George: Listening to Bob there are certain requirements, including:
Bob, why don’t you tell us about that tradeoff?
Bob:
I think what’s happening right now is that the data lakes are maturing. In the next 12 to 18 months we’re going to start to see what I’m going to call the maturation of the first generation of the data lakes.
And I think all the vendors are going to move to that sort of architecture where there are two views on data. These data lakes provide two different views. You have a file view of data and you have a table view of data.
And some of the challenges we have right now are making sure that those things are coherent – that there’s consistent governance across both of those things. And as data is added, the transaction consistency model needs to be coherent.
That consistency model will increase in importance as this data is used more for things beyond just business analytics. It will begin to be used to actually operationalize systems through data applications.
That’s where the consistency model becomes progressively more important. And in those ways, I think we’re still in very immature stages in the data lake part of the world. That architecture of using the underlying file system as the foundation with layers like Iceberg or Delta on top provides a foundation to work with the multiple types of data.
One of the big challenges today is that two different formats of Delta and Iceberg and potentially Hudi as a third format. But the fact that we have a potential Beta versus VHS situation is very concerning and problematic to me because what it means is that customers, when they’re choosing their data lake, they’re locking themselves into a format and in some senses they’re locking themselves into the set of vendors that operate on that.
That’s just something to be very thoughtful about. And I hope that the industry works in the next 18 months or so to reconcile those differences because there’s no reason for them. They exist only because of the lineage of the technology, not because there’s a need for there to be different solutions.
The fact that we have a potential Beta versus VHS situation is very concerning and problematic to me because what it means is that customers, when they’re choosing their data lake, they’re locking themselves into a format and in some senses they’re locking themselves into the set of vendors that operate on that.
Dave: What do you think about new types of operational databases?
Bob:
First let’s separate what I was talking about before when we were talking about the modern data stack. That is the part of the data platform that is on the analytics side. The data lake or the data warehouse is the historical system of record for the business.
There’s another set of applications that are much more oriented towards working with people on an interactive basis that are operational. These are applications that work with data in its current state, the current state of applications and the things that are going on.
Now in today’s modern IT data centers every company has many of these operational applications that run their business. And more and more, those applications are software-as-a-service applications provided by third parties.
You have very little control over that SaaS application and what it does. You are able to typically get the data out and, and put it into a pipeline and leverage tools like Fivetran and move it into your data lake or data warehouse, your historical system of record.
But those systems are totally different now in talking about business applications that are operational applications that work with people. The standard for database that people have used for 40 years really is a SQL database.
And there’s a lot of really good reason why people have used SQL as a choice for that (type of application) in particular. It provides the flexibility that the relational model provides together with a very well understood consistency model that works well for applications that require debit credit style transactions. So there’s that whole world that’s existed. And the thing that’s most interesting about that world is that you work with tables and that’s the data structure that SQL was designed or optimized to work with.
It’s been extended to work with semi-structured data, but it’s somewhat awkward to do that. And, and it’s fairly rarely used inside most of these operational applications. It’s more for analysis purposes. Now what happens is that there’s classes of applications that model does not work well for. We ran head into it at Microsoft when I was running the server group and we were trying to move the Exchange product onto SQL server. There were multiple attempts at Microsoft to move both Exchange and Outlook to SQL server. And they all failed.
There were multiple attempts at Microsoft to move both Exchange and Outlook to SQL server. And they all failed.
Dave: What are the limitations of today’s NoSQL operational databases and a potential next-generation solution?
Bob:
The challenge with NoSQL document-oriented databases traditionally is that they couldn’t manage transactional consistency across collections of documents the way a SQL DBMS could do the same across tables.
Fauna solves that problem by marrying the flexibility of a NoSQL document database with the transactional consistency of SQL DBMSs but with cloud-scale distributed transactions.
They failed because the data model inside SQL is a table. It’s very static in its nature. It has to be predeclared. If you look at a chat session or a mail message, they’re very dynamic in the properties they have, how many attachments they’ve got, et cetera. These things can change on an individual item basis. So the data model doesn’t fit with this structured table of SQL.
That’s why the NoSQL databases emerged 12, 15 years ago to handle these sets of issues. And they work quite well. In fact, for applications that are highly dynamic in particular, most of them use an eventual consistency model. This is appropriate for something like email where you can operate offline and you want to have multi-master reconciliation and eventually have things come together.
But that’s very different than a debit-credit transaction where you want to make sure both parts of that are done or neither of them is done. The consistency model of today’s document and NoSQL databases is by and large problematic for this style of applications. Very, very few, in fact, I don’t think any of the major document databases support a transaction between what they would call collections.
In a document database instead of storing things in a table, you store it as a semistructured document where each level of the tree can have independent properties. And those are very dynamic in those databases. The unit of consistency is typically a document and those are maintained consistently. But if you have documents in multiple collections, which is similar to what you would have in tables and in a relational join or a relational transaction, you can’t really support that.
What Fauna has done is it’s tried to take the best capabilities of every modern operational database being a serverless database, providing it as as an API supporting full global consistency, allowing you to have transactions that span the globe and be totally consistent and be placed really anywhere you want it.
It also uses the data model of semi-structured documents to support the application. But it does does so in a way that is fully relational. So it has the ability to do joins between documents and joins between collections and it also has the ability to do transactions between collections. So it brings together the best attributes of a relational SQL database and the transactional consistency with the data model that people tend to want to work with in operational apps. I mean if you look, operational apps are written in languages like JavaScript, Java, Python, other applications, they’re all object-oriented.
The native memory model of those are embedded objects, which when serialized looks like a document. In fact, JavaScript serializes exactly into a JSON document. And that model is very coherent for applications and it’s very different than what people work with in SQL, which is typically a third normal form.
And the object relational mappers (ORM), I just wrote a blog on this, it just appeared today on the Fauna website. If anyone’s interested, you can look under the resources and see a blog where I talk about this. It’s called “Relational is more than SQL.” And I talk about this primarily from the operational database perspective.
But then I also mentioned it from the analytics perspective because we’re seeing the same issues in analytics where effectively the table, the structured data that SQL wants to work with while appropriate for many, many things, many, many things. I always say if I wanted to build a new ERP system, I would use a SQL database underneath that for the general ledger. But I might not use it for the marketing system or for the billing system where you want much more flexibility in the data model. The (potential) dynamism is very interesting.
I always say if I wanted to build a new ERP system, I would use a SQL database underneath that for the general ledger. But I might not use it for the marketing system or for the billing system where you want much more flexibility in the data model.
George:
Evolution in how to bridge the gap between operational applications (real-time system of record) and the modern data stack (historical system of record)
Let me key off that because what you’re describing is an evolution on the operational database foundation that feeds the modern data stack. But let me try and separate the concerns.
Before, we had these little databases that belonged to each microservice. So you really had (data) silos. The coherence in the data model had to come on the analytic data side in the modern data stack – in the lakehouse.
What you’re describing is that you could at least have a coherent system of record across all the different microservices. They could share one Google Spanner-like realtime system of truth only. (Only in the Fauna model) it’s got the more flexible data model. It’s also got a better transaction model so the application logic can be more stateless. And it’s not connection based, which is really important when you talk about those serverless applications.
And so then let’s talk about the other limitations that still remain.
You’ve got this brittle pipeline. Even if you have this coherent system of record that’s real time, you still have to move that into what you call the historical system of truth on the modern data platform. Now those pipelines that move that data is still brittle. Any evolution on one side kind of breaks the other side. We’ll talk about potential solutions to that. But that’s one known limitation.
Bob:
Using a next-generation operational database like Fauna would make it much easier to evolve operational applications on the upstream side and data applications on the downstream side
Let me stop on that point for a second. Because, yeah, I do think there’s a point here. So when your operational system is structured data and the result of what you’re trying to move across the pipeline is a structured schema, it tends to be highly brittle. But if you’re operating in a system that supports dynamic properties, it is actually straightforward to build the pipeline. The pipeline can sense when a new property has been raised and raise that and indicate to the downstream applications that there’s a new property. It can replicate that property because the output is no longer a table. It’s a semi-structured document. And so that semi-structured document, if you simply add a property, it does not break the existing things.
What it does is it says there’s something here you’re not making use of. So it’s far better than breakage. And the fact that it’s dynamic because you operate in a world where in the case of Fauna you can add this dynamic property in the downstream side.
It would be manifested in the SQL database as a JSON object, which typically is dynamic inside these SQL systems. And then they would typically flatten that (data structure). I mean, almost always the first thing you do with JSON for analytics is flatten it into some form of a table. Now that flattening would not see the new property. But it wouldn’t break either.
George: OK. Big difference.
Bob: Big difference.
George: OK, that’s helpful. And let’s talk about how we might add technology that makes it so that the consuming side actually might understand some of the additions.
Bob:
Fivetran already has technology that captures and catalogs evolution in the upstream databases
Well, FiveTran has already taken that step because it will populate a catalog of properties. So if it sees a new property, it’ll populate whatever catalog you want. And so the implementation, it’s actually not hard to do this. The mechanisms are actually kind of already in place. What’s been missing is the flexibility in particular of the (existing NoSQL) source databases.
And this is not going to fix the million applications that exist today that don’t work this way. It’s new applications that will benefit from this.
And that’s going to take some time to develop that base. And it’s not going to be rewrites. No. Or maybe it’s maybe some of that. It’s going to be the new stuff.
Salesforce not going to get rewritten tomorrow on this. They’ve been trying to rewrite that thing for 10 years. It keeps getting bigger.

Dave: How will the modern data stack evolve, especially now that AI is driving such change?
Bob: On the modern data stack, the emergence of the relational knowledge graph will enable much richer applications:
Well, first of all, I think that we’ve matured. I think that the data stack has matured in a very fundamental way in working with structured and semistructured data. And it’s actually become pretty effective. It could be better, but it’s quite good.
And the biggest area that I would still give us maybe a C grade on is the simplicity of governance of this solution. Governance is to me still the outstanding issue that needs to be addressed more by the industry. And that problem is only exacerbated by the appearance of these data lakes where you have a table view and a file view. And you need to keep those consistent and properly governed with only the right access to data. So those are some of the concerns I have today.
But the modern data stack is very good at working with structured data. These modern SQL databases, whether it’s Snowflake or BigQuery or Azure Fabric. They’re good at slicing and dicing data of all sorts of sizes. And they’ve become effectively a very good kitchen tool to use as you’re preparing your data meal.
And I don’t think they’re going to go away. they’re foundational and they’re going to be there for a decade or two decades, a long, long time.
What’s obvious to people though is that there’s a lack of semantic information about the data. And even more fundamentally, there’s no semantic information or very little information about the business and the business rules themselves. And that is to me, the big missing piece of the database. It’s also very directly related to the governance problem.
Governance suffers from the fact that we don’t currently have information about our data stored within the modern data stack in a way that’s usable.
And here the real challenge is that, again, I keep coming back to the shape of data. You know, we’re so used to working with tables and tables are very good things. They’re very functional, you can use them for a lot of things. But they’re not good for everything.
And as I pointed out earlier, there is, there are attributes about operational databases whereby you can work with semi-structured document data models. You can get improvement in the case of analytics in particular to try and work with semantics associated with it. You just can’t store these semantics in tables. It’s just not of an effective structure. You need something much more granular. And that’s where this concept of a knowledge graph comes in.
The idea that you can create a graph of data and represent the data or the business or whatever. The truth is you could represent anything effectively in a knowledge graph and you would represent that as nodes with properties and then relationships associated with it.
And what you’ve discovered is that they’re very, very complex data structures. They’re much, much too complex to handle in a SQL database. And so I’ve been working with the team at Relational.ai for a little while.
They’re building what I think will probably be the world’s first relational knowledge graph. And that leverages the underlying relational mathematics that go beyond what SQL can do to be able to work with data of any shape.
And in particular the way they actually structure data. Where fauna structures data as a document, because that’s the natural data model for operational applications.
Relational.ai actually puts data in what’s typically called sixth normal form or what we now think of as graph normal form. It means it’s the most highly normalized you can possibly make data so that you can work with it and slice it, dice it literally any which way. And relational mathematics provides incredible power to do that, including power to do recursive queries where you’re going through levels of hierarchy and things like that.
And that’s all possible to do. But it requires a whole new set of relational algorithms and they’ve been under development. The team’s working hard. We have expectations that we’ll be out next year with a great product.
George: Do we need richer databases to solve more advanced governance problems?
Bob, let me follow up on that. Let’s put that in the context of the limitations of today’s data platform and what we need to support the intelligent data apps of tomorrow.
So you’ve talked about limitations on governance. Databricks Unity (catalog) has made a big splash about heterogeneous data governance. And not just data, but all the analytic data artifacts. But one limitation is that you can’t represent permissions policy that might require deeply nested recursive queries.
Bob: Permissions is just one example where you need a richer graph database to support it.
Every permission actually requires that. The problem is the role. If you look at the way roles are structured, groups are structured, it’s a hierarchical structure, which means it requires a recursive model. This is the challenge, right?
I think it’s great that Databricks is doing the Unity catalog. I saw that announcement and thought that was a good thing, but it’s just a step. It’s just a step in the direction they suffer from the same challenge that everyone else suffers from, which is we don’t have an effective way of representing this data model as we sit here in 2023.
I think it’s great that Databricks is doing the Unity catalog. I saw that announcement and thought that was a good thing, but it’s just a step….[but] they suffer from the same challenge that everyone else suffers from, which is we don’t have an effective way of representing this data model as we sit here in 2023.
George: So how would a richer graph database transform applications by making it easier for mere mortals to build Uber-type applications?
I’m trying to find the limitations of today’s approaches. Also that you can’t build the shared semantics that then all new data apps would use for building an Uber-like app. There, where any object like a fare price or a rider or a driver needs to be calling on any other app object.
So maybe tie that into why today’s products can’t support that. But explain how once we have that richer foundation, how that would transform application development.
Bob:
Relational knowledge graphs will change everything. They combine the power of the relational model with the ability to model every part of a business, not just the data.
It changes everything. When we have an economical, usable relational knowledge graph that takes the power of the relational mathematics and applies it to data of any shape and size, we’ll be able to model business. For the first time we will be able to actually create a digital twin of the business.
Think about any business. Think about your business that you’re in and the business that you’re a part of. And think about all of the attributes that it takes to run that business. What are the rules? How is the pricing done? All of those attributes, where do those attributes exist? Where does the knowledge of that exist? It exists inside applications, many of which are SaaS applications as we described earlier. So you don’t even control it. It’s somewhat opaque.
That (business) logic in most cases it exists inside programs that maybe you wrote. It exists inside SQL queries and BI tools. It exists in Slack messages, whiteboards, people’s heads, and documents.
Documents become very interesting because a lot of this stuff is written down. It turns out because there are a lot of instructions for people. I think one of the realizations that I have come to this year is that the root of the enterprise knowledge graph is the documentation that’s written in human language. We’ll just say English for the moment, but it could be any native human language. And that is where most of the understanding of the business is. What we want to do is translate that informal written set of documents into formalized rules that can be put into a database in the form of these knowledge graphs. That will describe exactly what the business is supposed to be doing.
Eventually it is possible for those rules to be fully executable and actually run aspects of the business within the database and the knowledge graph because knowledge graphs, relational knowledge graphs, have the ability to execute business logic. But realistically, in today’s world where we have dozens of existing systems, we’re not gonna replace those things overnight.
So I think what we’ll wind up doing is defining what we want it to be. And that will become a management tool to ensure that all of the components in the organization are operating with the desired behavior that you have. So you define essentially the desired behavior inside the knowledge graph and the semantic model. And you know, a system, a governance system will ensure that every part of the organization, the system is actually operating consistently with that. For example, there aren’t missing permissions or something like that.
Eventually it is possible for those rules to be fully executable and actually run aspects of the business within the database and the knowledge graph because relational knowledge graphs, have the ability to execute business logic.
Dave: How would a relational knowledge graph simplify the way an end-user interacts with applications?
I was thinking of where those existing operational systems would feed the knowledge graph. Then I could interact with that knowledge graph maybe with a natural language interface to ask a questions. Today to get answers I have to hunt and peck for answers because they’re in Slack or it’s in Salesforce or it’s in somebody’s head or it’s in a Google doc. How do you see these emerging approaches supporting that vision and what exactly do these new apps look like?
Bob:
What you just said, Dave, that once you have this knowledge in a centralized place, it becomes a repository that people can use to understand the business.
And now that we really are seeing the breakthrough of the large language models, it’s understandable how you could use human language and ask a question and have a model respond.
But you know that in the world of language models and incorporating those models into enterprises, the in-vogue thing to do is is called retrieval augmented generation (RAG). You take corpuses of data, typically one approach that’s being widely used right now is to take a tool like Pinecone and vectorize that data in a vector database. Then you have a semantic representation of it. When a question is asked, you can query that source of knowledge and then feed that into the LLM for the answer.
Well, the other major source, in addition to vectorized data, which is just human language written in a form that’s turned into semantic semantic vectors.
In addition to that, the other place where these models will be getting augmentation is from knowledge graphs. And in a way it’s the first place that happened. Google has been doing this to some extent for years in search. Google has a knowledge graph that it shows you whenever you ask about a company or a place. What it shows you is the knowledge graph of what it knows about that place. And now what these search engines are doing is they’re incorporating that knowledge into their language models. And so that can be used to answer questions in a more accurate way.
…the in-vogue thing to do is is called retrieval augmented generation. You take corpuses of data, typically one approach that’s being widely used right now is to take a tool like Pinecone and vectorize that data in a vector database. Then you have a semantic representation of it.
Dave: TheCUBE built an application that uses LLMs to synthesize answers based on 35,000 interviews from 10 years in production. So, Bob, the reason I was asking about Mongo is we talk about new operational databases and document databases. But we built theCubeai, which is in private beta. So we took all 35,000 interviews and videos that we’ve done over the last 10 years. We’ve transcribed them and built retrieval augmented generation system that uses Mongo and Milvus, an open-source vector database. You can ask it a question. It’ll give you an answer. It’ll actually give you clips of where that answer came from. It’ll actually generate clips automatically.
Bob: Is that working pretty well?
Dave: CUBEai.com can summarize answers about what a guest said about a topic or what all guests said about a topic. It’s working. It’s really interesting. You go to the Cubeai.com. It’s in private beta. It does hallucinate. Like if you ask it, what does Bob Muglia think about the future of data apps? It’ll give you an answer and it’ll give you clips. It’ll maybe say some things that you didn’t say, but it’s a really well-written answer. And so we’re tuning that.
Bob: You can tune that down.
Dave: Absolutely. But we built this app very quickly and it was relatively inexpensive to do. It just blows your mind what’s possible.
Dave: TheCubeai.com generates a summary of what Bob would say about the future of data apps. I asked the Cubeai, “what does Bob Muglia think about the future of data apps?”
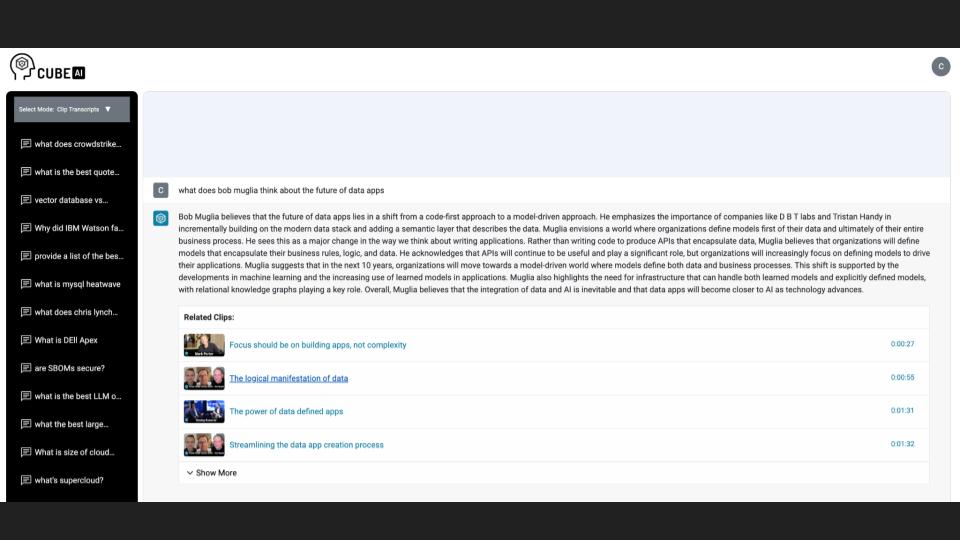
“Bob Muglia believes that the future of data apps lies in a shift from a code first approach to a model-driven approach. He emphasizes the importance of companies like dbt labs in incrementally building on the modern data stack and adding a semantic layer that describes the data.
“Muglia envisions a world where organizations define models first of their data and ultimately of their entire business. He sees this as a major change in the way we think about writing applications rather than writing code to produce APIs that encapsulate data. He believes that organizations will define models that encapsulate their business rules, logic and data.
“He acknowledges APIs will continue to be useful and play a significant role. But organizations will increasingly focus on defining models to drive their applications.
“He suggests in the next 10 years, organizations will move toward this model driven world where models define both data and business process. This shift is supported by the developments in machine learning and the increased use of learning models and applications.
“He also highlights the need for infrastructure that can handle both these learned models and explicitly defined models with relational knowledge graphs playing a key role overall. He believes that the integration of data and AI is inevitable and that data apps will become closer as AI technology advances.”
Muglia envisions a world where organizations define models first of their data and ultimately of their entire business. He sees this as a major change in the way we think about writing applications rather than writing code to produce APIs that encapsulate data. He believes that organizations will define models that encapsulate their business rules, logic and data.
Bob, How would you rate that?
Bob: I could have said that. I mean, it sounds like I said that and then it sounds like it’s repeating a bunch of things I did say, in fact.
Dave: The really cool thing is it gives you several clips where you’re quoted and references with actual clips and snippets.
Bob: So that’s the cool thing. That’s what these augmented models can do. We see it in the consumer search applications like Bing or Perplexity or Bard. Things like where you have references to the real underlying content, which is incredibly helpful if you want to dive deeper. I mean, it’s a totally different way of working with information. I don’t know about you, but my entire approach to internet search has changed completely this year. Totally different. I ask a model first.
It finds stuff out so much faster. It’s at least as big of a transition as the internet was where you used to go to a library to find this stuff out. I mean, I remember those days.
Bob: The tools around LLMs are advancing really fast. We can now use them with up-to-date information.
That’s what’s sort of exciting. That’s what is really exciting about this new generative AI and what we’ve seen in the last year.
I’m so excited about it because for the first time, there is a way to effectively bottle intelligence, to take the knowledge about a subject and actually put that intelligence inside one of these models.
The tools are still rather crude for doing that. But they’re improving at a very fast pace. It’s a very, very exciting time.
But what is clear is it’s the combination of that intelligence that the model provides together with knowledge in some form that is gonna make these things work really well. I personally have found that I’ve moved. Chat GPT is great.
But I like tools that are much more up to date. I’ve been using Perplexity to answer questions and it’s pretty cool the answers you can get. It’s current. These things are up to date and we’re going to start to see more and more consumer and business-oriented solutions that leverage this technology.
George: Can you use a specialized LLM in conjunction with a business modeled in relational knowledge graph to accelerate building applications?
Well, let me follow up on that. Dave was talking about using a large language model on top of an existing database.
My question is now let’s extend that to a relational knowledge graph that represents a coherent model of the business. Then underneath it organizes the historical system of truth. Now I have two questions.
First, can you use a specialized LLM as a development assistant, a coding co-pilot to help you build these digital twin applications on top of that historical system of truth? Would it accelerate the ability to build these apps?
Bob: A development copilot would greatly accelerate business modeling.
Yes, is the short answer.
And in fact, it’s super-important because one of the learnings we’ve had as we’ve built Relational.ai is that it’s really hard for people to build these digital twins and to think in terms of these semantic layers.
We’ve not really been trained to think that way. Most of us at least have not been trained to do it. The people that are the most trained are the business analysts that are really focusing on understanding the processes associated with a business.
There are people such as consultants that tend to think this way, but it’s not something that most people learn. So it’s tough for people to kind of get that and I think these language models will be very helpful.
I also do think that we’re going to start to train people differently. I think that we’ll begin in the next few years to, to talk much more about declarative programming so that everybody does it.
People learn imperative programming today where you take one step and you take another. One of the attributes of these knowledge graphs is that you’re not declaring you do this first, you do that. Instead, you declare rules, business rules, and the system determines the order that things happen based on the data that it has. And that’s a very different way of working with things.
I also do think that we’re going to start to train people differently. I think that we’ll begin in the next few years to, to talk much more about declarative programming so that everybody does it.
George: Can LLM copilots help translate the rules a business analyst understands into the declarative business rules Relational.ai understands?
But you said something really important in there, which is the people closest to that mindset of business rules are the business analysts. But there used to be a skills gap between the language they spoke and translating that into code for applications. And the LLM can help map the business rules that a business analyst understands down into a more domain-specific language like Relational.ai or whatever you’re using.
Bob: LLM copilots today are about imperative languages. But we need a shift to a more declarative way of describing things.
I think the LLMs are helping today with imperative languages, too. Yes, I mean, you’ve seen the copilots be effective. The developer copilots are one of the most effective first generation AI solutions. I think we’ll continue to see that. But it is a shift again to move to a much more declarative way of describing things.
George: Bob, let’s talk a little bit about trying to extend today’s data stack to support this new class of applications and what that pathway might look like.
Companies might start marking up the semantics of their data with BI metrics layers as an easy first step.
Can that support growing into full application semantics? And if there might be limitations in that growth path, how might customers make that first step and then transition to something broader if necessary?
Bob: Well, it is a good first step and people should do it.
People have been doing it in BI layers for a very long time. This is nothing new. This was one of the big things in Cognos or Business Objects years ago. I think they were talking about this ages and ages ago. But it is a good step.
I think that getting to those full semantics is going to require the (relational knowledge graph) database to underlie it.
This week I talked to two or three different really small companies that are looking at collecting data semantics. I asked them, where are you storing it? And they tell me they’re storing it in a YAML file. And I go, okay, that’s not a bad first place to store it, but it’s not a long-term repository and obviously it’s just not gonna scale.
The problem you have is you can operate it really small scale just working with files. But you eventually have to be able to put these in something where you can work with the data through much more normal relational commands.
I’m just focused on fixing the underlying infrastructure. That’s my thing. I gotta get the infrastructure right.
You know, the whole modern data stack couldn’t exist until Snowflake demonstrated that it was possible to build a system that could work with structured and semi-structured data at any scale. Until we demonstrated using SQL nobody believed it was possible.
This is similar. We need a new generation of technology and databases to be able to move the world forward and we’re just waiting for them to finish. They’re (relational knowledge graphs) very much underway.
The whole modern data stack couldn’t exist until Snowflake demonstrated that it was possible to build a system that could work with structured and semi-structured data at any scale. Until we demonstrated using SQL nobody believed it was possible.
George: Where might today’s companies get into trouble? Like a Databricks or a Snowflake or Microsoft, if they try to start modeling richer semantics than just BI metrics and dimensions? Where do they hit the wall and then what would you layer on top if you had to?
Bob: They hit the wall on complex queries.
You know, interestingly, people are tending to use two types of databases that people to use to store this (graph). In today’s world. They’re using either a graph database like Neo4j or Tiger.
Or they’re trying to use a document database and store it. Because if you think about these properties most closely, although it’s not a hierarchy, it it is a graph. It truly is a graph.
A hierarchy is a subset of a graph essentially. So leveraging documents makes some sense, but here again, they hit the issues of transactional consistency unless they’re using Fauna. And then, you know, query is not that powerful. I mean query is much, much more restricted in these systems.
So that’s where they tend to hit the wall. You know, I keep saying the problem everyone has, the problem that customers have always wanted me to solve, which nobody can solve today, is, you know, Fred Smith was just terminated by the company. He was turned off in Okta or whatever. They turned him off. He has no access before he left. What data did he have access to? It’s very hard to answer that question.
George: That’s on the a governance challenge. Tell us about the expressiveness and the richness of the semantics that you have in BI metrics layers and then where you might have to go beyond what they can do.
Bob: What happens is that if you start modeling, if you start looking at the models of these semantics and the relationships that exist between the data elements, they become a graph. It just becomes a graph very quickly.
And so now you have the question, how are you going to store that graph? And that’s why I say you can use a bespoke graph database like Neo4J and it will work to a point. The challenge that these things have are scale oriented largely because they’re not relational.
They use pointers, essentially. And to scale that becomes very, very difficult. Or people try and use SQL. A lot of people try and do something with Postgres. But you know they hit brick walls with that.
It’s the classic issue you hit with database technology when the technology has not matured. When the relational (knowledge graph) technology is not mature to solve a business problem, people try and solve it with the existing things.
But it is like hitting your head against a brick wall. You know, I remember the way it was in the late seventies, early 1980s when I first entered the, the workforce and we were working with hierarchical and network databases. They were a bear to work with and SQL made everybody’s life so much easier. It will continue to make people’s lives so much easier except for these problems where SQL doesn’t address, like these highly complex relationships such as graph-oriented problems and metadata.
It turns out semantic layers are one of the most interesting problems. There are many other problems, by the way, in business that model as graphs. The chemical industry has a lot of problems that look like this. So a lot of data problems need to be solved by graph that are not management and semantic models. But you know, the one that to me hits everyone is the semantic model.
It turns out semantic layers are one of the most interesting problems.
George: Once we have this semantic foundation and the richly connected data for both the governance services but also the application logic that are shared across all apps. You talked at one point about documents containing the semantics and the rules of a business. What might these end-to-end applications look like when you captured the document flows? Now LLMs can pull the structure out of those documents and they’re part of applications that span what were office workflows but they also have operational capabilities in them. You have this new stack, what can you build?
Bob: I think what you’re going to build first and foremost is the governance and management layers that lets you understand the organization.
And then I think from that, you’re going to begin to derive applications that you can build that are focused on given areas and take on some parts of your business. You have SaaS applications that are running your operations, some bespoke applications. You have this modern data stack that you are deploying or you’ve just deployed. Those aren’t gonna go away. None of that stuff’s going to change. You’re not going to get rid of that stuff tomorrow. That stuff’s in there for a long time.
So what you do is you augment it with systems that focus on solving problems you can’t solve. And that’ll first work on governance. But then I think we’ll begin to use these knowledge graph databases to build data applications themselves.
And you know, we talked about this a little bit before the show, we haven’t had a chance to get into it too much during the discussion. But one of the interesting things is what is the consistency model of the analytic data?
This focus on transactional consistency is incredibly important in data. And it’s particularly important if you want to operationalize that data. If you want to actually take action based on that data. The consistency model can work out itself out if you’re looking historically over time.
This focus on transactional consistency is incredibly important in data. And it’s particularly important if you want to operationalize that data. If you want to actually take action based on that data.
But if you’re looking at data that’s coming in near real time to make decisions what to do, keeping that data consistent is very important. And that’s why understanding the consistency model is critical. An analytic database uses a snapshot level typically of consistency, which means each table is consistent itself, but it it isn’t necessarily consistent between the tables at the same time.
And that’s why some of these systems start talking about using technology like strictly serialized transactions, which is a much easier model to work with in building applications. And today products like Materialize support that as an operational data warehouse. And I think more and more of that’s going to be important.
It turns out that that Relational.ai and what they’re building with a knowledge graph is actually strictly serialized. And that’s very important because those that system will be used to build applications. Having that high level of consistency is very important. So this is something people don’t pay enough attention to and it’s really, really important.
Dave: So, Bob, last question: In thinking about this notion of Uber-for-all that we’ve been putting forth, do you buy that premise? If so, how long do you think it will take to unfold?
Bob: Well, I do in the sense that, “for all” is a big word, right?
Uber is a very complicated SaaS application that has many complicated things frankly that some don’t require. I mean it has complexity that many companies may not require, although certainly many other companies do.
If you look at any kind of transportation industry, et cetera, they have very similar sets of requirements. It’s getting a lot easier to build these things. There are components these still have to stitch together. I think over time more and more will be incorporated into the modern data stack platforms that let people do it (more easily).
In addition to the things we’ve been talking about today, I mentioned earlier before we started that one of the tools that that came out of Uber that, that turns out to be very critical for that style of application is something to support long running transactions.
If you think about what an Uber driver has to do, they’re called to pick up a client, they pick them up, they go through a route, they go through the stages, they finish it. That is thought of in Uber as a long-running transaction.
The tools that Uber developed were open sourced. And now the company that supports that is driving that forward. It’s called Temporal. And they built a system to help support that transaction system. Again, it comes back to consistency levels. Uber understood the importance of transactional consistency, which is why they built the underlying foundation that is ultimately in Temporal today. And you need that level of consistency within your application and database systems. And Uber even went so far as to build these long running transaction systems, which are now available for others to use.
Dave: So not everybody needs that level of capability, but something like that. People, places and things in real time. That digital representation of your business. Is that a decade-long sort of journey or much shorter than that?
Bob: I think it’s much shorter than that. The fact is that the biggest criticism I think everyone has today, and it’s a good criticism, is that the modern data stack has a lot of components to make it successful and you have to buy things from a lot of people over time. Those things will tend to consolidate into the platforms and that will change over the next five years.
But the thing that’s interesting is the pieces are there today by and large, with the exception that I keep coming back to, the knowledge graph, which is still a missing component. The pieces are by and large, there to build these solutions today.
Many thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight, who help us keep our community informed and get the word out, and to Rob Hof, our editor in chief at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com, DM @dvellante on Twitter and comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail. Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
Here’s the full video analysis:
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.